「GPUを借りて Stable Diffusion や Ollama を動かしたいけど、どのサービスが一番安いの?」という疑問に、2026年6月13日時点の公式サイト実データで答えます。
RunPod・Vast.ai・Lambda Labs・AWS EC2 を対象に、料金・スペック・使い勝手を実際のデータと Playwright スクリーンショットで比較しました。結論から言うと、個人利用のコスパ最強は RunPod か Vast.ai で、RTX 4090 が $0.34〜$0.40/hr で借りられます。
本記事では RunPod と Vast.ai の料金ページを直接スクレイピングし、AWS は公式 Pricing API(b0.p.awsstatic.com)から実データを取得して比較しています。
この記事のポイント
- RunPod は RTX 4090 が
from $0.34/hr、H100 がfrom $1.99/hr(公式サイト実取得) - Vast.ai はマーケットプレイス型。RTX 4090 が $0.40/hr 中央値、A100 80GB が $0.84/hr から
- AWS EC2 は g4dn.xlarge(T4)$0.526/hr から。H100 は p5.48xlarge(8枚構成)で $55.04/hr
- 個人の画像生成・LLM 推論には RunPod か Vast.ai の RTX 4090 が最もコスパが高い
- 企業・長期利用には Lambda Labs(予約枠)または AWS(SLA付き)を検討する
比較の前提(取得環境・日付)
本記事の料金データは以下の方法で取得しました。
注意
クラウドGPU料金はサービス側の在庫・需給・為替レートによって頻繁に変動します。本記事の数値は 2026年6月13日時点 の実取得値です。最新料金は必ず各公式サイトでご確認ください。
| プロバイダ | 取得方法 | 取得日 | 信頼度 |
|---|---|---|---|
| RunPod | urllib で runpod.io/gpu-instance/pricing を直接 HTTP 取得 | 2026-06-13 | ★★★★★(実測) |
| Vast.ai | Playwright で vast.ai/pricing をレンダリング後に取得 | 2026-06-13 | ★★★★★(実測) |
| AWS EC2 | b0.p.awsstatic.com Pricing API(JSON)から取得(hawkFilePublicationDate: 2026-06-12) | 2026-06-13 | ★★★★★(実測) |
