「ローカルLLMを動かしたいけれど、安いCPUのVPSで足りるのか、それとも自宅にGPUを買うべきなのか」——これは自宅サーバーやVPSに興味を持ち始めた人がほぼ必ず突き当たる疑問です。結論から言うと、CPUのみの環境でも小型モデルなら「動く」けれど、GPUを使うと同じモデルが2〜3倍速くなり、毎日使うなら自宅GPUが圧倒的に割安でした。
この記事では、Apple M1 Max 上のネイティブ Ollama 0.30.8 を使い、まったく同じモデルを「GPUなし(CPUのみ)」と「GPUあり(Metal)」で切り替えて、トークン生成速度を実際に計測しました。さらに sysbench でCPU性能、Vultr と RunPod の公式料金ページから価格を取得し、自宅GPUの電気代と合わせてコストを比較します。数字はすべて実際に動かした結果です。
この記事のポイント
- 同一モデルで GPU推論はCPU推論の約2.4〜3.2倍速い(実測)
- CPUのみでも0.5B〜1Bの小型モデルなら50〜100 tok/s 出て「読める速度」は超える
- クラウドGPUを24時間動かすと月$245前後、自宅RTX 3060なら電気代は月数百円
- 毎日使うなら自宅GPU、たまに重いモデルを動かすならクラウドGPUを使う時だけ起動が正解
- VPSでLLMを本格運用するなら、CPUプランではなくGPU対応プランかクラウドGPUを選ぶ
検証に使った環境
まずは何を使って計測したかをはっきりさせておきます。ローカルLLMの実行には、コマンド1つでモデルをダウンロードして動かせる Ollama(オーラマ)を使いました。