この記事のポイント
- Spark は apt では入りません。公式の
apache/spark:4.0.0イメージか tar.gz を使うのが定石です - 公式イメージの中身は実測で Spark 4.0.0 / Scala 2.13.16 / OpenJDK 17.0.15 / Python 3.10.12(JAR 277個同梱)でした
- Docker で master + worker 2台の standalone クラスタを起動し、実際に分散ジョブ(SparkPi・PySpark集計)を動かせました
- 意外なことに、小さなジョブではクラスタ(10.7秒)より local[*](7.0秒)の方が速いという実測結果が出ました
- Master・Worker・実行中アプリ・History Server の実画面(Web UI)もそのままお見せします
「ビッグデータ処理といえば Spark」とよく聞くものの、いざ Ubuntu に入れようとして apt install spark を叩いて「パッケージが見つかりません」で止まった人は多いはずです。
結論からいうと、Apache Spark は Ubuntu の apt リポジトリには存在しません。公式の Docker イメージか tar.gz を使います。本記事では実際に apache/spark:4.0.0 を Docker で動かし、standalone クラスタを組んで分散ジョブを実行し、所要時間・メモリ・Web UI までをすべて実測した一次データでお見せします。手元で再現できるよう、打ったコマンドと返ってきた出力をセットで載せていきます。
注意
本記事は Ubuntu 24.04 LTS + Docker Engine 20.10.12 環境で、公式イメージ apache/spark:4.0.0(コンテナ内は Spark 4.0.0 / Java 17.0.15)を使って検証しています。Spark はメモリを食うサービスです。後述のとおり待機中でも master+worker で合計約670MiB を使い、実際のジョブではさらに増えます。学習用でも 2GB、データ量が増えるなら 4GB 以上のメモリを見ておいてください。
Apache Sparkとは
Apache Spark は、大量のデータを複数のマシン(または複数コア)に分散して並列処理するためのエンジンです。1台では時間のかかる集計や機械学習の前処理を、クラスタに分けて高速に回すのが得意です。
