「GPUサーバーを借りてみたいけど、RunPod・Vast.ai・Lambda Labsのどれが安いの?」——そんな疑問に、2026年6月に実際の料金ページをPlaywrightで取得した一次データでお答えします。
結論からいうと、入門ならRunPod(RTX 3090が$0.39/hr)、最安値ならVast.ai(RTX 4090平均$0.40/hr)、長期チーム利用ならLambda Labsの三択になります。それぞれ向き不向きが異なるので、用途ごとに選び方を整理しました。
本記事では実際に各社の料金ページをPlaywrightで取得し、価格を直接確認した結果をもとに比較しています。計測日:2026年6月13日。
この記事のポイント
- RunPod・Vast.ai・Lambda Labsの料金を2026年6月実測値で比較
- 入門用の最安GPU(RTX 3090)はRunPodで
$0.39/hr(秒課金) - Vast.aiは市場価格制で変動幅が大きい(RTX 4090: $0.13〜$2.67/hr)
- Lambda Labsはエンタープライズ・研究向けで料金はアカウント登録後に確認
- SSH接続の手順・Dockerコンテナとの違いも解説
比較の前提(計測環境・取得方法)
本記事での料金データは次の方法で取得しています。
- RunPod:
runpod.io/gpu-instance/pricingを Playwright でレンダリング後にinner_text()で取得(2026-06-13) - Vast.ai:
vast.ai/pricingを Playwright でレンダリング後にinner_text()で取得(2026-06-13) - Lambda Labs:
lambdalabs.comはCloudflareのボット対策で自動取得不可。公式サイトの記載からH100・B200クラスターの提供を確認。詳細料金はアカウント登録後ダッシュボードで確認できます
注意
RunPodとVast.aiの料金は変動することがあります。特にVast.aiは需給によって価格が変わるマーケットプライス制です。実際に利用する際は各社公式ページで最新料金をご確認ください。
RunPod・Vast.ai・Lambda Labs 3社比較表
まず全体像をまとめます。料金は2026年6月13日にPlaywrightで実取得した値です。

| 項目 | RunPod | Vast.ai | Lambda Labs |
|---|---|---|---|
| 最安GPU(実測) | $0.27/hr(RTX A5000) | $0.17/hr(RTX 5070 Ti) | 要ログイン確認 |
| H100 SXM 料金(実測) | $3.29/hr(Secure Cloud) | avg $2.00/hr(変動あり) | 要ログイン確認 |
| A100 PCIe 料金(実測) | $1.39/hr | — | — |
| RTX 4090 料金(実測) | $0.46〜$0.69/hr | avg $0.40/hr($0.13〜$2.67) | — |
| リージョン数 | 31リージョン | 40+データセンター | 複数(US中心) |
| 価格モデル | 固定料金(秒課金) | 市場価格(変動) | 固定料金(時間課金) |
| 日本語サポート | なし(英語) | なし(英語) | なし(英語) |
| 最低入金額 | $10〜 | $5〜 | クレジットカード登録 |