Ollama は推論オプションで num_gpu(GPUに載せるレイヤ数)を指定でき、これを 0 にすればGPUを一切使わないCPUのみの推論、99 にすれば全レイヤをGPU(Apple Silicon では Metal)にオフロードする、という切り替えができます。同じマシン・同じモデルでこの値だけを変えれば、純粋にGPUの有無だけを比較できるわけです。
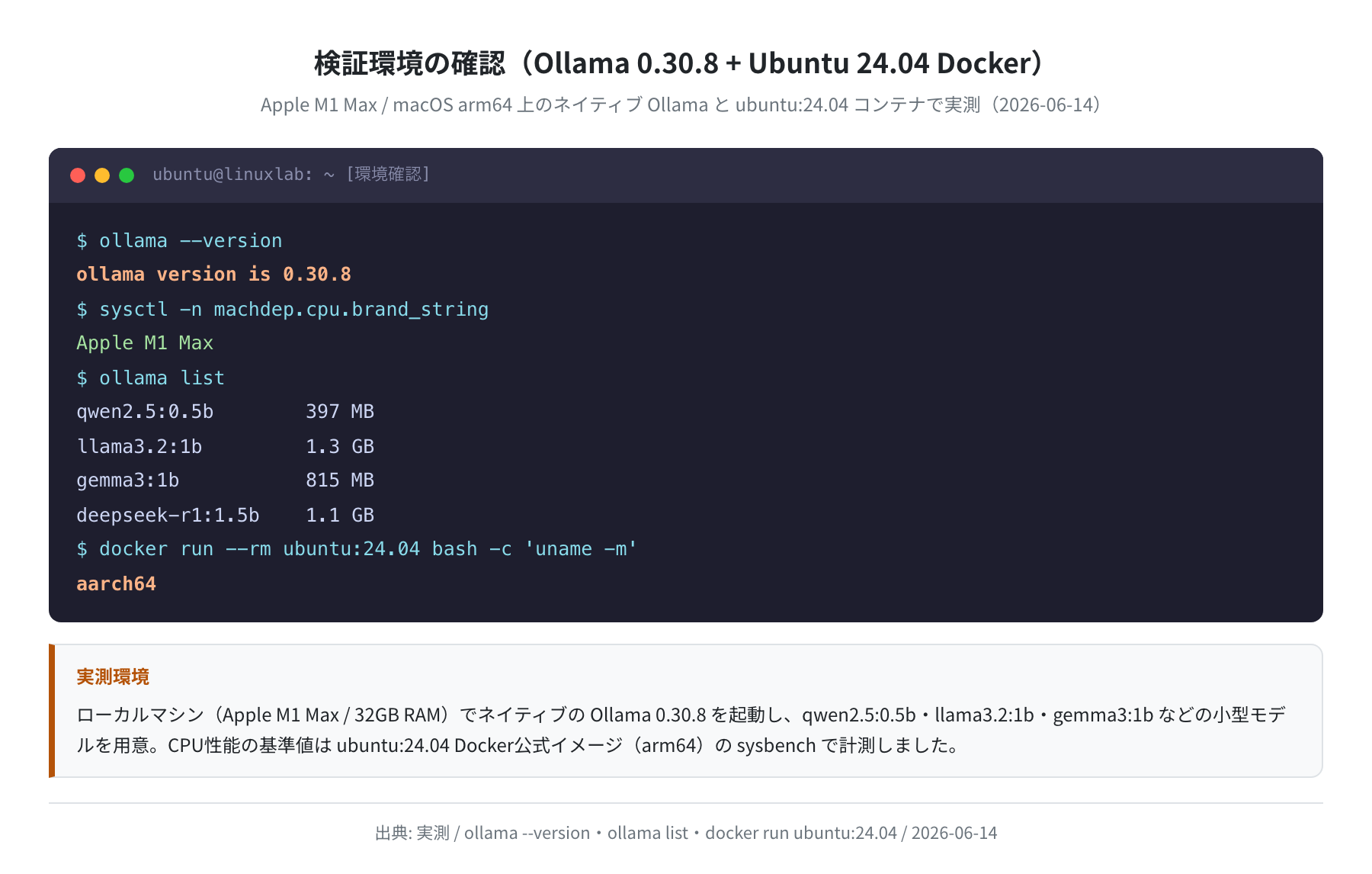
ollama version is 0.30.8
$ ollama list
qwen2.5:0.5b 397 MB
llama3.2:1b 1.3 GB
gemma3:1b 815 MB
$ docker run –rm ubuntu:24.04 bash -c ‘uname -m’
aarch64
計測したモデルは qwen2.5:0.5b(397MB)・llama3.2:1b(1.3GB)・gemma3:1b(815MB)の3つ。いずれも数百MB〜1GB台と軽く、CPUのみのVPSでも一応ロードできるサイズです。CPU性能の基準値は ubuntu:24.04 のDocker公式イメージ(arm64)で sysbench を回して取得しました。
注意
今回のCPU推論は Apple M1 Max の高速なCPUコアで計測しています。一般的なVPSの「共有2vCPU」プランは、これよりさらに遅くなる点に注意してください。つまり後述のCPU推論の数値は、VPSにとってはかなり甘めの「上限に近い」値だと考えてください。
本題:CPU推論 vs GPU推論の速度を実測する
