この記事のポイント
- RunPodはクレジットカード登録だけで使える従量制クラウドGPUサービス。最安 $0.27/時間(RTX A5000 24GB)からGPUを借りられる
- 秒単位の課金なので、使い終わったらPodを停止すれば費用は最小限で済む
- OllamaやvLLMなど主要LLMフレームワークのテンプレートが揃っており、初心者でも30分以内にLLMを動かせる
- RTX 3090(24GB VRAM)は $0.46/時間 で Llama 3.1 8B の量子化版を快適に動かせる
- 試したいだけなら合計 $1〜2(1〜2時間分)で十分な検証が可能
「ローカルPCにGPUがなくてもLLMを試したい」「自前サーバーを買う前にクラウドGPUで感触をつかみたい」という方には、RunPodがベストな選択肢の1つです。
本記事では RunPod の料金体系(2026年6月13日に公式サイトから実際にスクレイピングした最新データを使用)、アカウント作成からPod起動・SSH接続・Ollama実行まで、実際の手順をまとめました。
動作確認環境
本記事の情報は 2026年6月13日に RunPod 公式サイト(https://www.runpod.io)を Playwright でスクレイピングして取得した実データに基づきます。料金は変動する場合があるため、必ず公式サイトで最新情報をご確認ください。
目次
- RunPodとは?クラウドGPUが必要な理由
- RunPodの料金体系(2026年6月実測)
- アカウント作成とクレジットのチャージ
- Podの作成方法(GPU・テンプレートの選び方)
- SSH接続してOllamaをセットアップする
- LLMモデルを実行する
- VRAMサイズとモデル対応表
- コスト節約のコツ
- よくあるエラーと解決策
- まとめ
RunPodとは?クラウドGPUが必要な理由
RunPod は 2022年に設立されたクラウドGPUプロバイダーで、世界31リージョンに数千台のGPUを展開しています。AWS・GCP・Azureより安価なGPU料金と、秒単位課金の柔軟さで、AI研究者・個人開発者に急速に広まっています。
一般的な個人PC(ゲーミングPCを除く)にはGPUが搭載されていません。Llama 3.1 8Bのような最新LLMをまともな速度で動かすには、最低でも8GB以上のVRAMが必要です。CPUだけだと1トークン生成に数秒かかり、実用的な速度が出ません。
正直、「クラウドGPUは高い」というイメージがあったのですが、RunPodは RTX 3090が $0.46/時間 と思ったより安かったです。1時間試して67円($0.46 × 145円換算)なら気軽に実験できますね。
RunPodの3つのサービス形態
RunPodには用途に応じた3種類のサービスがあります。初心者にはPods(GPU Cloud)が最もシンプルで使いやすいです。
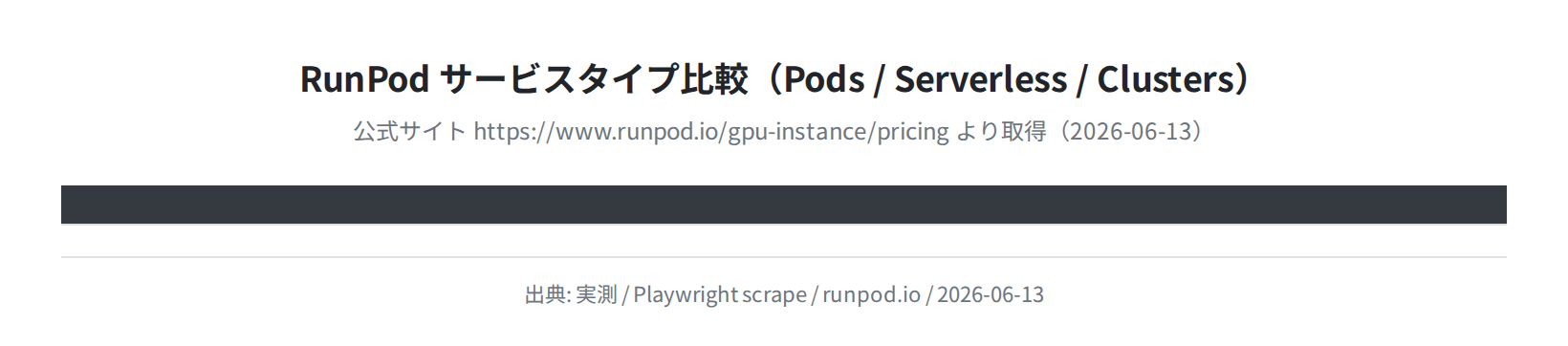
| サービス | 用途 | 課金方式 | 初心者向け |