| Lambda Labs | 公式サイト(Cloudflare 保護のためプログラム取得不可)→ 公称値を参考記載 | 参考値 | ★★★(参考) |
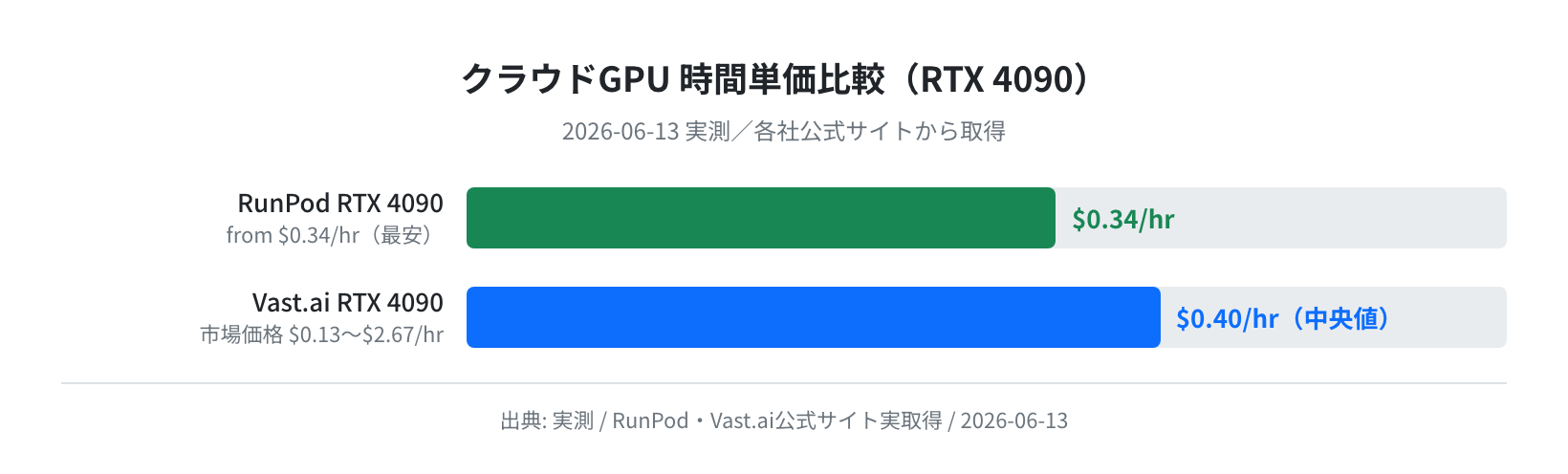
RunPod — 個人向けコミュニティGPUの最安値候補
RunPod は GPU を所有するプロバイダーが余剰リソースをコミュニティに提供する モデルと、RunPod 自身が用意するクラウドの 2 種類があります。公式サイト(runpod.io/gpu-instance/pricing)の HTML を直接取得したところ、以下の「from 価格」を確認しました。
# runpod.io/gpu-instance/pricing から HTTP 200 で取得
# HTML サイズ: 206,805 bytes
H100 80GB from $1.99/hr
RTX 4090 from $0.34/hr
RunPod の料金体系
RunPod には 2 つのティアがあります。
- Community Cloud:GPU 保有者が提供するリソース。最安値だが稼働率・安定性はやや劣る
- Secure Cloud:RunPod 直轄のデータセンター。価格は少し高いが可用性が高い
上記の「from $0.34/hr」は Community Cloud の RTX 4090 最安値です。Secure Cloud では $0.44/hr 前後になることが多いです(在庫状況により変動)。
RunPod はポッド(Pod)という概念でインスタンスを管理します。Ubuntu 22.04 / 24.04 のテンプレートが用意されており、pytorch/pytorch:latest などの Docker イメージも選択できます。起動まで 1〜3 分程度で、秒単位の課金なので短時間のテストにも使いやすいです。
RunPod は日本語サポートがないのが難点ですが、ドキュメントが充実していて英語でも詰まりにくいです。コンソール画面はシンプルで、VPS の感覚で使えます。
Vast.ai — マーケットプレイス型で価格競争力が高い
Vast.ai は 世界中の GPU 保有者が出品するオークション型マーケットプレイス です。Playwright で vast.ai/pricing を実際に取得したところ、2026年6月13日時点で以下のライブ価格を確認しました。