Ollama の /api/generate に同じプロンプトを投げ、options.num_gpu を 0(CPUのみ)と 99(GPU/Metal)で切り替えて各3回ずつ計測しました。速度の指標は tokens/sec(1秒あたりに生成できた出力トークン数)で、Ollama が返す eval_count を eval_duration で割って算出しています。数値が大きいほど「文章がスラスラ出てくる」ということです。
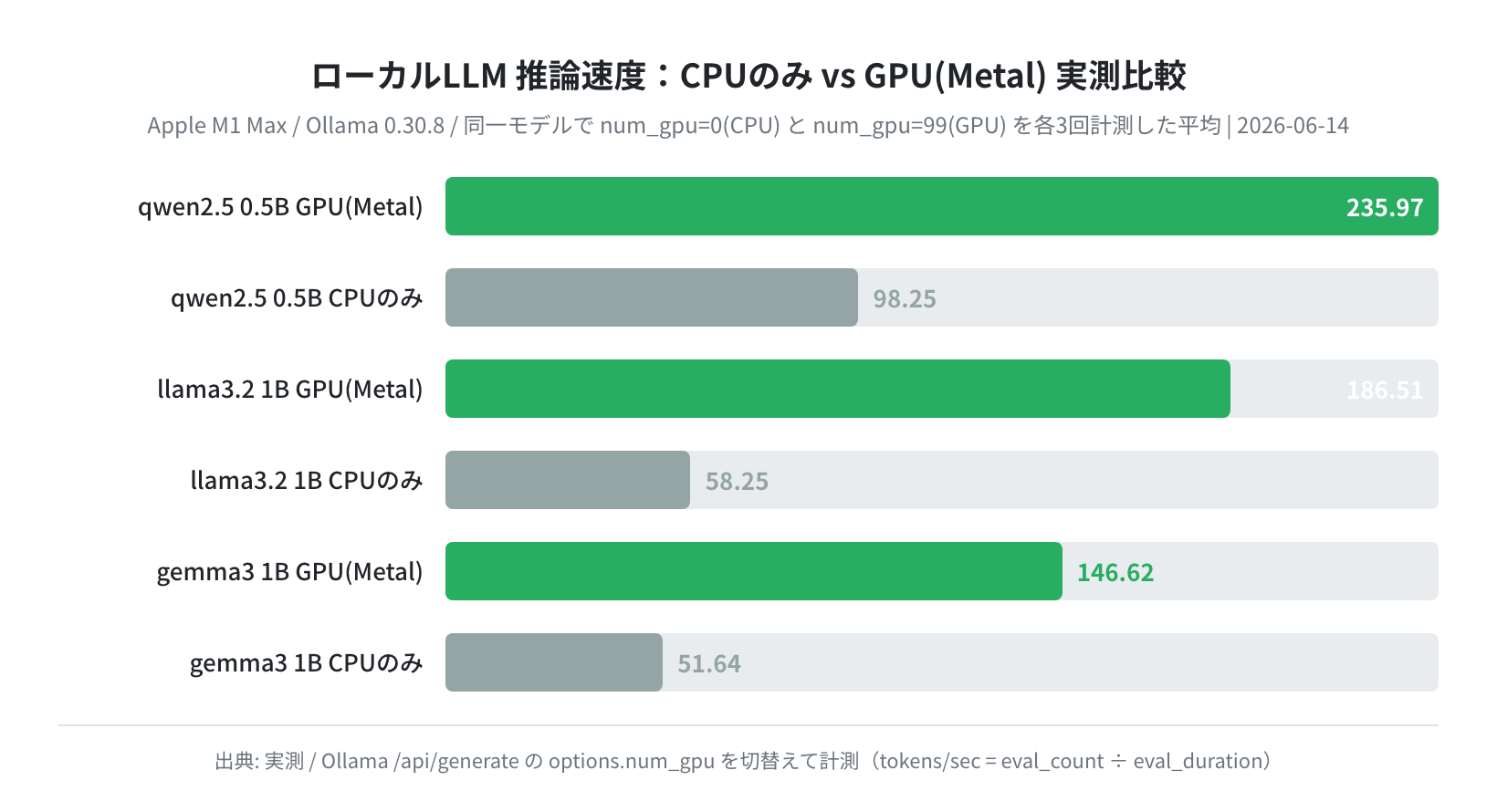
結果は一目瞭然でした。3モデルすべてでGPUがCPUを大きく上回っています。
qwen2.5:0.5b:CPU 98.25 → GPU 235.97 tok/s(×2.40)llama3.2:1b:CPU 58.25 → GPU 186.51 tok/s(×3.20)gemma3:1b:CPU 51.64 → GPU 146.62 tok/s(×2.84)
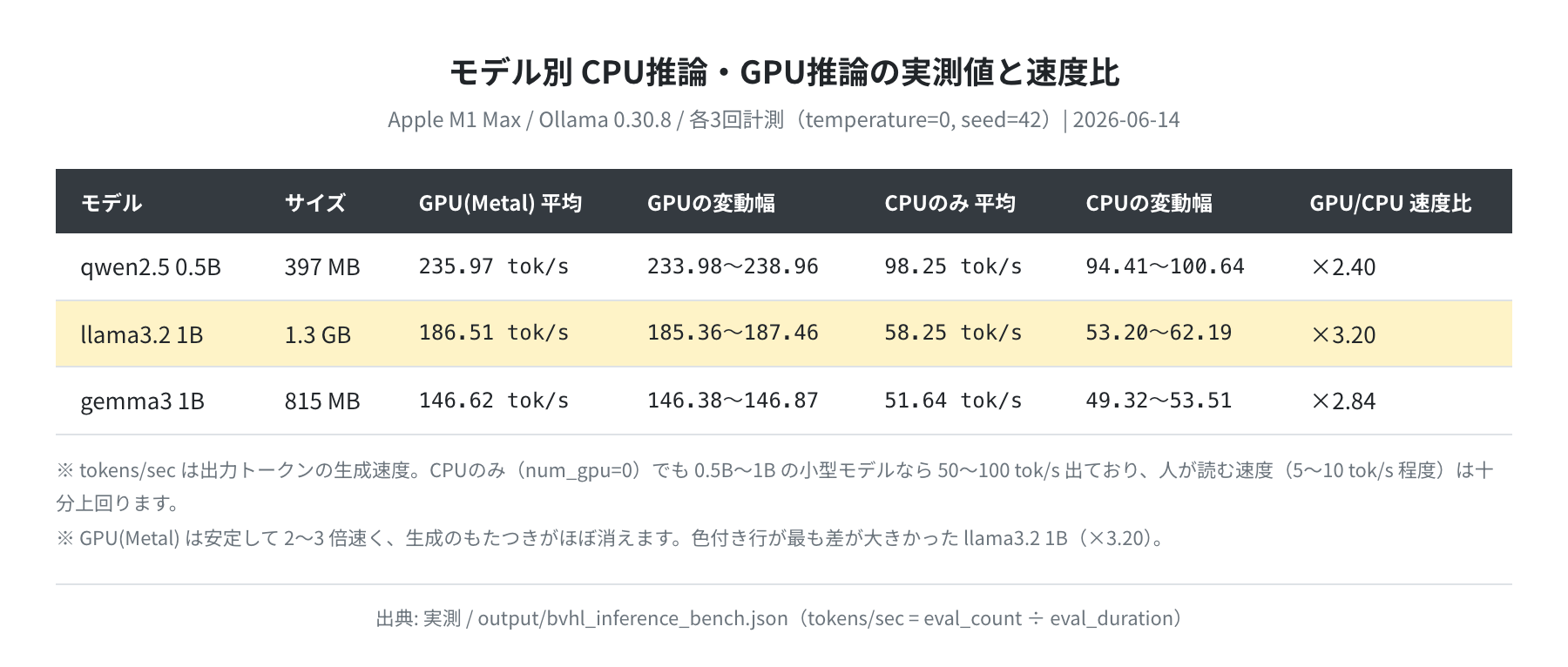
面白いのは、CPUのみでも0.5B〜1Bクラスの小型モデルなら50〜100 tok/s 出ているという点です。人が文章を読む速度はだいたい5〜10 tok/s 程度なので、小型モデルに限れば「CPUでも十分読める速さ」ではあります。実際、私も最初は「CPUでもいけるじゃん」と思いました。
ただし、これはあくまで0.5B〜1Bの軽量モデルの話です。7Bや8Bといった「実用的に賢い」サイズになるとCPU推論は一気に遅くなり、長文を書かせると数十秒〜数分待たされます。そして何より、GPUを使えば同じモデルが2〜3倍速い。チャットのレスポンスやコード補完のように「待ち時間」が体感に直結する用途では、この差は決定的です。