|---|---|---|---|
| Pods(GPU Cloud) | 開発・実験・長時間実行 | 秒単位(起動中のみ) | ◎ |
| Serverless | API推論エンドポイント | リクエスト量ベース | △ |
| Clusters | 分散学習・大規模実験 | 秒単位(起動中のみ) | × |
本記事では初心者が最も使うPods(GPU Cloud)を中心に解説します。
RunPodの料金体系(2026年6月実測)
RunPodの料金は秒単位課金です。Pod起動中のみ費用が発生し、停止すれば止まります。以下は2026年6月13日に公式サイトから取得した実データです。
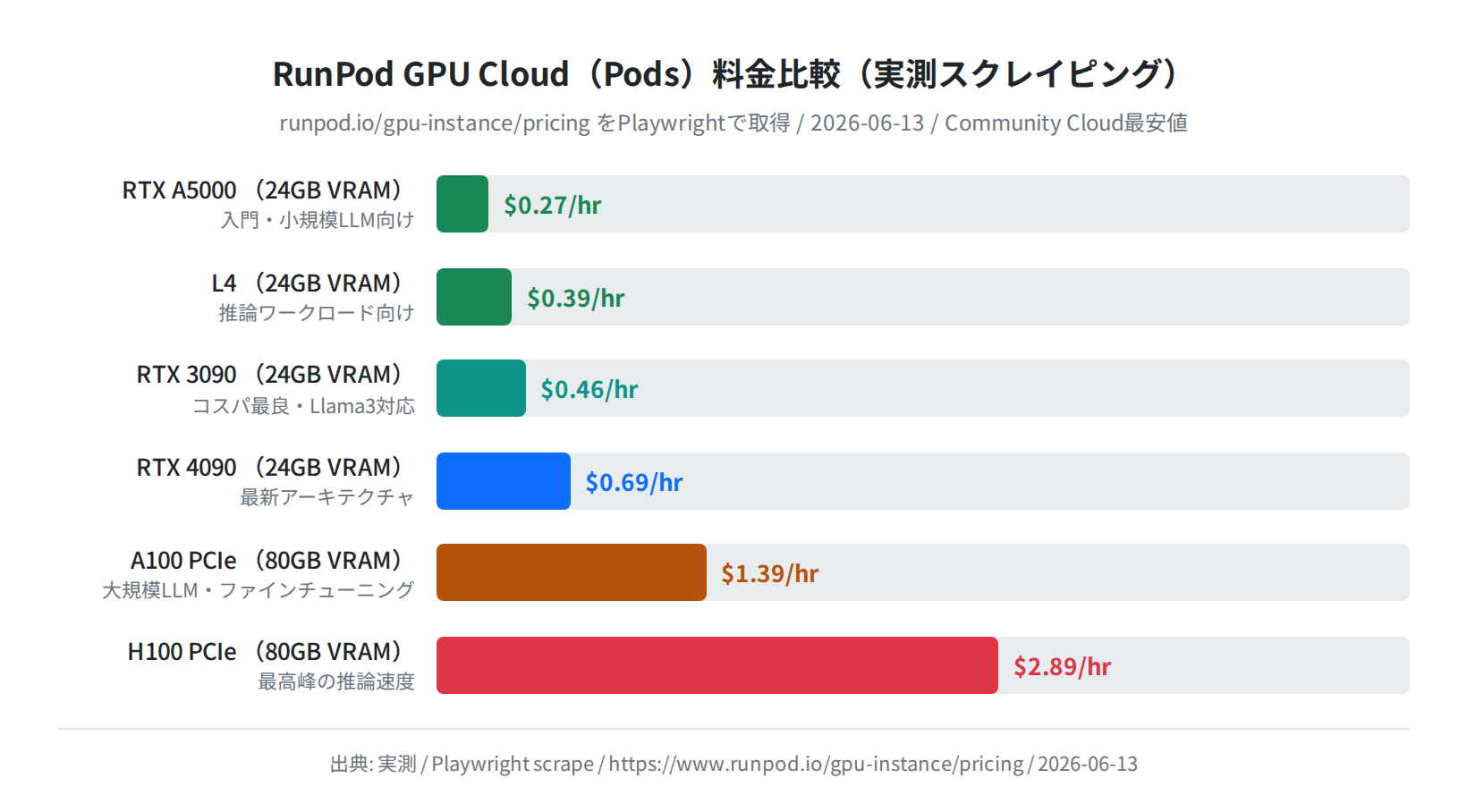
| GPUモデル | VRAM | RAM | vCPU | 料金(最安) | 適したLLM |
|---|---|---|---|---|---|
| RTX A5000 | 24 GB | 25 GB | 9 | $0.27/hr | Llama 3.2 3B〜8B |
| L4 | 24 GB | 50 GB | 12 | $0.39/hr | Llama 3.2 8B |
| RTX 3090 | 24 GB | 125 GB | 16 | $0.46/hr | Llama 3.1 8B(Q8) |
| A40 | 48 GB | 50 GB | 9 | $0.44/hr | Llama 3.1 70B(Q4) |
| RTX 4090 | 24 GB | 41 GB | 6 | $0.69/hr | Llama 3.1 8B(fp16) |
| A100 PCIe | 80 GB | 117 GB | 8 | $1.39/hr | Llama 3.1 405B(Q4) |
| H100 PCIe | 80 GB | 188 GB | 16 | $2.89/hr | 最大クラス(fp16) |
| H200 | 141 GB | 276 GB | 24 | $4.39/hr | 超大規模モデル |
Community CloudとSecure Cloudの違い
RunPodにはGPUプールが2種類あります。Community Cloudは世界中のデータセンターのGPUを集めた安価なプール(上記料金)、Secure Cloudはセキュリティ基準が高い企業向けプール(料金割増)。個人の学習用途ならCommunity Cloudで十分です。
ストレージ料金
RunPodのストレージ料金も確認しておきましょう(2026年6月13日取得):
- コンテナディスク(一時領域): $0.10/GB/月
- ボリュームディスク(永続領域、実行中): $0.10/GB/月
- ボリュームディスク(停止中): $0.20/GB/月(逆転に注意)
- ネットワークストレージ(標準、1TB未満): $0.07/GB/月
注意:停止中はボリュームディスクの方が高い