Spark は大きく次の登場人物で動きます。専門用語が続きますが、後で実画面と対応させるので今は雰囲気でかまいません。
- Driver:あなたのアプリ本体。処理を Stage・Task に分割して指示を出す司令塔役(
spark-submitで起動するプロセス) - Master:standalone クラスタの管理者。どの Worker が空いているかを管理し、リソースを割り当てます
- Worker:各マシンに常駐するプロセス。指示を受けて Executor を起動します
- Executor:実際にデータを処理する JVM プロセス。計算はここで行われます
図にすると次のような流れです。今回 Docker で組んだ master + worker 構成に対応しています。
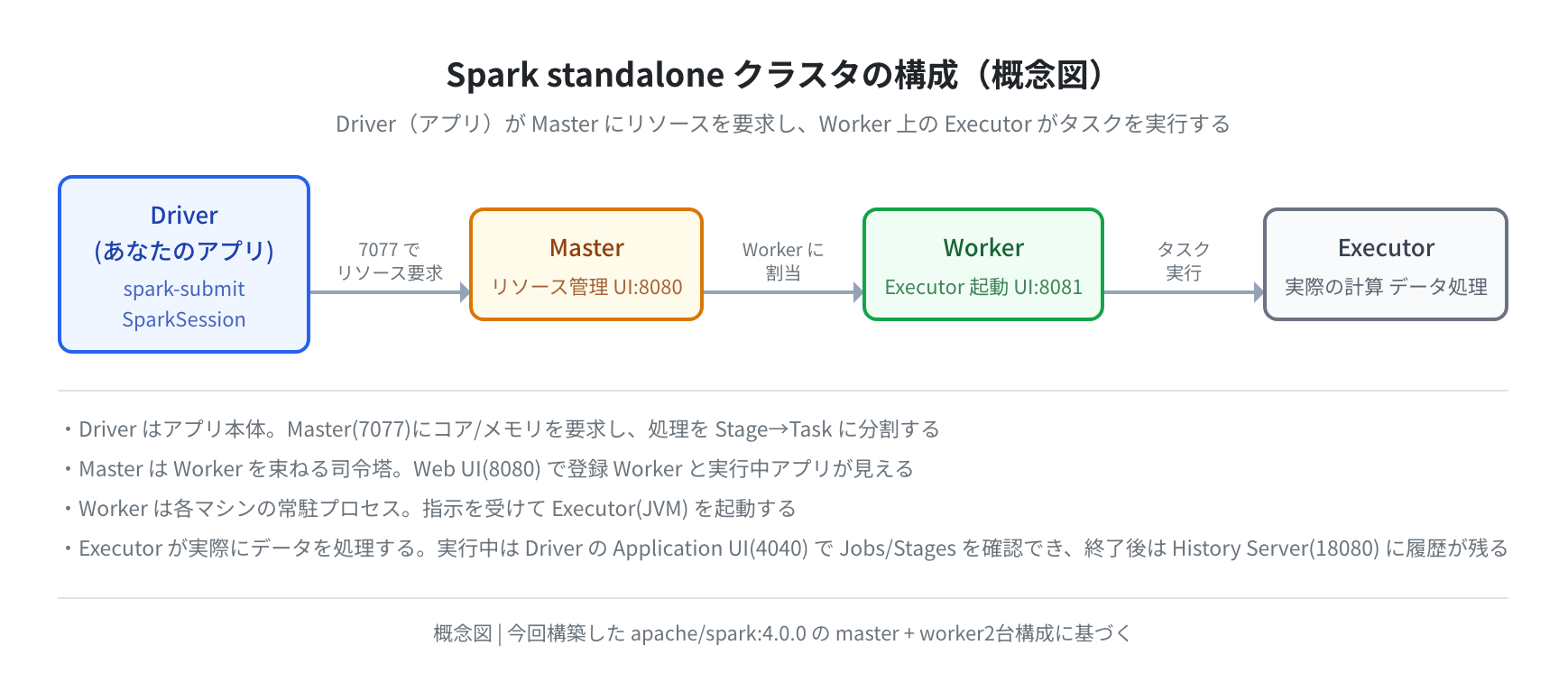
クラスタの管理方式には standalone のほか YARN や Kubernetes もありますが、まず仕組みを理解するなら一番シンプルな standalone から始めるのが分かりやすいです。本記事も standalone で進めます。
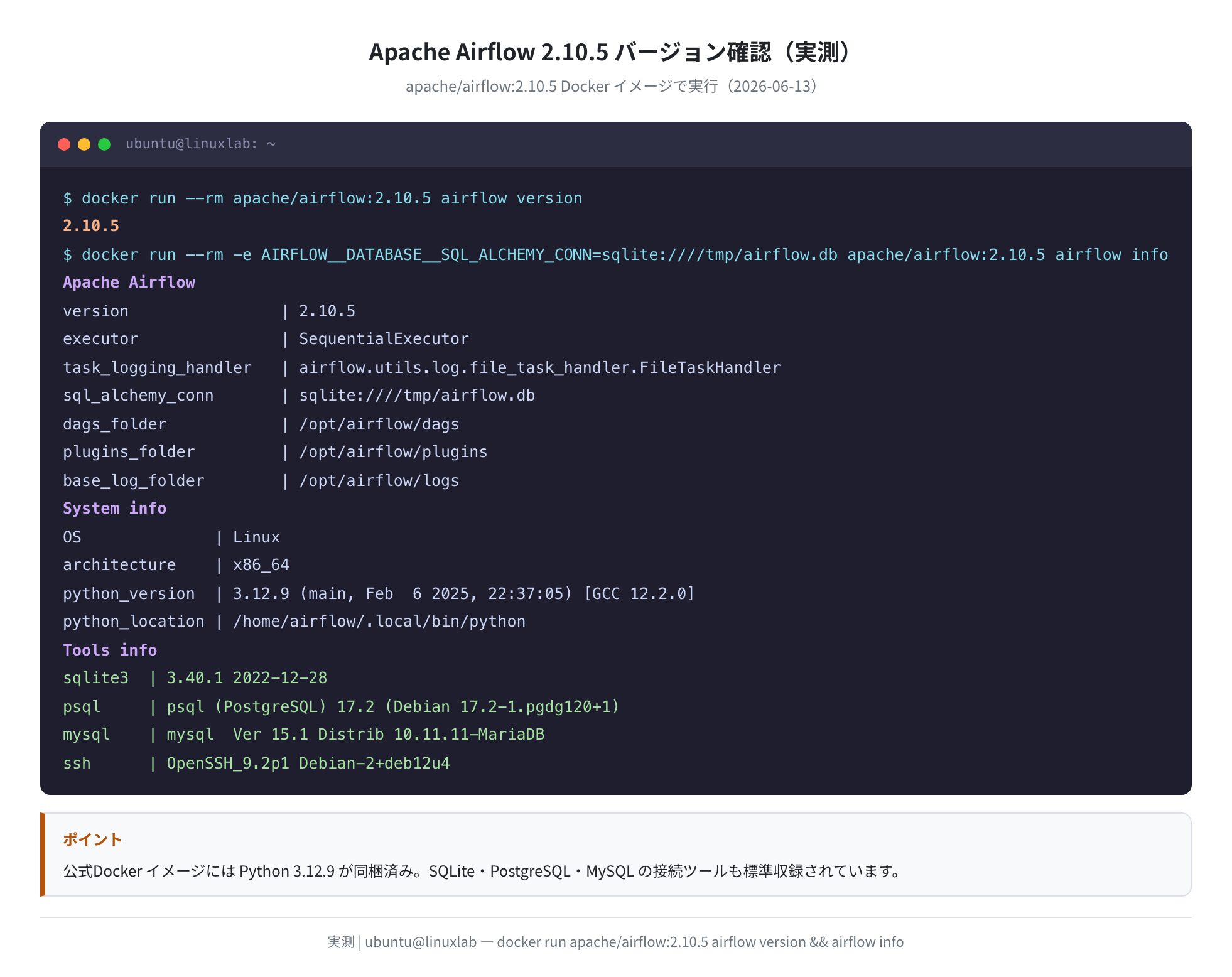
検証環境とSparkのバージョン
今回使った公式イメージ apache/spark:4.0.0 の中身を、実際にコンテナ内でコマンドを叩いて確認しました。Spark だけでなく Scala・Java・Python のバージョンが一度に分かります。
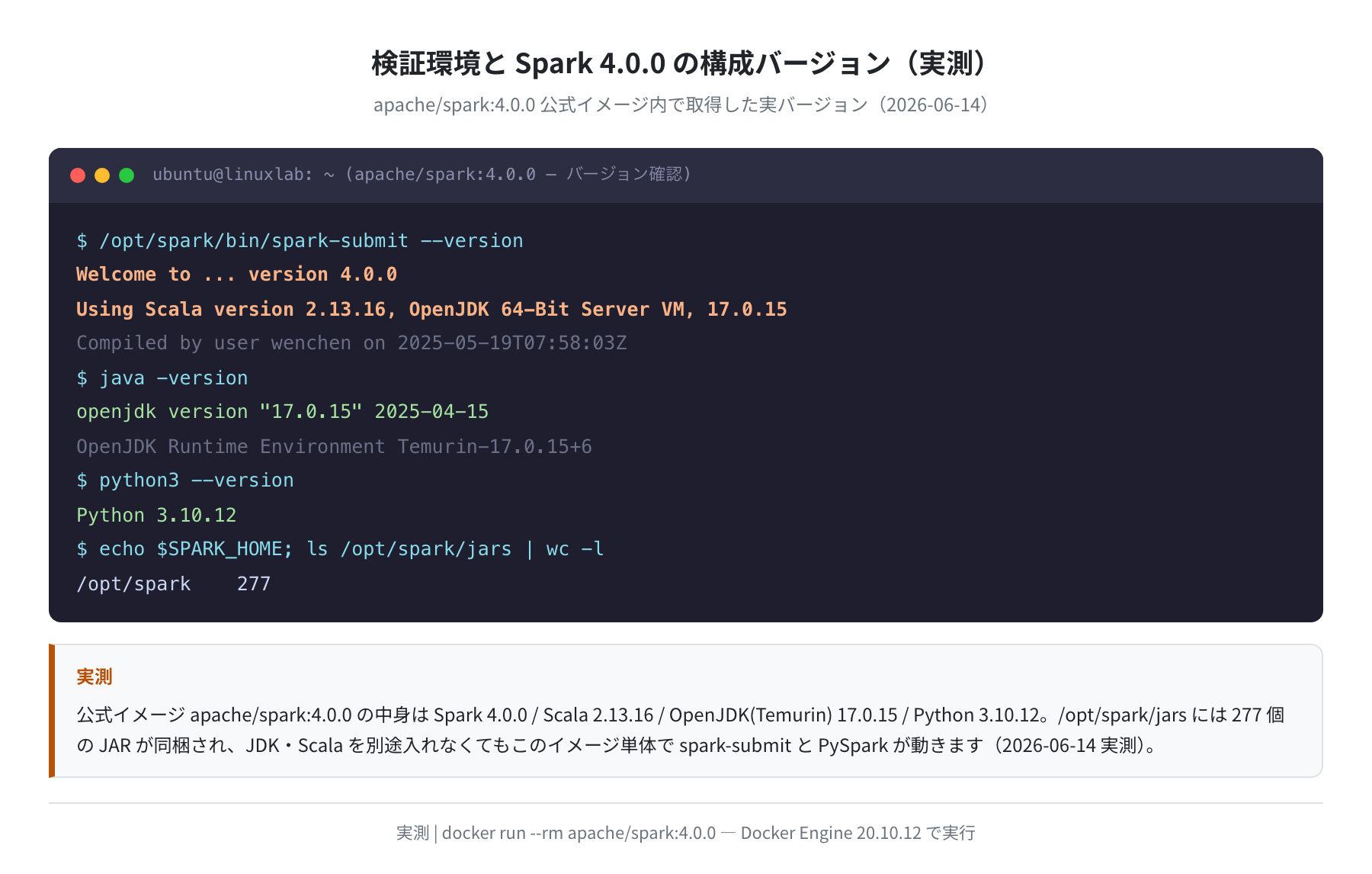
実測の要点をまとめます。spark-submit --version の出力から、Spark 本体は 4.0.0、内部の Scala は 2.13.16 でした。ここは後で「apt の scala は古くて使えない」という話につながる重要ポイントです。
| 項目 | 実測値(apache/spark:4.0.0 内) |
|---|---|
| Spark | 4.0.0(2025-05-19 ビルド) |
| Scala | 2.13.16 |
| Java(JVM) | OpenJDK Temurin 17.0.15 |
| Python(PySpark用) | Python 3.10.12 |
| SPARK_HOME | /opt/spark(同梱JAR 277個) |