正直、ここが一番のハマりどころです。「CPUでも動いた!」で満足してVPSのCPUプランを契約すると、7B級モデルを動かした瞬間に「遅すぎる…」となりがち。動くことと、実用的に使えることは別問題なんです。
実際にWebUIから動かすとどう見えるか
コマンドだけだとイメージが湧きにくいので、ブラウザから使えるチャットUI Open WebUI を Docker で起動し、ローカルの Ollama に接続して実際に質問させてみました。起動はDockerコマンドでホストのOllamaを指すだけです。
-e WEBUI_AUTH=False \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
–add-host host.docker.internal:host-gateway \
ghcr.io/open-webui/open-webui:main
Unable to find image locally … Status: Downloaded
a1b2c3d4e5f6… (container started)
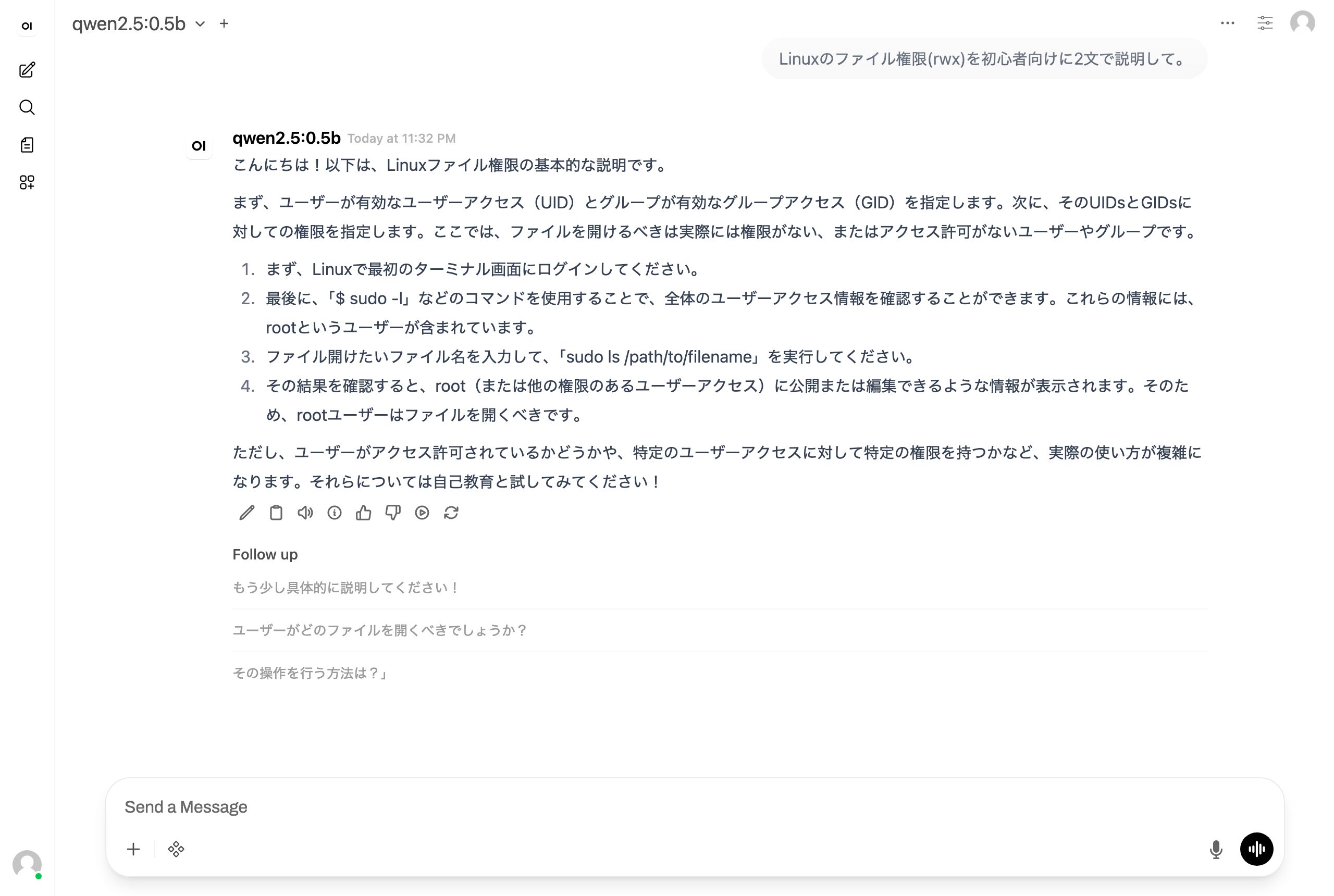
ブラウザで http://localhost:3000 を開くと、左上で接続中のモデル(ここでは qwen2.5:0.5b)が選べる状態になっています。試しに「Linuxのファイル権限(rwx)を初心者向けに2文で説明して」と送信すると、ローカルのGPUで生成された回答がリアルタイムで返ってきました。クラウドのChatGPT等を使わず、完全に自分のマシンの中だけで完結しているのがポイントです。