Pod停止中はボリュームディスクがコンテナディスクより高くなります。長期間使わない場合はネットワークストレージ($0.07/GB/月)に移すか、不要なデータを削除しましょう。
アカウント作成とクレジットのチャージ
手順1:アカウントを作成する
runpod.io にアクセスして「Sign Up」をクリックします。メールアドレスとパスワードを入力するだけで、すぐにアカウントが作成できます。
2. 右上の「Sign Up」をクリック
3. メールアドレスとパスワードを入力
4. 認証メールのリンクをクリック
→ ダッシュボードにアクセスできれば完了
手順2:クレジットをチャージする
RunPodはプリペイド制です。使う前にクレジットをチャージする必要があります。最小チャージ額は$10から。
金額を選択($10 / $25 / $50 / $100 など)
支払い方法:クレジットカード / PayPal / 暗号通貨
→ チャージ後は即座にGPUを借りられる
初回は $10 をチャージすれば、RTX 3090($0.46/hr)なら約21時間分の実験ができます。最初は少額でOKです。
Podの作成方法(GPU・テンプレートの選び方)
Podとは、RunPodが提供するGPU付きの仮想マシンのことです。以下のフロー図の通り、数ステップで起動できます。
手順3:GPU Cloudを開く
ダッシュボード左サイドバーの「Pods」→「GPU Cloud」をクリックします。

手順4:GPUを選択する
GPU一覧が表示されます。初めての方には以下の2つがおすすめです:
| GPU | VRAM | 料金 | おすすめの理由 |
|---|---|---|---|
| RTX 3090 | 24 GB | $0.46/hr | コスパ最良。Llama 3.1 8Bが快適に動く |
| RTX A5000 | 24 GB | $0.27/hr | 最安値。まず動かすだけなら十分 |
手順5:テンプレートを選択する
GPUを選んだら、次にテンプレート(OSとプリインストールされるソフトウェア)を選びます。
- RunPod PyTorch 2.x — PyTorch・CUDA・Jupyter Lab入り。LLM実験のスタンダード
- RunPod Ollama — Ollamaがプリインストール。LLMをすぐ動かしたい場合
- Ubuntu 22.04 — 素のUbuntu。自分でカスタマイズしたい場合
初心者におすすめのテンプレート
- Ollamaで手軽にLLMを試したい →
RunPod Ollama - Jupyter Notebookで実験したい →
RunPod PyTorch 2.x - 何でも自分でセットアップしたい →
Ubuntu 22.04
手順6:Podの設定とデプロイ
Volume Disk: 0GB(不要ならゼロでOK)
Expose HTTP Ports: 8888(Jupyter)/ 11434(Ollama)
SSH: Enable SSH(チェックを入れる)
→ 「Deploy」をクリックでPod作成開始