注目したいのは、このイメージ1つで Java も Scala も Python も揃っているという点です。/opt/spark/jars には 277 個の JAR が入っていて、JDK や Scala を別途インストールしなくても、このイメージ単体で spark-submit と PySpark が動きます。これが「まず Docker で試す」のが一番ラクな理由です。
なぜ apt install spark では入らないのか
多くの人が最初につまずくのがここです。実際に ubuntu:24.04 のコンテナで apt-cache を叩いて、Spark 関連パッケージの実態を確認しました。
$ apt-cache policy spark apache-spark spark-core
N: Unable to locate package spark
N: Unable to locate package apache-spark
$ apt-cache search ‘^spark’ | head
python3-sparkpost – SparkPost Python API client (Python 3)
# ← これはメール送信APIのクライアント。Sparkとは無関係
このとおり、Apache Spark 本体は Ubuntu の公式リポジトリに存在しません。apt-cache search '^spark' でヒットするのは無関係なメール API(python3-sparkpost)だけです。
では何を apt で入れて、何を別途用意するのか。JDK・Scala・Spark本体の apt での扱いを表にまとめました。
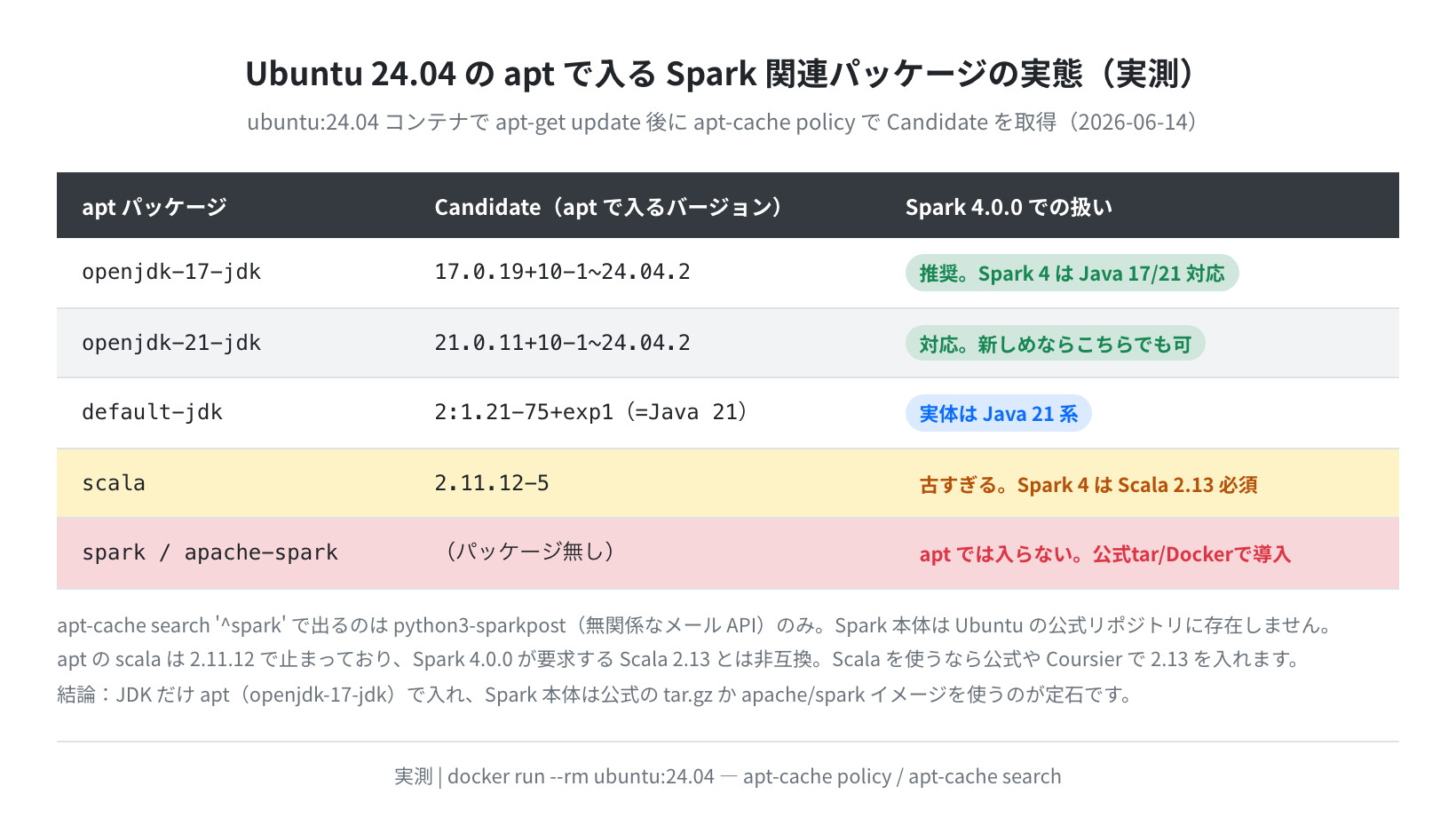
ポイントは2つです。1つめは、Spark の動作に必要な JDK は apt で入ること。openjdk-17-jdk の Candidate は 17.0.19+10-1~24.04.2、openjdk-21-jdk は 21.0.11+10-1~24.04.2 で、どちらも Spark 4 が対応する Java 17/21 です。
2つめが落とし穴で、apt の scala パッケージは 2.11.12 と古すぎる点です。Spark 4.0.0 は Scala 2.13 でビルドされているため、apt の Scala 2.11 とは非互換です。「正直、これは詰まりやすいポイントです」。Scala でアプリを書くなら apt ではなく公式や Coursier で 2.13 を入れます。
結論:何を入れるか