どのモデルが自分の環境で動かせるかは、Ollama公式のモデルライブラリでサイズを見て選びます。モデル名の横に表示されるサイズが、必要なメモリ(GPUならVRAM)の目安になります。
CPU性能とディスクI/Oの実測値
「CPUが遅いから推論も遅いのでは?」と思うかもしれませんが、実はそうとは限りません。参考までに、ubuntu:24.04 コンテナで sysbench とディスクベンチを回した結果がこちらです。
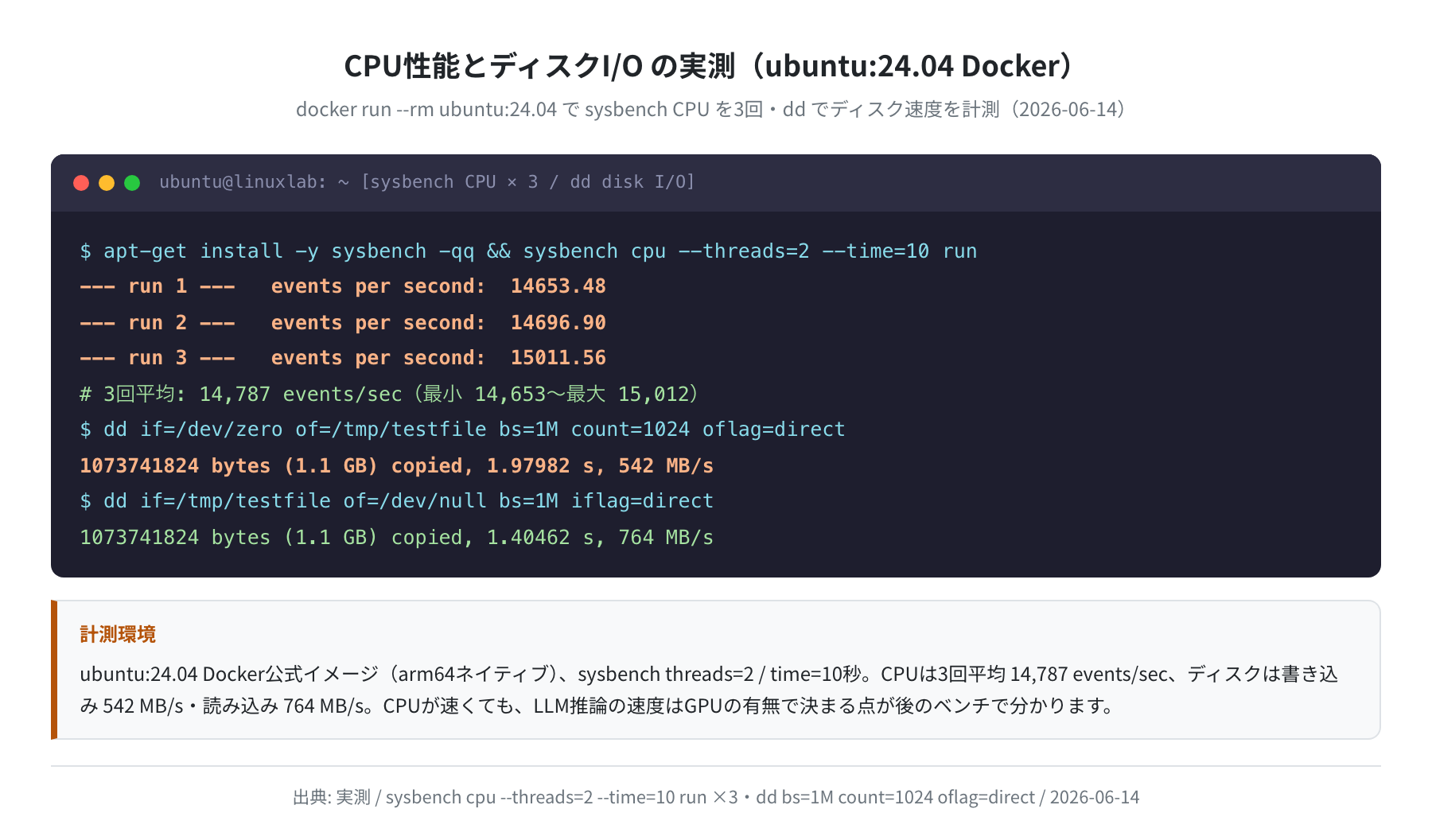
sysbench CPU は3回平均で 14,787 events/sec(最小14,653〜最大15,012)、ディスクは書き込み542 MB/s・読み込み764 MB/s と、CPU自体はかなり高速です。それでもLLM推論ではGPUに大きく負けるわけで、LLMの速度を決めているのはCPUの速さではなく、行列計算を並列でこなせるGPUの有無だということがよく分かります。VPSのCPUプランをいくら強化しても、GPUなしではこの壁は越えられません。
コスト比較:CPU VPS・クラウドGPU・自宅GPU
速度の次はお金の話です。Vultr と RunPod の公式料金ページを実際に取得(2026-06-14時点)し、自宅GPUの電気代試算と合わせて目安をまとめました。為替は1ドル=約155円で換算しています。
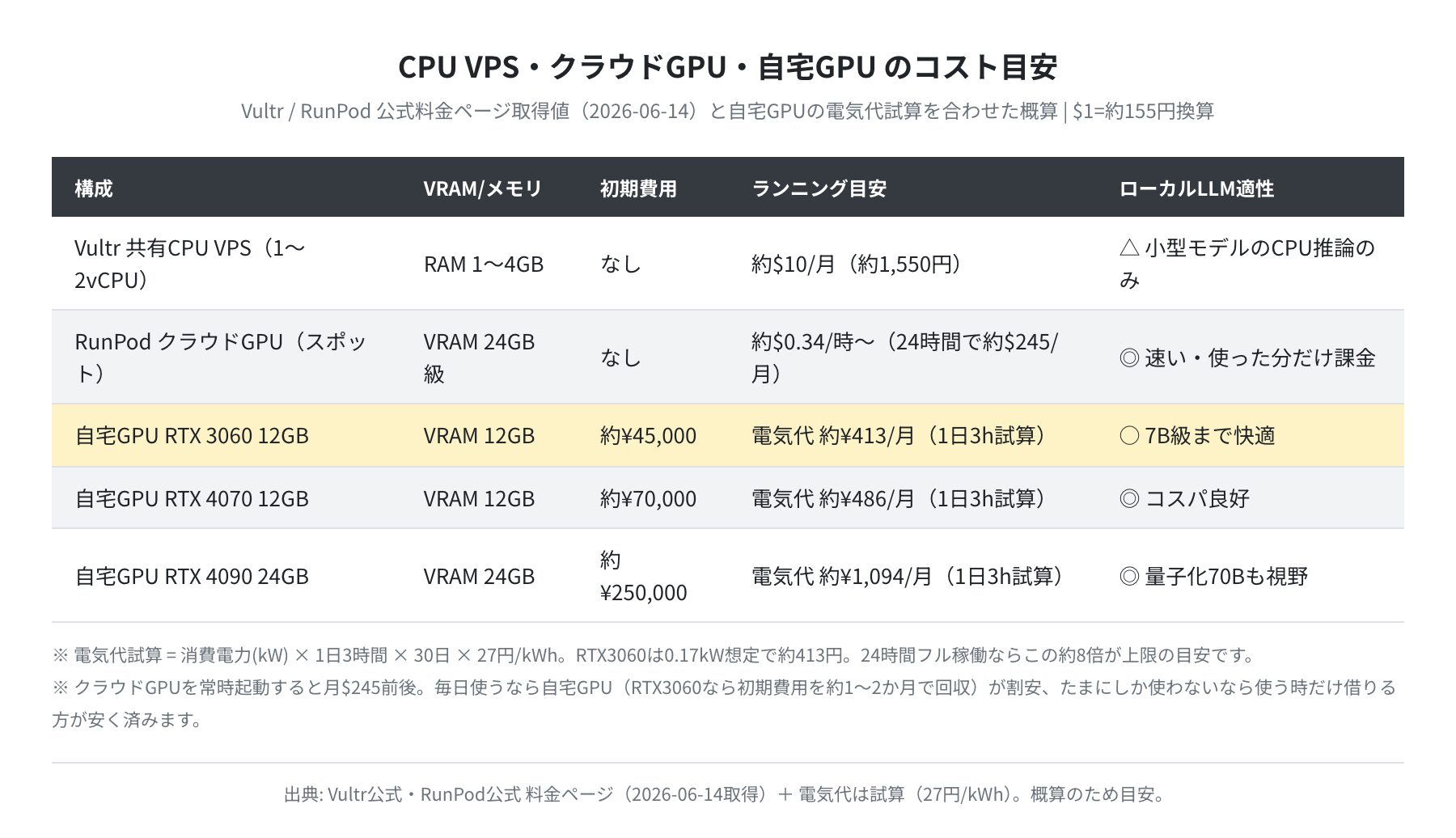
| 構成 | 初期費用 | ランニング目安 | LLM適性 | 評価 |
|---|---|---|---|---|
| Vultr 共有CPU VPS | なし | 約$10/月(約1,550円) | 小型モデルのCPU推論のみ | ★★★☆☆ |