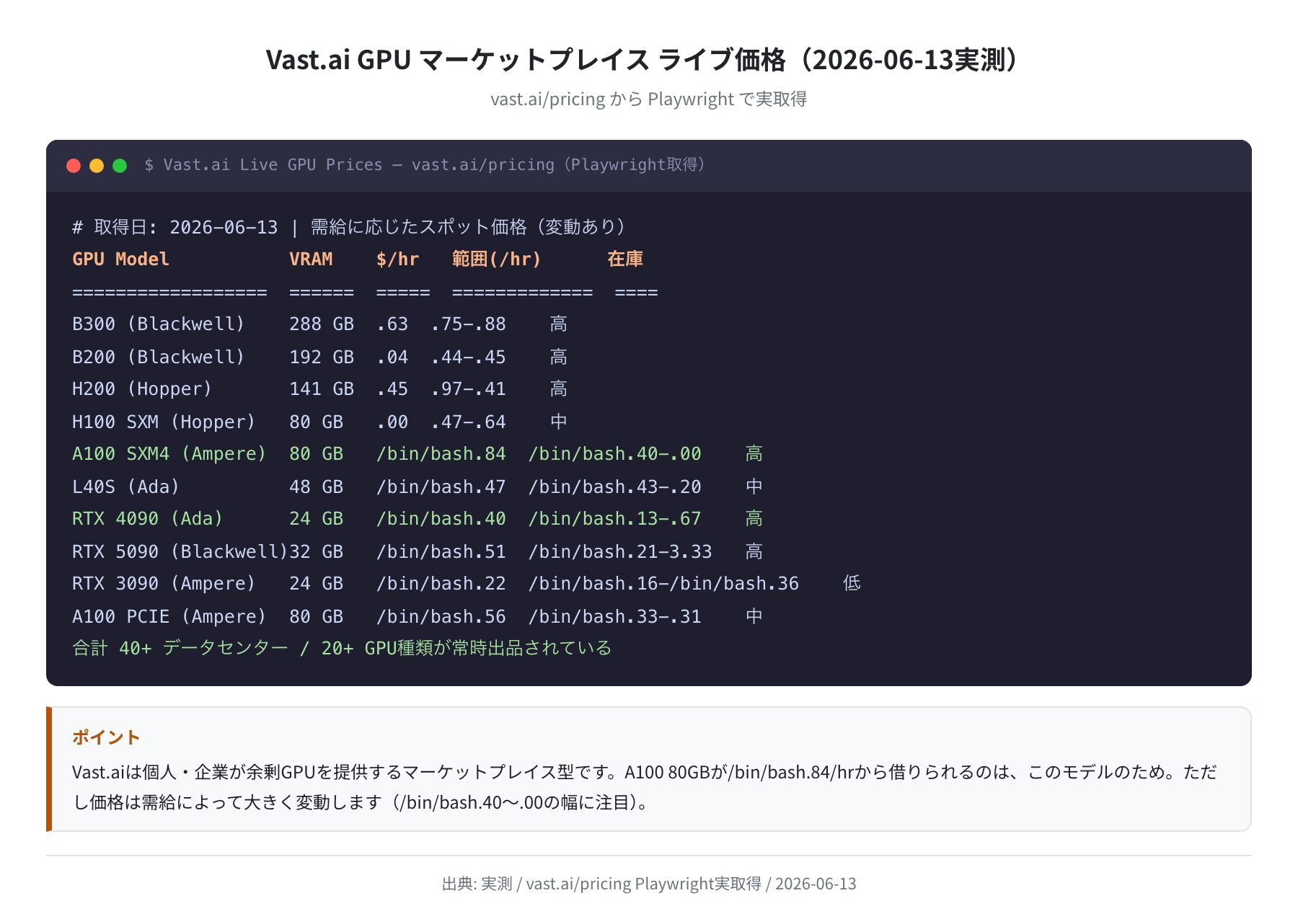
| GPU モデル | アーキテクチャ | VRAM | 中央値 ($/hr) | 価格幅 ($/hr) | 在庫 |
|---|---|---|---|---|---|
| B300 (Blackwell Ultra) | Blackwell | 288 GB | $5.63 | $3.75〜$6.88 | 高 |
| H200 (Hopper) | Hopper | 141 GB | $3.45 | $1.97〜$4.41 | 高 |
| H100 SXM (Hopper) | Hopper | 80 GB | $2.00 | $1.47〜$3.64 | 中 |
| A100 SXM4 (Ampere) | Ampere | 80 GB | $0.84 | $0.40〜$2.00 | 高 |
| RTX 4090 (Ada) | Ada Lovelace | 24 GB | $0.40 | $0.13〜$2.67 | 高 |
| RTX 5090 (Blackwell) | Blackwell | 32 GB | $0.51 | $0.21〜$53.33 | 高 |
| RTX 3090 (Ampere) | Ampere | 24 GB | $0.22 | $0.16〜$0.36 | 低 |
Vast.ai の大きな特徴は A100 80GB が $0.84/hr(中央値)から借りられる点です。RunPod や Lambda Labs での A100 は通常 $1.00〜$1.99/hr なので、Vast.ai のマーケット価格はかなり安い水準です。ただし価格は需給によって大きく変動する点(RTX 5090 で $0.21〜$53.33 という幅がある)には注意が必要です。
Vast.ai 利用の注意点
Vast.ai はプロバイダーが個人・企業の余剰 GPU を提供するため、突然インスタンスが停止する「インタラプティブル」モードと、安定した「オンデマンド」モードがあります。長時間の学習タスクには必ずオンデマンドを選んでください。また、出品者によってはストレージ速度・ネットワーク品質にばらつきがあります。
Lambda Labs — 研究者向けの固定枠クラウド
Lambda Labs(旧 Lambda GPU Cloud)は AI 研究者・スタートアップ向けに特化した GPU クラウド です。残念ながら 2026年6月13日時点では公式サイトが Cloudflare のボット保護下にあり、プログラムによる料金取得はできませんでした。