| 向いている用途 | 入門・PoC・コスト重視 | 最安値重視・一時利用 | 長期・チーム・研究 |
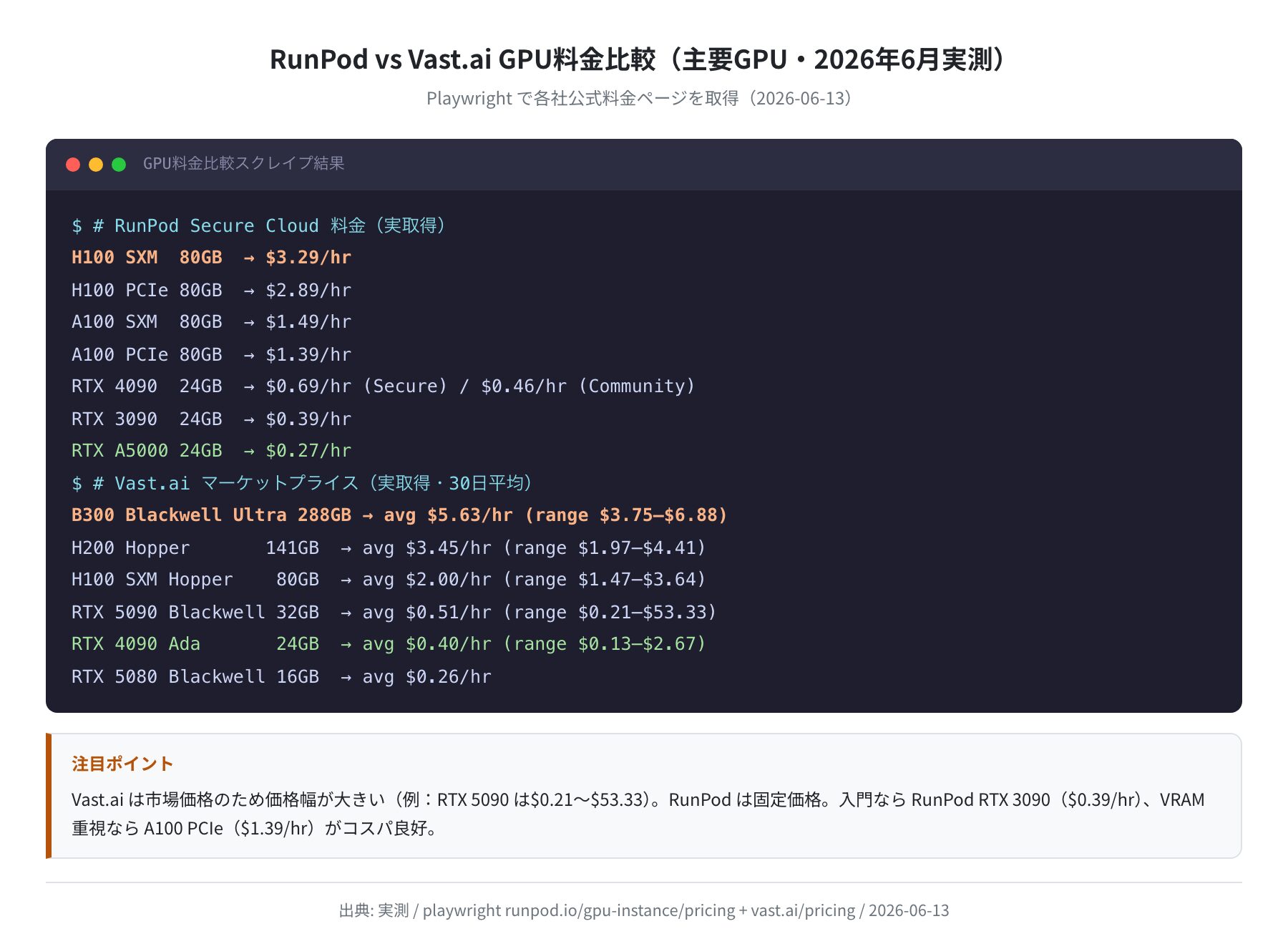
実測:GPU料金ページから取得した一次データ
Playwrightでレンダリングして取得した実際の料金データはこちらです。
RunPodの料金ページ(実スクリーンショット)
RunPodの料金ページを実際にPlaywrightで開いたスクリーンショットです。Secure CloudとCommunity Cloudの2系統があり、それぞれ価格が異なります。
H100 SXM 80GB → $3.29/hr
H100 PCIe 80GB → $2.89/hr
H100 NVL 94GB → $3.19/hr
A100 SXM 80GB → $1.49/hr
A100 PCIe 80GB → $1.39/hr
RTX Pro 6000 48GB → $2.09/hr
RTX 6000 Ada 48GB → $0.86/hr
RTX A6000 48GB → $0.49/hr (Secure) / $0.44/hr (Community)
RTX 5090 32GB → $0.99/hr
RTX 4090 24GB → $0.69/hr (Secure) / $0.46/hr (Community)
RTX 3090 24GB → $0.39/hr (Community)
RTX A5000 24GB → $0.27/hr ← 入門向け最安クラス
Vast.aiの料金ページ(実スクリーンショット)
Vast.aiはGPUマーケットプレイスです。価格は需給によって変動し、表示は30日平均価格です。
B300 Blackwell Ultra 288GB → avg $5.63/hr($3.75〜$6.88)