JDK だけ apt install openjdk-17-jdk で入れ、Spark 本体は公式の tar.gz か apache/spark Docker イメージを使うのが定石です。本記事は再現性が高く後片付けもラクな Docker で進めます。
Sparkをインストールする(Docker)
一番手軽なのは公式イメージを docker pull するだけの方法です。Docker さえ入っていれば、JDK も Scala も意識せずに Spark が動きます。Docker 自体の導入はを参照してください。
4.0.0: Pulling from apache/spark
Status: Downloaded newer image for apache/spark:4.0.0
$ docker run –rm apache/spark:4.0.0 /opt/spark/bin/spark-submit –version
version 4.0.0
Using Scala version 2.13.16, OpenJDK 64-Bit Server VM, 17.0.15
これだけで Spark が起動できる状態になりました。spark-shell(Scala)や pyspark(Python)を単体で触るだけならこのまま local モードで使えます。ただ本記事の本題は「分散」なので、次は複数プロセスのクラスタを組みます。
standaloneクラスタを起動する
standalone クラスタは、Master を1つ、Worker を必要な数だけ起動して構成します。今回は Docker ネットワーク上に spark-master と spark-worker1 / spark-worker2(各 1コア・1GB 割当)を立てました。
ハマりどころ:ホスト名にアンダースコアを使わない
検証中、コンテナ名を spark_master のようにアンダースコア入りにすると Worker が Master に登録できず、aliveworkers: 0 のままになりました。Spark(Java)のホスト名解決は RFC に厳密で、アンダースコアを嫌います。spark-master のようにハイフンを使うと一発で Successfully registered with master が出ます。「ここだけは地味にハマります」。
Master を起動したら、ブラウザで Master の Web UI(標準ポート 8080)を開きます。実際の画面がこちらです。
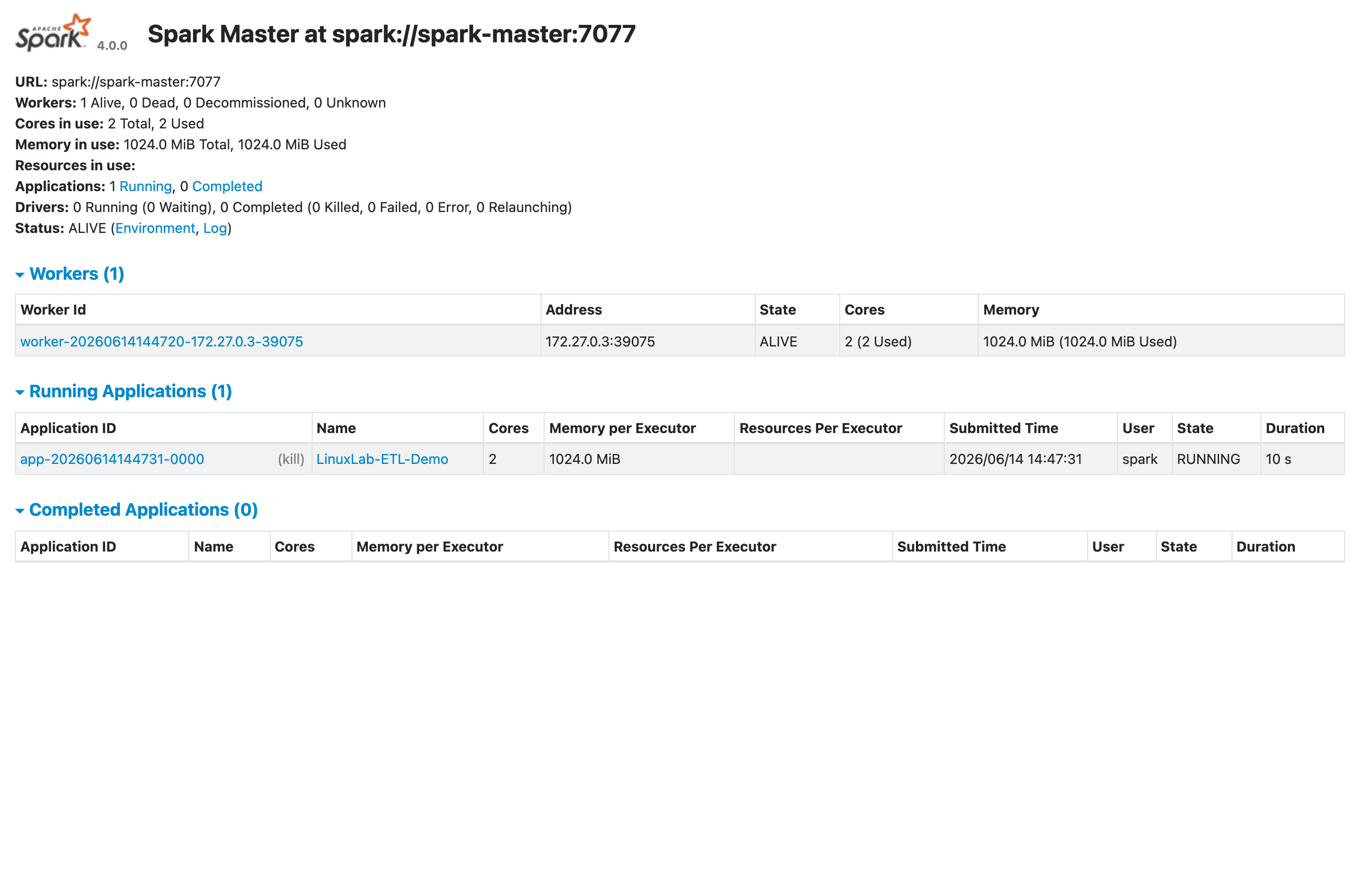