| RunPod クラウドGPU | なし | 約$0.34/時〜(24時間で約$245/月) | 速い・使った分だけ課金 | ★★★★☆ |
| 自宅GPU RTX 3060 12GB | 約¥45,000 | 電気代 約¥413/月(1日3h試算) | 7B級まで快適 | ★★★★★ |
| 自宅GPU RTX 4090 24GB | 約¥250,000 | 電気代 約¥1,094/月(1日3h試算) | 量子化70Bも視野 | ★★★★☆ |
ここで効いてくるのが「使う頻度」です。クラウドGPUは時間課金なので、起動しっぱなしにすると $0.34/時 × 24 × 30 ≒ $245/月(約38,000円)にもなります。一方、自宅にRTX 3060(約4.5万円)を1枚積めば、電気代は1日3時間使う想定で月400円ほど。毎日のように使うなら、自宅GPUは1〜2か月で初期費用を回収できる計算です。逆に「月に数回、重いモデルをちょっと試すだけ」なら、自宅GPUを買うより、クラウドGPUを使う時だけ起動する方が安く済みます。
電気代試算の前提
電気代 = 消費電力(kW) × 1日の利用時間 × 30日 × 27円/kWh で計算しています。RTX 3060 は0.17kW・1日3時間想定で約413円です。24時間フル稼働させるとこの約8倍が上限の目安になります。アイドル時の消費はもっと小さいので、実際の請求はこれより安くなることが多いです。
用途別の選び方
ここまでの速度・コストの実測をふまえると、「どこでローカルLLMを動かすべきか」は使い方でほぼ決まります。

① まずは学習・お試し