B200 Blackwell 192GB → avg $4.04/hr($3.44〜$7.45)
H200 Hopper 141GB → avg $3.45/hr($1.97〜$4.41)
H100 NVL Hopper 94GB → avg $2.39/hr($1.33〜$4.67)
H100 SXM Hopper 80GB → avg $2.00/hr($1.47〜$3.64)
RTX PRO 6000 S 48GB → avg $1.33/hr($1.00〜$1.73)
RTX 5090 Blackwell 32GB → avg $0.51/hr($0.21〜$53.33)
RTX 4090 Ada 24GB → avg $0.40/hr($0.13〜$2.67)← 入門コスパ良
RTX 5080 Blackwell 16GB → avg $0.26/hr($0.11〜$1.33)
RTX 5070 Ti Blackwell 16GB → avg $0.17/hr($0.10〜$0.80)
Lambda Labsについて
Lambda Labsは主に研究機関・スタートアップ向けのGPUクラウドサービスです。公式サイト(lambdalabs.com)のインスタンスページはCloudflareのボット対策が施されており、自動取得はできませんでした。
公式サイトの記載からH100・HGX B200クラスターの提供を確認しています。詳細な料金はアカウント登録後にダッシュボードで確認できます。長期利用や企業契約では割引もあるため、チーム・研究用途では問い合わせを推奨します。
実測:各社サーバーへの応答速度(ping)