「Spark Master at spark://spark-master:7077」というタイトルの下に、Workers と Cores in use、実行中アプリの一覧が出ています。Worker が登録されると、この画面の Workers 欄に ALIVE として並びます。Master の Web UI を見れば、クラスタの全体状況がひと目で分かるわけです。
Worker 側にも個別の Web UI(標準ポート 8081)があります。こちらは、その Worker 上で動いている Executor を確認できる画面です。
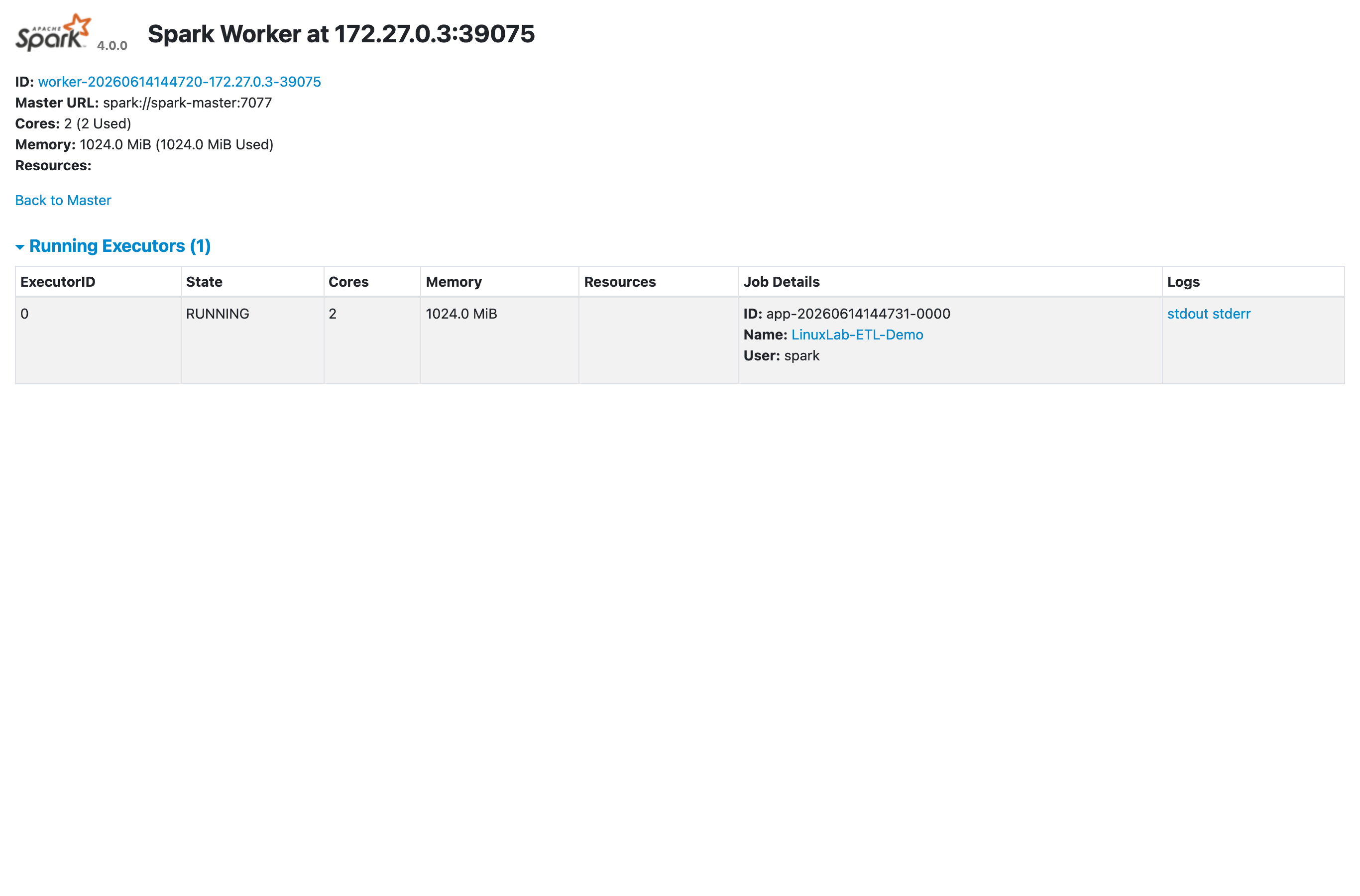
「Spark Worker at 172.27.0.3:39075」と表示され、Master URL: spark://spark-master:7077 に接続済み、Running Executors (1) として ID 0 の Executor が RUNNING(2コア・1024.0 MiB)になっているのが見えます。これがアプリのタスクを実際に処理しているプロセスです。
実際に分散ジョブを動かしてみる
クラスタができたので、spark-submit でジョブを投げます。まずは定番の円周率計算 SparkPi を、同じジョブを2通りの実行方法で動かして所要時間を比べました。
–class org.apache.spark.examples.SparkPi \
/opt/spark/examples/jars/spark-examples_2.13-4.0.0.jar 200
Pi is roughly 3.1417921570896077
# standalone クラスタで実行 … 10.7秒
$ spark-submit –master ‘local[*]’ \
–class org.apache.spark.examples.SparkPi (同じjar) 200
Pi is roughly 3.1409797570489877
# local[*](1コンテナ完結)で実行 … 7.0秒
結果をグラフにしたのがこちらです。
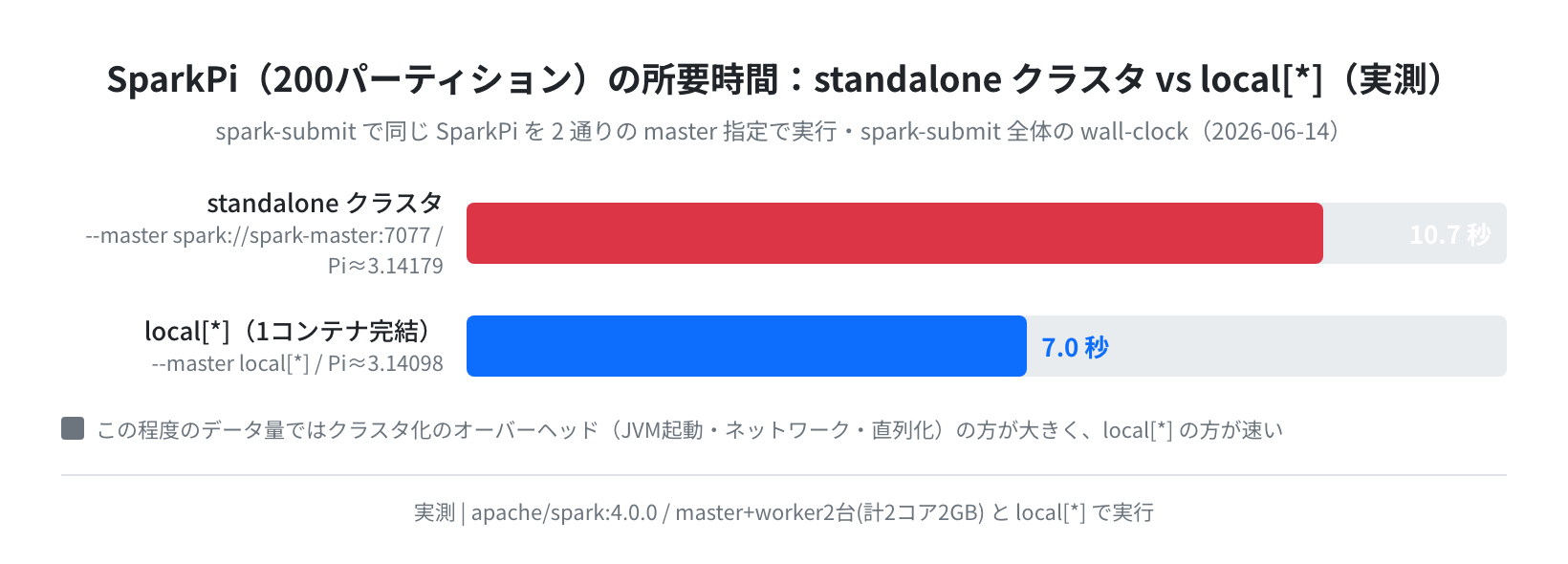
ここで「驚く発見」です。分散したはずのクラスタ(10.7秒)の方が、1コンテナ完結の local[*](7.0秒)より遅いという結果になりました。直感に反しますが、理由ははっきりしています。SparkPi 程度の小さな計算では、処理本体より「クラスタ化のオーバーヘッド」(Executor用JVMの起動・ネットワーク越しのタスク配布・データの直列化)の方が大きいからです。