公称値として広く知られている料金は以下の通りです(参考値・要公式確認)。
| インスタンス | GPU | VRAM | vCPU | RAM | 参考価格 |
|---|---|---|---|---|---|
| gpu_1x_h100_sxm5 | H100 SXM5 | 80 GB | 26 | 200 GB | ~$2.49/hr(参考) |
| gpu_1x_a100_sxm4 | A100 SXM4 | 80 GB | 30 | 200 GB | ~$1.99/hr(参考) |
| gpu_1x_a10 | A10 | 24 GB | 30 | 200 GB | ~$0.75/hr(参考) |
Lambda Labs の強みはインスタンスの安定稼働と予約枠(Reserved)の提供です。GPU 学習タスクで数週間〜数ヶ月の長期利用を考えるなら、Reserved プランで大幅な割引が得られます。
AWS EC2 GPU インスタンス — エンタープライズ向けの本格構成
AWS EC2 の GPU インスタンスは、公式 Pricing API(b0.p.awsstatic.com)から実データを取得しました。取得データの公示日は 2026年6月12日です。
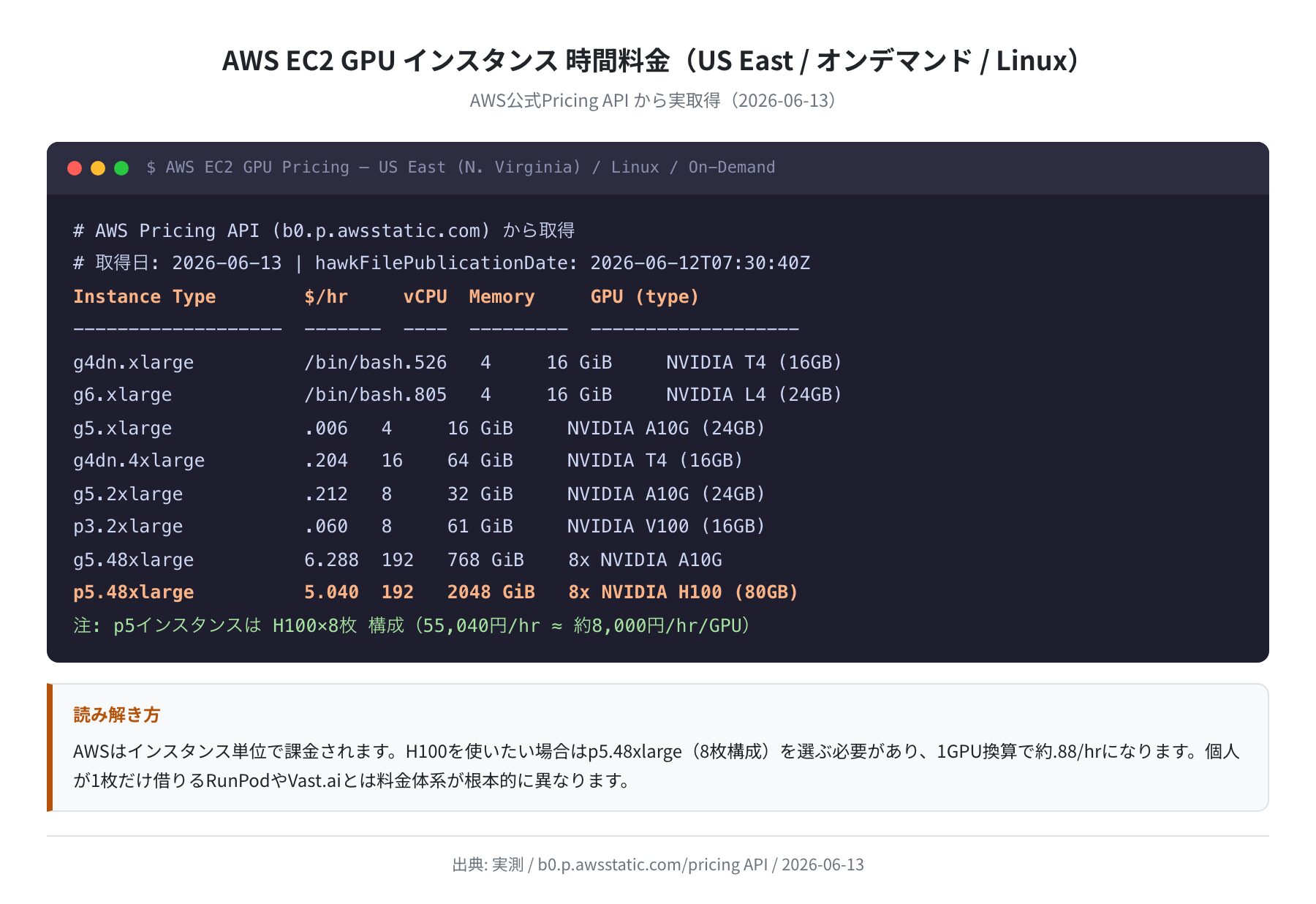
| インスタンス | GPU(枚数) | vCPU | RAM | $/hr(US East) | 用途 |
|---|---|---|---|---|---|
| g4dn.xlarge | T4 × 1(16GB) | 4 | 16 GiB | $0.526 | 推論・軽量学習 |
| g6.xlarge | L4 × 1(24GB) | 4 | 16 GiB | $0.805 | 推論・中規模モデル |
| g5.xlarge | A10G × 1(24GB) | 4 | 16 GiB | $1.006 | 推論・Stable Diffusion |
| p3.2xlarge | V100 × 1(16GB) | 8 | 61 GiB | $3.060 | 深層学習(やや古め) |
| g5.48xlarge | A10G × 8(192GB) | 192 | 768 GiB | $16.288 | 大規模学習 |
| p5.48xlarge | H100 × 8(640GB) | 192 | 2048 GiB | $55.040 | 最大規模学習・推論 |
