 ベンチマーク
ベンチマーク クラウドGPU各社の推論速度とコスパを実測【RunPod/Vast/Lambda】
「RunPodとVast.aiとLambdaって、結局どれが速くてコスパがいいの?」――クラウドGPUを使ってLLMや画像生成を試したい人なら一度は悩むポイントです。
ベンチマーク  ベンチマーク
ベンチマーク  ベンチマーク
ベンチマーク  ベンチマーク
ベンチマーク 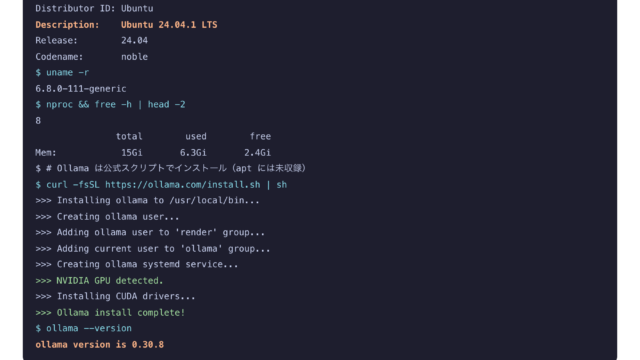 ベンチマーク
ベンチマーク  ベンチマーク
ベンチマーク