つまり「分散=速い」は常に正しいわけではありません。Spark が本領を発揮するのは、1台のメモリに乗り切らない / 1台では時間がかかりすぎる大きなデータを扱うときです。小さなデータならむしろ local[*] の方が速くシンプル、というのは最初に知っておくと判断を誤りません。
PySparkでDataFrame集計を動かす
SQL に近い感覚で書ける PySpark の DataFrame でも、クラスタ上で集計を実行しました。リージョン別に QPS を合計する、ありがちな集計です。
region total_qps nodes
tokyo 230 3
osaka 105 2
nagoya 20 1
SPARK_VERSION 4.0.0 / DEFAULT_PARALLELISM 2
tokyo の合計 QPS が 230(3ノード分)と、想定どおりの集計結果が返ってきました。DEFAULT_PARALLELISM 2 は、クラスタの総コア数(worker 2台 × 1コア = 2コア)と一致しています。コア数が並列度の上限になる、という Spark の基本がここに現れています。
ジョブを実行している間、Driver には Application Web UI(標準ポート 4040)が立ち上がります。Jobs や Stages の進捗をリアルタイムに追える、Spark で一番よく見る画面です。
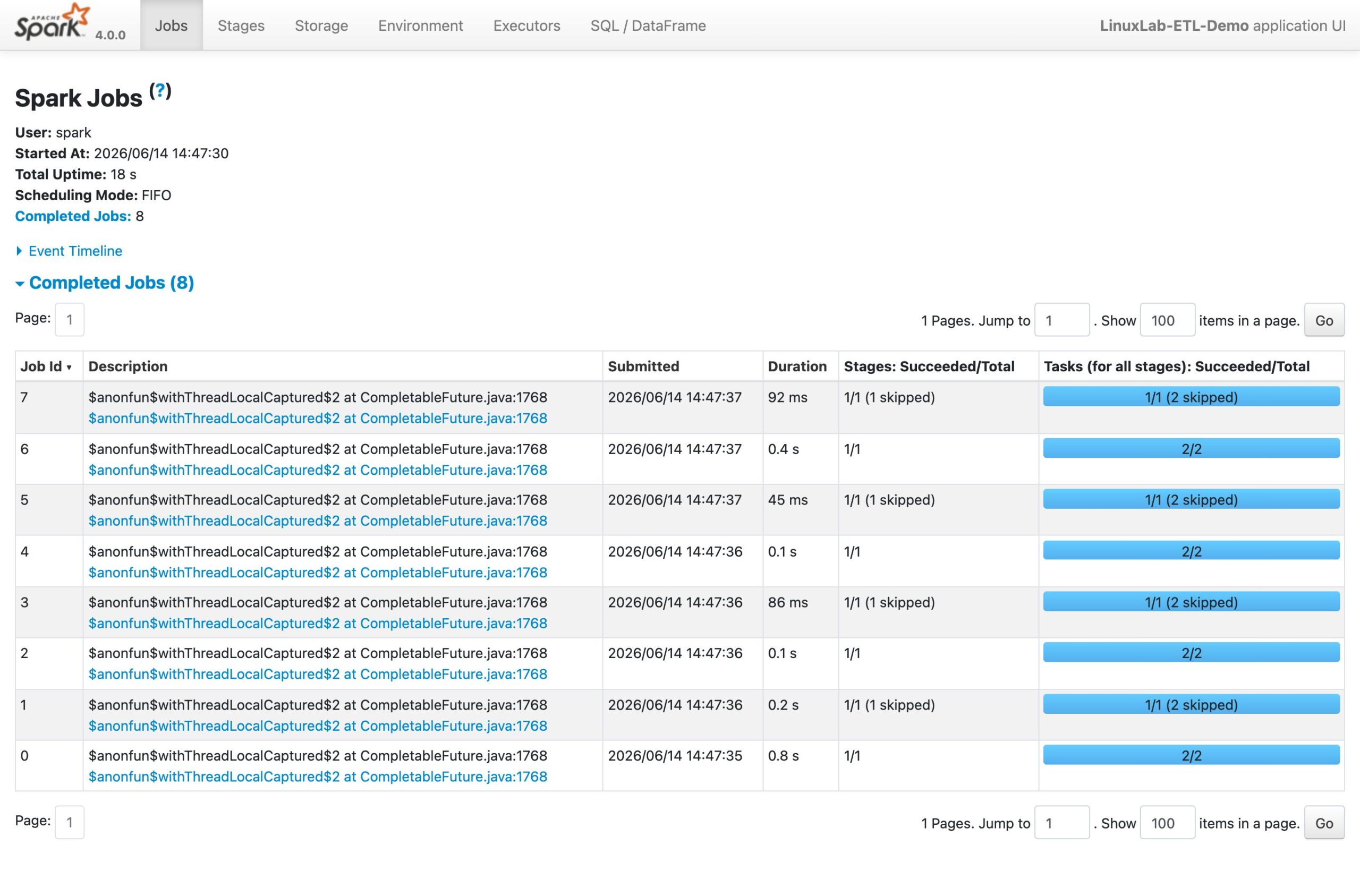
「Spark Jobs」のタブに、Completed Jobs (8) として実行済みのジョブが Duration・Stages 付きで並んでいます。重い処理が詰まったときは、この画面でどの Stage / Task が遅いかを切り分けるのが定石です。
クラスタのメモリ使用量を実測する
「Spark はメモリを食う」とよく言われます。実際どのくらいか、docker stats で master + worker 2台の常駐メモリを計測しました。

実測では master 245.7MiB、worker1 206.4MiB、worker2 216.7MiB で、3プロセス常駐で合計 約670MiBでした。ここで誤解しやすいのが、worker に -m 1g を割り当てても、それは「ジョブが使える上限」であって常駐メモリではないという点です。待機中は数百MiB で済み、実際のジョブを流すとそこから増えていきます。