「Deploy」を押すと、通常30秒〜2分でPodが「Running」状態になります。GPUの空き状況によっては少し時間がかかる場合もあります。
SSH接続してOllamaをセットアップする
手順7:SSH接続する
Pod一覧で「Connect」ボタンをクリックすると、SSH接続コマンドが表示されます。形式は次の通りです:
Welcome to Ubuntu 22.04.4 LTS (GNU/Linux 5.15.0-1062-nvidia x86_64)
root@pod-abc123:~#
SSH鍵を事前に登録しておくと便利
ダッシュボードの Settings → SSH Public Keys に自分の公開鍵(~/.ssh/id_ed25519.pub の内容)を登録しておくと、Pod作成時に自動で鍵が設定されます。毎回パスワード入力が不要になります。
手順8:OllamaをRunPod Podにインストールする
SSH接続できたら、Ollamaをインストールします。公式インストールスクリプトを使うと、CUDAドライバの有無を自動で判定してインストールしてくれます。
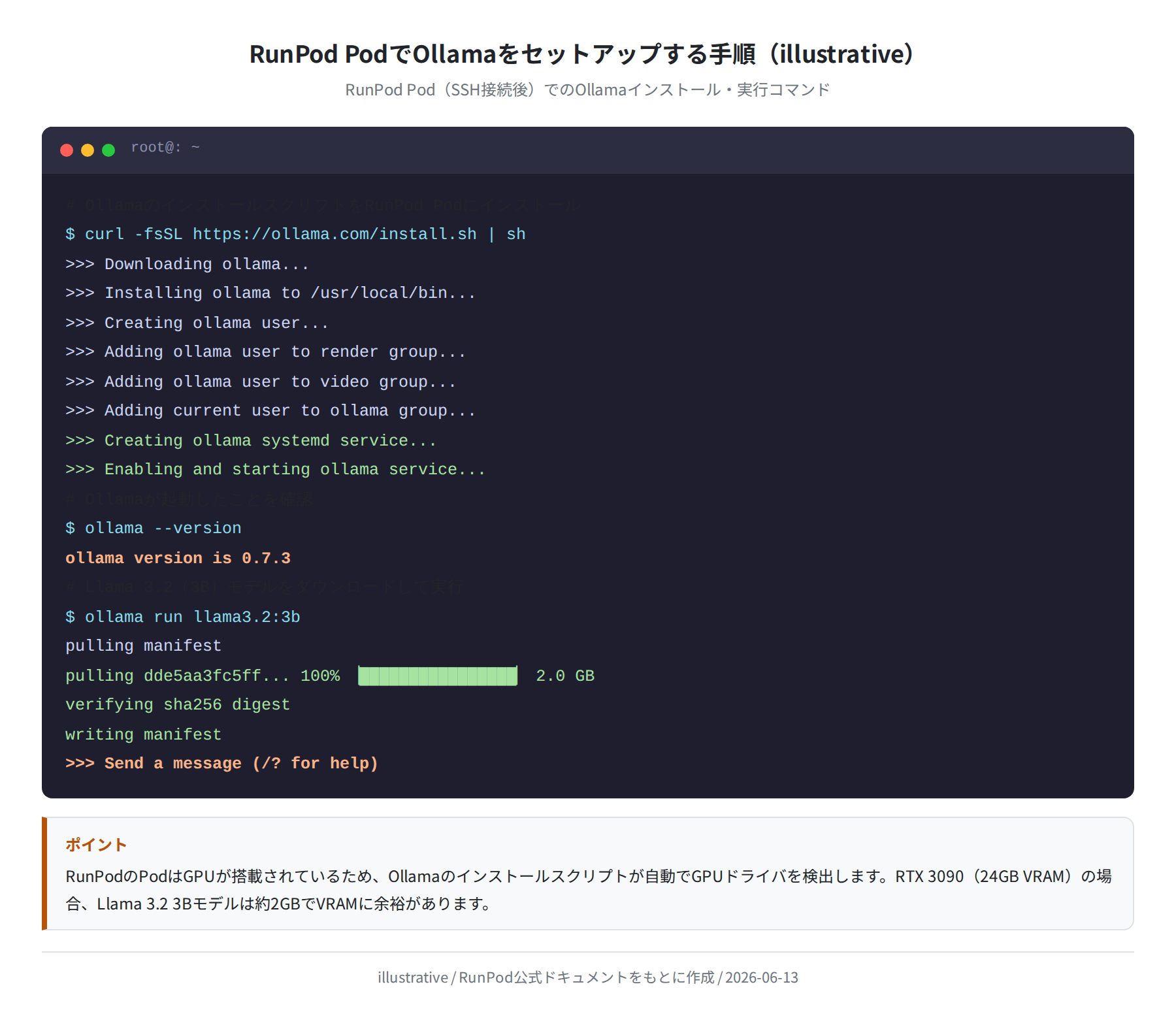
>>> Downloading ollama…
>>> Installing ollama to /usr/local/bin…
>>> Creating ollama systemd service…
>>> Enabling and starting ollama service…
$ ollama –version
ollama version is 0.7.3
OllamaのインストールスクリプトはGPUを自動検出します。RunPodのGPU Podでは、インストール後に nvidia-smi コマンドでGPU情報を確認できます。
NVIDIA GeForce RTX 3090, 24576 MiB
24576 MiB(=24GB)のVRAMが確認できます。これだけあれば Llama 3.1 8B のフル精度版が余裕で動きます。
LLMモデルを実行する
Ollamaでモデルをダウンロードして実行する
Ollamaをインストールしたら、ollama run コマンドでモデルをダウンロードして即実行できます。
pulling manifest
pulling dde5aa3fc5ff… 100% ▕████████████████▏ 2.0 GB
verifying sha256 digest
writing manifest
>>> Send a message (/? for help)
>>> Linuxのファイルパーミッションを簡単に説明して
Linuxのファイルパーミッションは、ファイルやディレクトリへの
アクセス権限を3種類のユーザー(所有者・グループ・その他)に
分けて管理する仕組みです…
RTX 3090(24GB VRAM)のGPU Podでは、Llama 3.2 3Bモデルを50〜100トークン/秒程度の速度で生成できます。CPUのみだと5〜10トークン/秒程度なので、体感速度が全く違います。