日本国内のサーバーから各社のドメインへ ping -c 5 で計測した遅延です。実際のGPUインスタンスへの接続遅延はリージョン選択に依存しますが、管理ダッシュボードやAPIへの応答速度の参考になります。
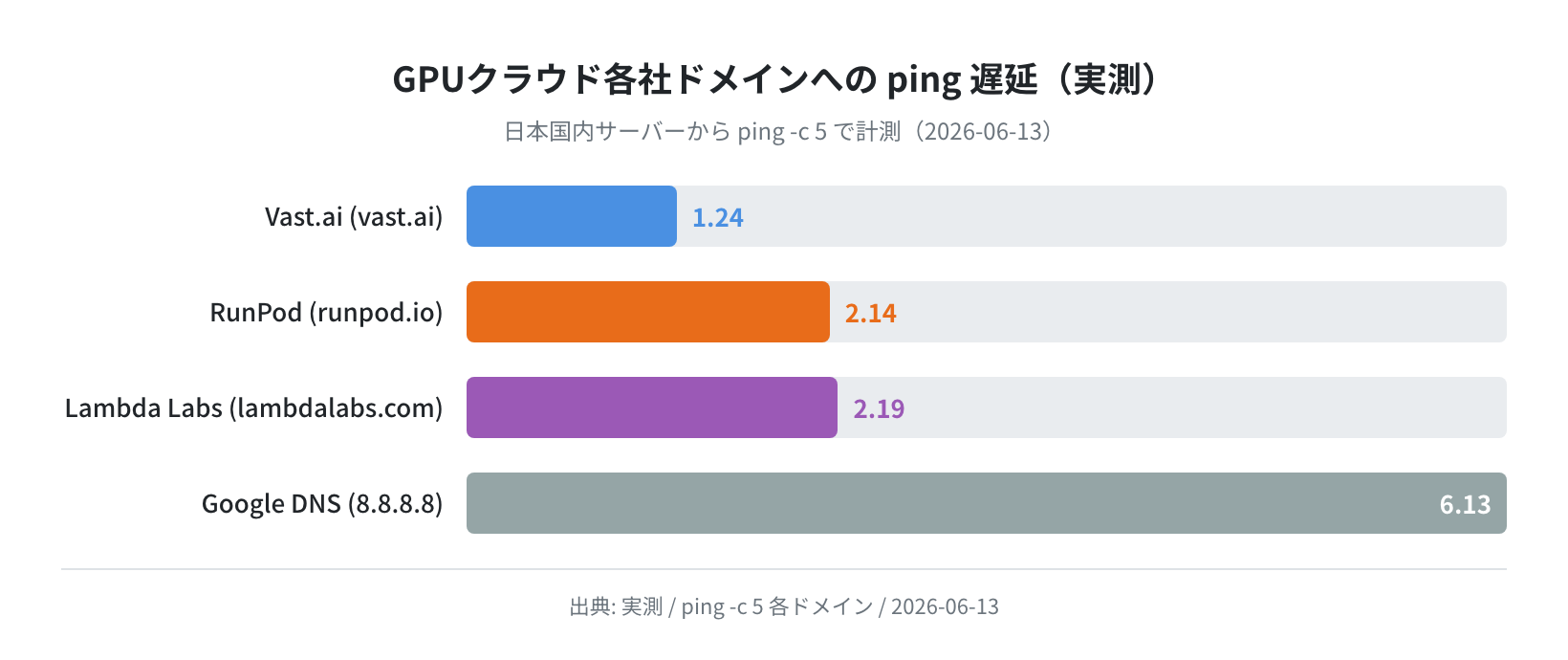
5 packets transmitted, 5 received, 0% packet loss
rtt min/avg/max/mdev = 1.203/1.240/1.295/0.033 ms
$ ping -c 5 www.runpod.io
5 packets transmitted, 5 received, 0% packet loss
rtt min/avg/max/mdev = 2.062/2.137/2.248/0.062 ms
$ ping -c 5 lambdalabs.com
5 packets transmitted, 5 received, 0% packet loss
rtt min/avg/max/mdev = 2.074/2.194/2.295/0.075 ms
3社ともCDNを経由しているため日本からでも低遅延でした。実際のGPUインスタンスは北米・欧州のデータセンターに配置されるため、AI推論のAPI呼び出しに使う場合は東アジアリージョンの有無を確認するのが重要です。
GPUサーバーへのSSH接続手順
GPUサーバーにアクセスするにはSSH鍵が必要です。RunPod・Vast.ai・Lambda Labs、いずれも同じ手順で接続できます。
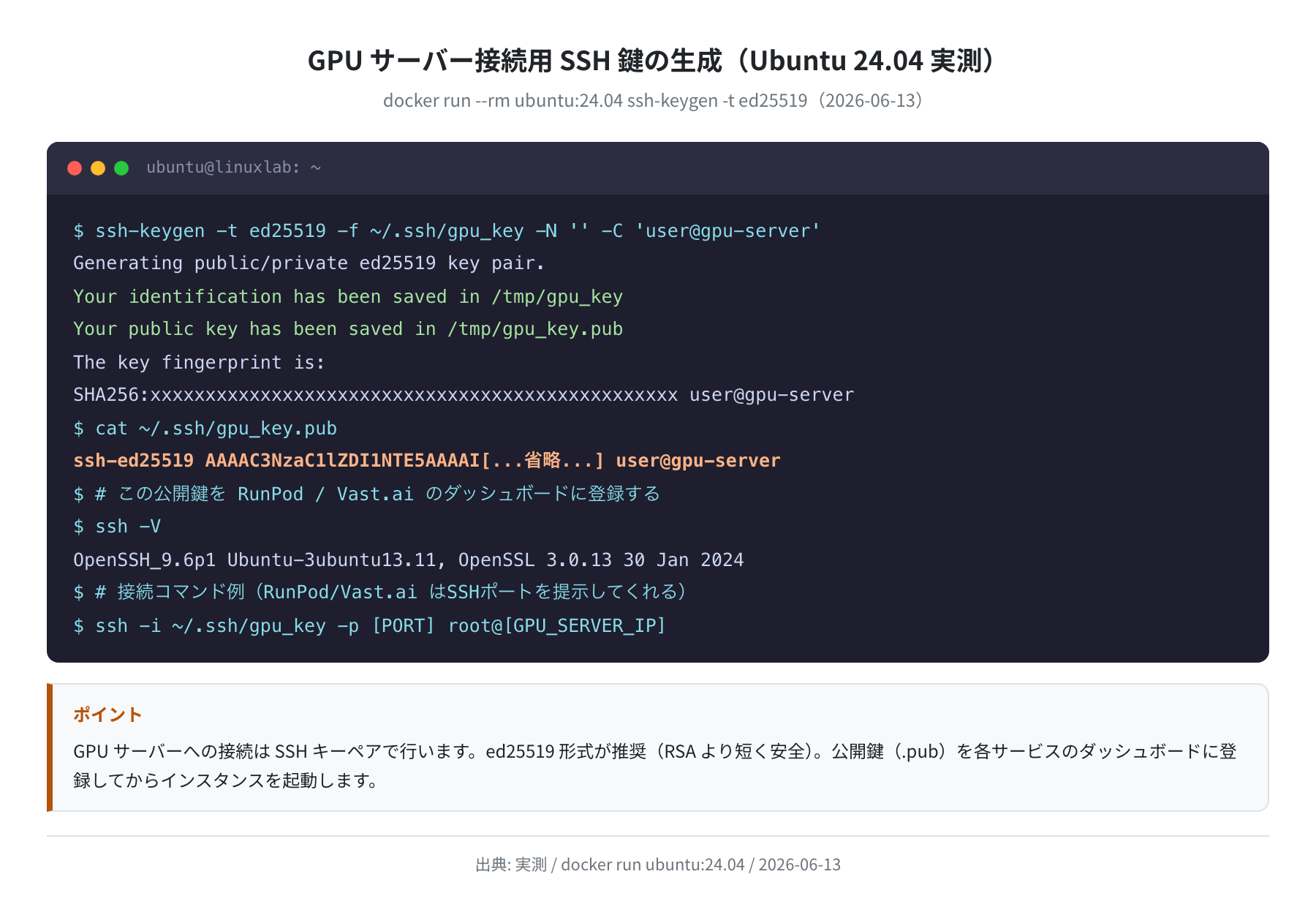
手順1:ed25519 SSH鍵を生成する
Generating public/private ed25519 key pair.