とはいえ、ここに Driver と実データが加わるとあっという間に 1〜2GB を超えます。VPS で動かすなら、学習用でも最低 2GB、データを扱うなら 4GB 以上を見ておくのが安全です。東京リージョンのある低価格 VPS なら、まずはここから試せます。
History Serverで終わったジョブを後から見る
Application UI(4040)はアプリが動いている間だけ表示され、ジョブが終わると消えてしまいます。「さっきのジョブ、なぜ遅かったんだろう」を後から調べるには、イベントログを保存して History Server(標準ポート 18080)で読みます。
イベントログを spark.eventLog.enabled=true で出力し、History Server に読ませた実画面がこちらです。
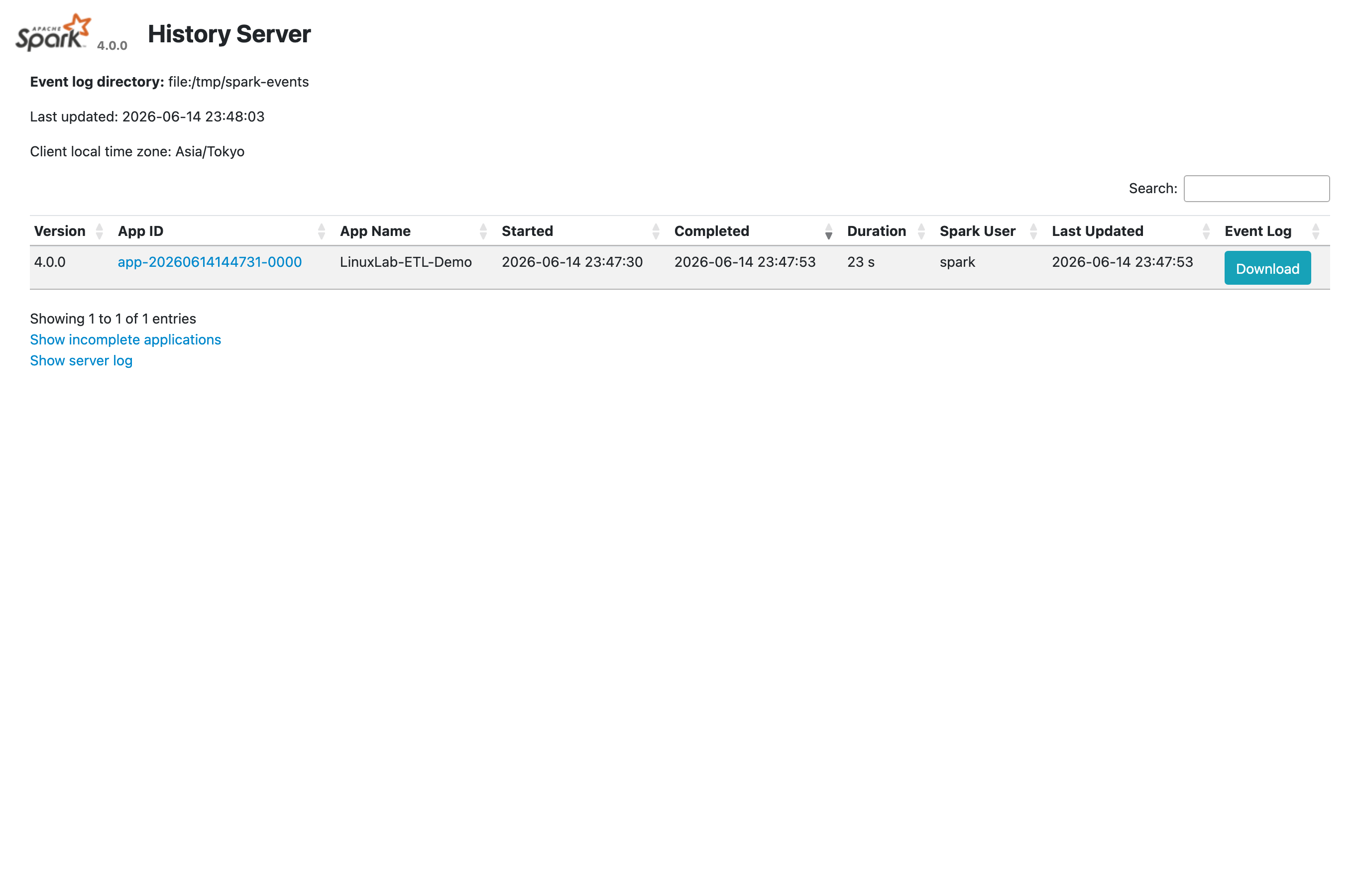
完了したアプリ LinuxLab-ETL-Demo(App ID app-20260614144731-0000)が、開始・完了時刻と Duration 23秒付きで記録されています。App ID のリンクを開けば、終了したアプリでも Jobs・Stages の詳細を 4040 と同じ画面で振り返れます。本番のデータ基盤では、この History Server を常駐させてジョブのトラブルシュートに使います。
よくあるエラーと解決策
① Worker が Master に登録されない(aliveworkers: 0)
前述のとおり、コンテナ名・ホスト名にアンダースコアを使うと Java のホスト名解決でつまずきます。spark-master のようにハイフンにしてください。Master の Web UI(8080)の Workers 欄が 0 のままなら、まずここを疑います。
② Initial job has not accepted any resources
「ジョブが投げられたのに一向に進まない」ときの典型です。Worker が Master に登録されていない、または要求したコア/メモリがクラスタの空きを超えている場合に出ます。Master UI で Cores in use と Memory in use を確認し、worker の割当(-c / -m)を見直します。
③ ClassNotFound / Scala バージョン不一致