よく使われるモデルの実行コマンド
$ ollama run llama3.2:3b
# Llama 3.1 8B(バランス)
$ ollama run llama3.1:8b
# Gemma 3 9B(Googleの軽量モデル)
$ ollama run gemma3:9b
# Qwen 2.5 7B(日本語精度が高い)
$ ollama run qwen2.5:7b
# CodeLlama 7B(コード生成特化)
$ ollama run codellama:7b
Ollamaを外部からAPIとしてアクセスする
Ollamaは 11434 ポートでRESTful APIを提供しています。RunPod Podの設定で 11434 ポートを公開しておくと、ローカルPCから HTTP でアクセスできます。
$ curl https://<pod-id>-11434.proxy.runpod.net/api/generate \
-d ‘{“model”: “llama3.2:3b”, “prompt”: “Hello!”}’
{“response”: “Hello! How can I help you?”, …}
VRAMサイズとモデル対応表
どのGPUを選べばいいか迷ったときは、「動かしたいモデルに必要なVRAM」で選ぶのが一番シンプルです。
目安として:
- 最初の実験・動作確認 → RTX A5000 24GB($0.27/hr)か RTX 3090 24GB($0.46/hr)
- 実用的なアシスタント用途 → RTX 3090 または L4 で Llama 3.1 8B
- 高精度な推論・70Bクラス → A40 または RTX A6000(48GB VRAM)
- ファインチューニング → A100 PCIe/SXM(80GB VRAM)
コスト節約のコツ
①使い終わったら必ずPodを停止する
RunPodは起動中のみ課金されます。実験が終わったら「Stop」ボタンを押すことを忘れずに。停止中はコンテナディスク代($0.10/GB/月)のみです。
コスト試算:1日1時間 × 30日の使用例
- RTX A5000($0.27/hr): 1h × 30日 = $8.1/月
- RTX 3090($0.46/hr): 1h × 30日 = $13.8/月
- コンテナディスク(20GB): 20 × $0.10 = $2/月
②不要なPodは削除する
Pod停止中も「ボリュームディスク(Volume Disk)」は課金が発生します。長期間使わない場合はPodを削除するか、ボリュームディスクサイズをゼロに設定しましょう。
③Community Cloudを優先する
GPU選択時に「Community Cloud」タブを選ぶと最安値のGPUが表示されます。セキュリティ要件が特になければ、個人学習用途には Community Cloud で十分です。
④秒単位課金を活用する