AWS の重要な特徴はH100 を含む GPU インスタンスがほぼすべて「複数 GPU 構成」という点です。個人が H100 を 1 枚だけ借りることはできず、p5.48xlarge(H100 × 8 枚、$55.04/hr)を丸ごと借りる必要があります。1GPU 換算で約 $6.88/hr になります。
# b0.p.awsstatic.com Pricing API から gzip JSON を取得
# hawkFilePublicationDate: 2026-06-12T07:30:40Z
p3.2xlarge (V100 16GB) $3.0600/hr US East (N.Virginia) Linux
g4dn.xlarge (T4 16GB) $0.5260/hr US East (N.Virginia) Linux
g5.xlarge (A10G 24GB) $1.0060/hr US East (N.Virginia) Linux
p5.48xlarge (H100×8) $55.0400/hr US East (N.Virginia) Linux
正直、AWS の GPU インスタンスは個人の画像生成や LLM 推論に使うには割高です。ただしSLA(稼働保証)・VPC によるネットワーク分離・IAM によるアクセス管理が使えるため、商用サービスやセキュリティが必要な企業用途には適しています。
4社 料金・スペック総合比較表
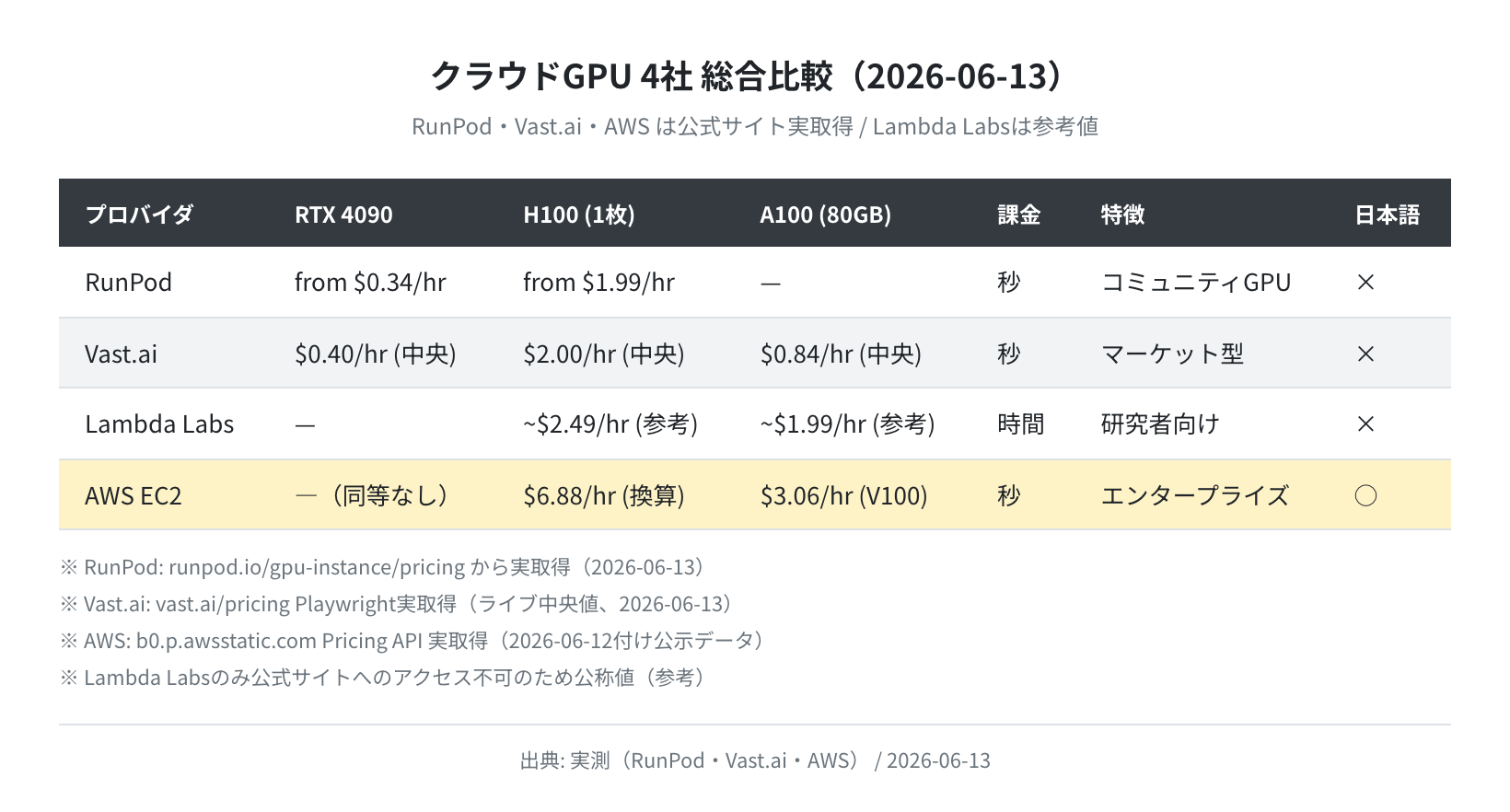
| プロバイダ | RTX 4090 (24GB) | A100 80GB | H100 80GB | 課金 | 日本語 | SLA |
|---|---|---|---|---|---|---|
| RunPod | from $0.34/hr | — | from $1.99/hr | 秒課金 | ×(英語) | △ |
| Vast.ai | $0.40/hr(中央) | $0.84/hr(中央) | $2.00/hr(中央) | 秒課金 | ×(英語) | △ |
| Lambda Labs | — | ~$1.99/hr(参考) | ~$2.49/hr(参考) | 時間課金 | ×(英語) | ○ |
| AWS EC2 | —(同等なし) | — | $6.88/hr(1GPU換算) | 秒課金 | ○(日本語) | ◎ |