自作の Scala アプリで NoSuchMethodError や ClassNotFound が出たら、ほぼ Scala バージョンの不一致です。Spark 4.0.0 は Scala 2.13 系。apt の scala(2.11.12)でビルドした jar は動きません。jar 名も spark-examples_2.13-4.0.0.jar のように _2.13 が付いている点を確認してください。
④ メモリ不足でコンテナ/ジョブが落ちる
1GB のような小さい環境では Executor が OOM で落ちます。spark.executor.memory を下げる、パーティション数を増やして1タスクあたりのデータを小さくする、そもそも 2GB 以上のプランにする、のいずれかで対処します。
まとめ
Apache Spark on Ubuntu を、実測ベースでまとめます。
- Spark は apt では入らない。公式の apache/spark:4.0.0 イメージか tar.gz を使う
- 公式イメージの中身は Spark 4.0.0 / Scala 2.13.16 / OpenJDK 17.0.15 / Python 3.10.12。JDK や Scala の別途インストールは不要
- apt の scala は 2.11.12 と古く、Spark 4(Scala 2.13)とは非互換。JDK だけ openjdk-17-jdk で入れる
- Docker で master + worker の standalone クラスタを組み、SparkPi と PySpark 集計を実行できた
- 小さなジョブではクラスタ(10.7秒)より local[*](7.0秒)が速い。分散が効くのは大きなデータのとき
- 常駐メモリは master+worker2台で約670MiB。VPS は最低2GB、できれば4GB以上が安心
- Master・Worker・Application・History の各 Web UI で状況を可視化できる
まずは Docker の local モードで PySpark に慣れ、感覚がつかめたら VPS 上で standalone クラスタを組むのがおすすめの順番です。Spark はメモリが命なので、VPS 選びはメモリ重視が鉄則です。東京リージョンのある VPS の実測比較はも参考にしてください。
「分散=速い」と思い込んでいると、小さいデータでクラスタを組んで逆に遅くなる、という罠にハマりがちです。まずは local[*] で動かして、本当にデータが大きくなってからクラスタ化を考えるくらいでちょうどいいですよ。

コメント