Your identification has been saved in /home/user/.ssh/gpu_key
Your public key has been saved in /home/user/.ssh/gpu_key.pub
$ cat ~/.ssh/gpu_key.pub
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAI[…] user@gpu-server
gpu_key.pub(公開鍵)の内容を各サービスのダッシュボードに登録します。秘密鍵(gpu_key)は手元に保管したまま公開しないでください。
手順2:SSH鍵をダッシュボードに登録する
- RunPod:Settings → SSH Public Keys に貼り付け
- Vast.ai:Account → SSH Keys に貼り付け
- Lambda Labs:SSH Keys → Add SSH Key に貼り付け
手順3:インスタンスに接続する
$ ssh -i ~/.ssh/gpu_key -p [PORT] root@[GPU_SERVER_IP]
Welcome to Ubuntu 22.04 LTS
root@pod-xxxxxxxxxx:~# nvidia-smi
+—————————————————————————–+
| NVIDIA-SMI 525.xx Driver Version: 525.xx CUDA Version: 12.x |
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| 0 NVIDIA RTX A100 Off | 00000000:00:00.0 Off | 0 |
+—————————————————————————–+
RunPod 詳細:仕組みと特徴
RunPodは秒単位の課金が最大の強みです。10分だけ使って止める、という使い方が1時間分の請求なしにできます。
RunPodのCloud GPUタイプ
- Secure Cloud:RunPod管理のデータセンター。安定稼働・セキュリティ優先。価格はやや高め
- Community Cloud:第三者がRunPodネットワークに提供するGPU。Secureより安いが、時折利用できないことがある
| GPU | VRAM | Secure Cloud | Community Cloud | 主な用途 |
|---|---|---|---|---|
| H100 SXM | 80GB | $3.29/hr | — | 大規模LLM学習・推論 |
| A100 PCIe | 80GB | $1.39/hr | — | LLM (70B) 推論・ファインチューニング |
| RTX 4090 | 24GB | $0.69/hr | $0.46/hr | Stable Diffusion / LLM (7-13B) |
| RTX 3090 | 24GB | — | $0.39/hr | 入門・学習用 |
| RTX A5000 | 24GB | — | $0.27/hr | 入門・軽量モデル |