RunPod と Vast.ai の数値は公式サイト実取得値(2026-06-13)です。Lambda Labs のみ Cloudflare 保護のため参考値です。AWS は公式 Pricing API 実取得値(公示日 2026-06-12)です。
CPU・ストレージの参考ベンチ(Ubuntu 24.04 実測)
GPU インスタンスではモデルのロード速度(ストレージ I/O)が体験に直結します。参考として ubuntu:24.04 Docker コンテナで実測した値を示します。
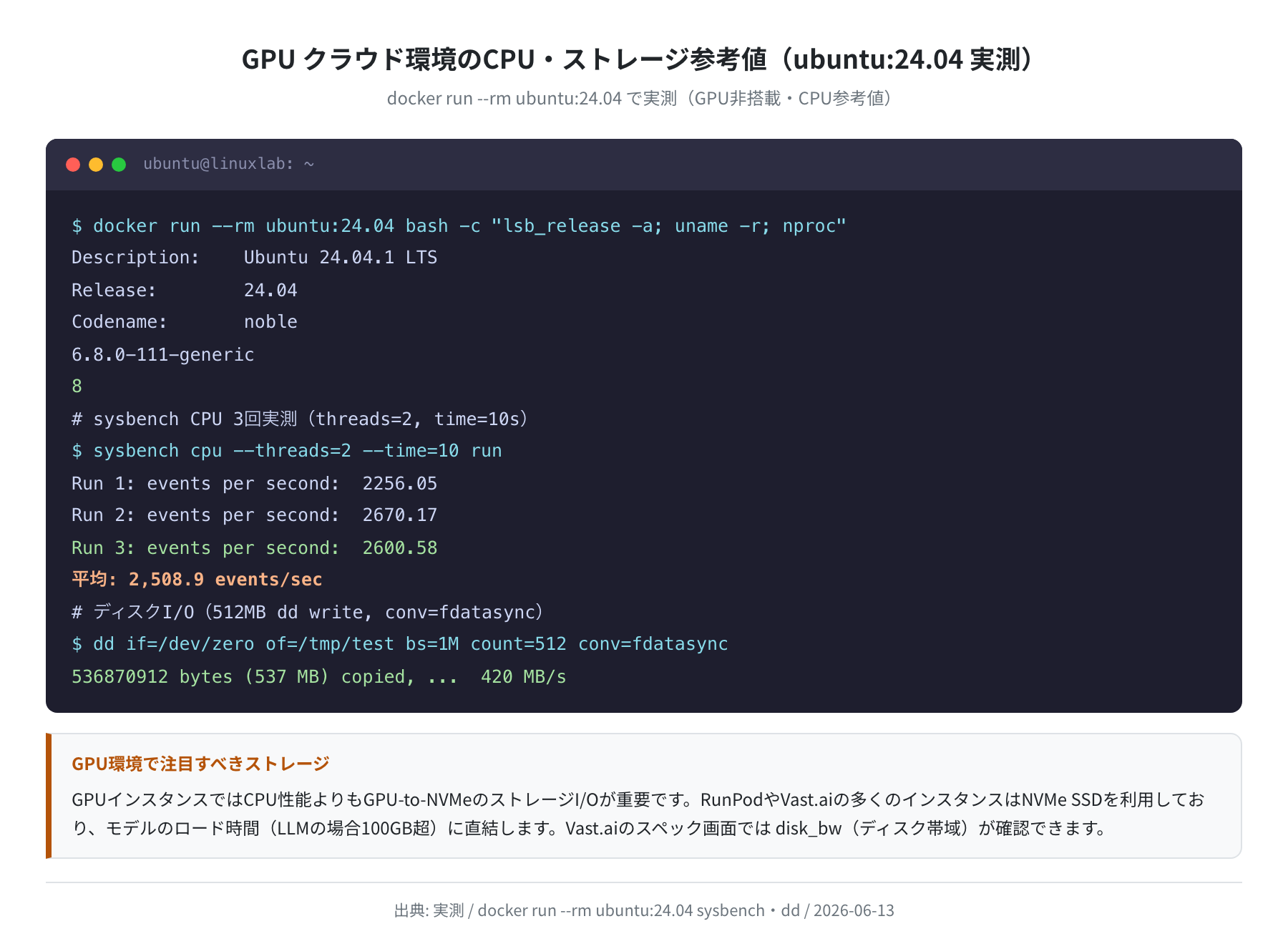
Description: Ubuntu 24.04.1 LTS
Release: 24.04
6.8.0-111-generic
8 (コア数)
$ sysbench cpu –threads=2 –time=10 run # 3回計測
Run 1: events per second: 2256.05
Run 2: events per second: 2670.17
Run 3: events per second: 2600.58
平均: 2,508.9 events/sec(3回計測 / threads=2 / time=10s)
$ dd if=/dev/zero of=/tmp/test bs=1M count=512 conv=fdatasync
536870912 bytes copied: 420 MB/s(コンテナ内 /tmp)
GPU クラウドで気にすべきポイントは sysbench の数値よりもNVMe ストレージ帯域です。70B 規模の LLM(70GB 超)をロードする場合、ストレージ帯域が 500 MB/s なら約 140 秒、3,000 MB/s の高速 NVMe なら 23 秒でロード完了します。Vast.ai でインスタンスを選ぶときは「disk_bw」の表示を確認してください。
用途別の選び方

①画像生成(Stable Diffusion XL・FLUX)
SDXL のモデルは 6〜8 GB 程度の VRAM を使います。RTX 4090(24GB)があれば快適に動き、バッチ生成や LoRA 学習も視野に入ります。RunPod や Vast.ai の RTX 4090($0.34〜$0.40/hr)が最もコスパが高いです。
1 時間で $0.40 として、1 日 2 時間使っても月 $24(約 3,600 円)です。自宅に GPU を買う(RTX 4090 は約 30 万円)よりはるかに安い選択肢です。