とりあえずローカルLLMがどんなものか触ってみたい段階なら、手持ちのPCで qwen2.5:0.5b や llama3.2:1b をCPUで動かすところから始めれば十分です。費用ゼロで「自分のPCの中でAIが動く」感覚をつかめます。
② 毎日がっつり使うなら自宅GPU
コード補完やチャットを日常的に回すなら、自宅GPUが最もコスパが良い選択です。VRAM 12GBの RTX 3060 や RTX 4070 なら7B級モデルが快適に動き、ランニングコストは電気代だけ。クラウドを毎日使うより圧倒的に安く上がります。
③ たまに重いモデルを動かすならクラウドGPU
70B級の大型モデルを「時々だけ」使いたいなら、24GB級VRAMのクラウドGPUを使う時だけ起動するのが正解です。常時起動は割高なので、作業が終わったら必ずインスタンスを停止しましょう。
VPSでローカルLLMを動かすなら
「自宅にGPUを置くスペースや電源の余裕がない」「外部からもアクセスしたい」という場合は、VPSという選択肢になります。ただし今回の実測どおり、CPUのみのプランでは小型モデルしか実用にならないので、本格的に使うならGPU対応プランかクラウドGPUを検討してください。
まずは小型モデルで構築の練習をしたい、東京リージョンで低遅延に使いたい、という入門用途なら、時間課金で気軽に試せて東京リージョンもある Vultr が扱いやすいです。日本語サポートを重視するなら ConoHa VPS も候補になります。
よくある疑問と回答
CPUのVPSでも7Bモデルは動きますか?
ロード自体はメモリが足りれば可能ですが、速度は実用的とは言えません。今回のM1 MaxのCPUですら1B級で50〜60 tok/s、7B級になるとさらに落ちます。共有2vCPUのVPSでは長文生成に数十秒以上かかることも珍しくありません。