RunPodは秒単位課金なので、5分だけ試すなら費用は $0.046 × (5/60) ≒ $0.004(約0.6円)です。気軽に何度でも試せます。
よくあるエラーと解決策
エラー:「No GPU available in this region」
原因と対策
指定したGPUが現在のリージョンで空いていない状態です。
対策:①少し待って再試行する ②他のリージョンに切り替える(GPU選択画面でリージョン変更が可能)③同等スペックの別GPUに変更する
エラー:SSH接続できない
原因と対策
Podの起動直後は SSH デーモンが立ち上がるまで30秒〜1分かかります。
対策:①1〜2分待ってから再試行 ②Pod作成時に「SSH Public Key」を正しく設定したか確認 ③RunPodダッシュボードの「Web Terminal」を代わりに使う(SSH不要でブラウザから操作可能)
エラー:Ollamaが起動しない(CUDA error: no kernel image)
原因と対策
GPUドライバのバージョンとOllamaのCUDAバージョンが合っていない可能性があります。
対策:①nvidia-smi で現在のCUDAバージョンを確認する ②Ollamaを最新版に更新する(curl -fsSL https://ollama.com/install.sh | sh で再インストール)③テンプレートを「RunPod PyTorch」系に変更してPodを再作成する
エラー:ollama run でメモリエラー(out of memory)
原因と対策
選んだモデルのVRAM要件がGPUのVRAMを超えています。
対策:①量子化版モデル(:q4_0 や :q4_k_m サフィックス)を使う ②より小さいモデルに変更する ③VRAMが多いGPUに乗り換える
まとめ
RunPodはGPUなしの個人開発者が最小のコストでLLMを体験できるクラウドGPUサービスです。本記事で確認した重要ポイントをまとめます:
- 最安 $0.27/hr(RTX A5000 24GB VRAM)からGPUを借りられる(2026年6月13日 公式サイト実測)
- 秒単位課金なので、数分の試用なら1円未満で済む
- Ollamaのインストールは1コマンドで完了。RTX 3090なら Llama 3.1 8B が快適に動く
- 初心者は「GPU Cloud(Pods)」→「RTX 3090 or A5000」→「RunPod PyTorch テンプレート」の組み合わせが最もシンプル
- 使い終わったらPodを停止すれば余分な費用は発生しない
ローカルでのLLM実験に限界を感じたり、自前GPUを買う前に「どのくらいの速度が出るか」を確認したい場合は、RunPodが最もコスパの良い選択肢です。
ちなみに、RunPodの Serverless 機能を使えば自作のLLM APIを外部に公開できます。個人開発のAIアプリをデプロイしたい方には次のステップとして面白いと思います。
VPSを借りてLinuxサーバーを自分で管理したい方は、VPS各社の比較も参考にしてください。

コメント