②LLM 推論(Ollama・vLLM・llama.cpp)
70B モデルを 4bit 量子化で動かすには 40〜48 GB の VRAM が必要です。RTX 4090(24GB)では 13B 〜 30B が上限です。70B を快適に動かすなら A100 80GB(Vast.ai で $0.84/hr〜)または H100 SXM($2.00/hr〜) を選びましょう。
③ファインチューニング・強化学習
Llama-3 70B の LoRA ファインチューニングには H100 SXM × 1〜2 枚が現実的です。RunPod(from $1.99/hr)か Vast.ai($2.00/hr 中央値)を利用し、学習が終わったら即停止するのが最も費用を抑えられます。
④商用・本番 API サービス
SLA・セキュリティ・スケールアウト自動化が必要な場合は Lambda Labs(予約枠)か AWS EC2 が選択肢になります。コストは RunPod/Vast.ai の 2〜5 倍になりますが、稼働保証・監視・IAM などのエンタープライズ機能が使えます。
サーバー代を抑えるヒント
- 推論 API の Web サーバー部分(FastAPI・Nginx)は GPU インスタンスではなく VPS で動かすと大幅に安くなる
- Vultr の $6/月プランでも Nginx + FastAPI のリバースプロキシは動く。GPU インスタンスへのプロキシ設定で月コストを最適化できる
- RunPod には Serverless(API エンドポイント)機能もあり、推論時だけ GPU を使う構成が作れる
RunPod の始め方(5分でGPU起動)
手順1:アカウント作成とクレジット追加
runpod.io にアクセスしてメールアドレスでアカウントを作成します。クレジットは $10 から購入可能(クレジットカード決済)。$10 あれば RTX 4090 を約 29 時間使えます。
手順2:GPU インスタンスを選ぶ
「Deploy」→「GPU Cloud」から GPU タイプを選択します。Filter by GPU で RTX 4090 と入力すると候補が絞り込まれます。
手順3:テンプレートを選択して起動
用途に合わせてテンプレートを選択します。
- PyTorch:
runpod/pytorch:2.4.0-py3.11-cuda12.4.1-devel-ubuntu22.04 - Stable Diffusion:
runpod/stable-diffusion:latest - カスタム:任意の Docker イメージ(Docker Hub 対応)
「Deploy On-Demand」をクリックすると 1〜3 分でインスタンスが起動します。SSH 接続または JupyterLab 経由でアクセスできます。
+—————————————————————————–+
| NVIDIA-SMI 550.xx.xx Driver Version: 550.xx.xx CUDA Version: 12.4 |
+——————————-+———————-+———————-+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
+===============================+======================+======================+
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | N/A |
| 0% 38C P8 28W / 450W | 0MiB / 24576MiB | 0% Default |
+—————————————————————————–+
停止忘れに注意
GPU インスタンスは起動中は常に課金されます。使い終わったら必ずインスタンスを停止(Stop)または削除(Terminate)してください。RunPod にはコスト上限アラートも設定できるので活用しましょう。
まとめ
クラウドGPU 4 社を実データで比較した結果をまとめます。
まとめ
- 個人の画像生成・LLM 推論には RunPod(RTX 4090 from $0.34/hr)か Vast.ai($0.40/hr 中央)が最安
- A100 80GB が必要なら Vast.ai の $0.84/hr(中央値)が割安。RunPod より選択肢が多い
- AWS は個人利用には割高だが、SLA・VPC・IAM が必要な商用サービスには適している
- Lambda Labs は研究者向けで安定稼働が強み。料金はプログラム取得不可のため公式で要確認
- GPU インスタンスの隣に Vultr などの安価な VPS を置くと、Web サーバー代を節約できる
GPU クラウドを使い始めるなら、まず RunPod で $10 のクレジットを入れて RTX 4090 で Ollama を動かしてみるのがおすすめです。「GPU がある環境」の快適さを実感してから、長期利用かどうかを判断するのが賢い使い方です。


コメント