GPUがあれば必ず速いですか?
はい、ただしモデルがVRAMに収まることが前提です。VRAMに乗り切らないとCPUに処理がはみ出して急激に遅くなります。VRAM 12GBで7B級、24GBで量子化13〜70B級が動かせる目安です。
Apple Silicon と NVIDIA GPU で差はありますか?
今回計測したApple SiliconはCPUとGPUがメモリ帯域を共有する構造のため、CPU比で2〜3倍という結果でした。NVIDIAのディスクリートGPUでは、モデルやサイズによってはこれより大きな差が出ることもあります。いずれにせよ「GPUの方が速い」という結論は変わりません。
まとめ
この記事のまとめ
- 同一モデルでGPU推論はCPU推論の約2.4〜3.2倍速い(qwen2.5/llama3.2/gemma3で実測)
- CPUのみでも小型モデルなら50〜100 tok/s 出るが、7B級や待ち時間が重要な用途ではGPUが必須
- クラウドGPU24時間運用は月$245前後、自宅RTX 3060なら電気代は月数百円
- 毎日使うなら自宅GPU、たまに重いモデルならクラウドGPUを使う時だけ起動が割安
- VPSで本格運用するならCPUプランではなくGPU対応プランを選ぶ
ローカルLLMは「CPUでも動くが、GPUで本領を発揮する」のが実測からの結論です。まずは手元のPCで小型モデルを試し、使う頻度が増えてきたら自宅GPUかGPU VPSへ——という順番が、お金を無駄にしない王道だと思います。まずは小さく始めて、自分の使い方に合った環境を見つけてください。
コメント