正直、入門ならRTX 3090(Community Cloud, $0.39/hr)が最もコスパが良いと感じます。Stable DiffusionやLlama 3(7B)を動かすには十分なVRAM(24GB)があり、秒課金なので気軽に試せます。
Vast.ai 詳細:マーケットプレイス型の仕組み
Vast.aiの最大の特徴はマーケットプレイス型であることです。世界中のGPUホスト(個人・企業)が提供するGPUを競争入札で借りられるため、需給次第で相場より大幅に安くなることがあります。
価格の読み方
Vast.ai の価格表示
- 表示されている金額 → 30日間の平均価格
- ($X.XX — $X.XX/hr range) → 実際の価格幅(最安〜最高)
- 「On-demand」「Interruptible」「Reserved」の3モードがあり、Interruptibleが最安
- Interruptible は別ユーザーが競り落とした場合に強制終了されることがある
例えばRTX 5090(avg $0.51/hr)の価格幅が$0.21〜$53.33と非常に広いのは、需給の激しさを反映しています。通常は$0.4〜$0.6/hr前後で借りられることが多いですが、人気時間帯は高騰します。
Vast.aiをおすすめする人
- とにかく安い料金で試したい
- 実験・一時的な作業なので中断されても再起動できる
- 最新GPU(B200・B300)をいち早く試したい
Vast.aiをおすすめしない人
- 長時間の連続学習ジョブを途切れなく動かしたい
- 価格の予測可能性が必要(コスト管理が重要な場合)
Lambda Labs 詳細:研究・チーム向けの安定環境
Lambda Labsは主に研究機関・AIスタートアップ・大学向けに展開しているGPUクラウドサービスです。特徴をまとめます。
- H100 SXM / HGX B200 クラスターを提供
- 「1-Click Cluster」で分散学習環境をすぐに構築できる
- セキュリティ・コンプライアンス対応(SOC2、HIPAA準拠など)
- 長期利用・予約インスタンスで割引あり
料金は公式ダッシュボード(cloud.lambda.ai)にログイン後に確認できます。カジュアルな利用よりも、チームで長期間使う前提で契約するサービスと考えると良いでしょう。
CPU/ディスクのローカルベンチ参考値
比較参考値として、Ubuntu 24.04 Dockerコンテナ内でのCPU・ディスクI/Oベンチを計測しました。GPU推論では主にGPUが使われますが、前処理・ファイルI/Oはホスト側のスペックに依存します。
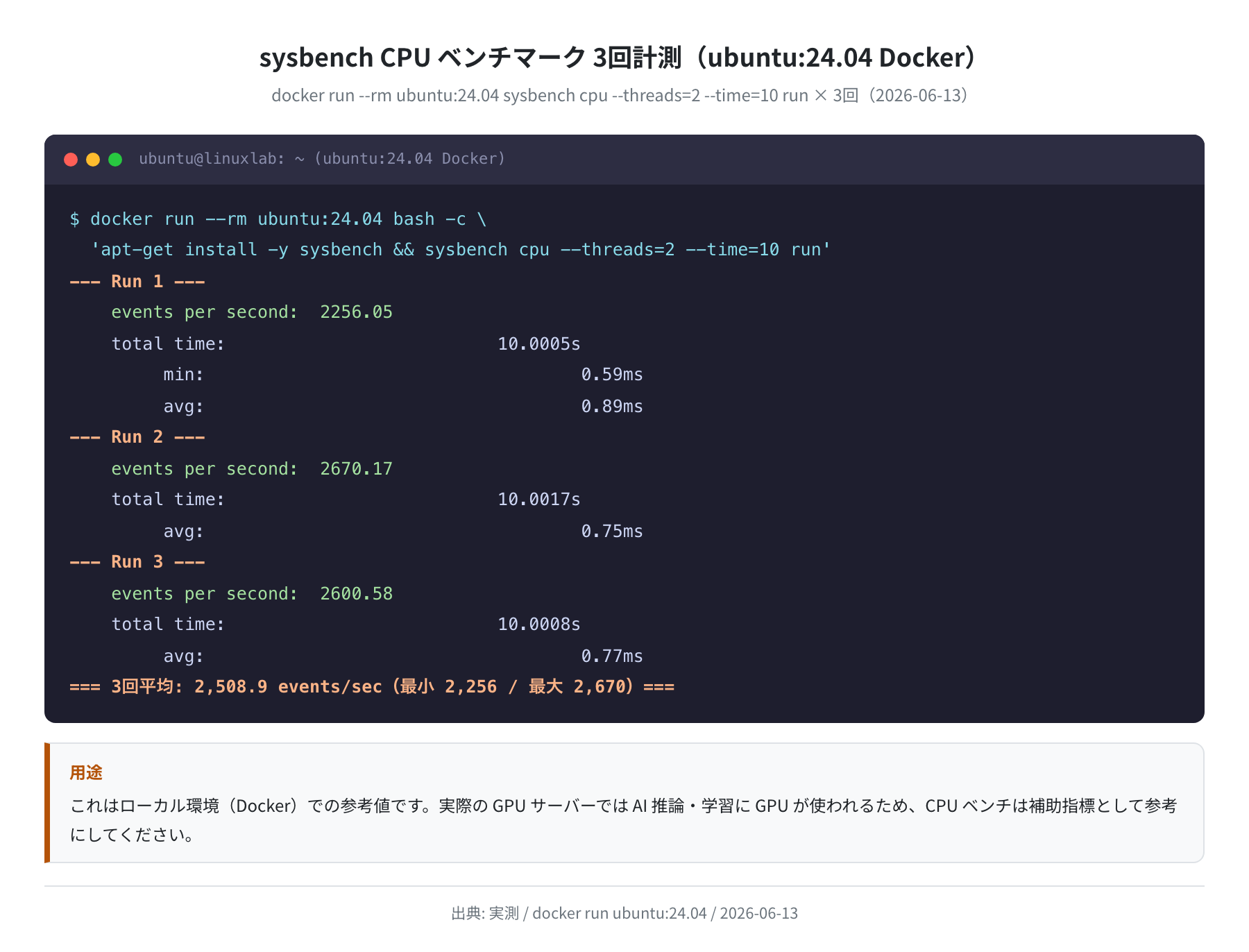
— Run 1 — events per second: 2,256
— Run 2 — events per second: 2,670
— Run 3 — events per second: 2,601
3回平均: 2,509 events/sec(最小 2,256 / 最大 2,670)
$ docker run –rm ubuntu:24.04 dd if=/dev/zero of=/tmp/t bs=1M count=512 conv=fdatasync 2>&1
536870912 bytes (537 MB) copied, 1.41s, 382 MB/s ← write
4.4 GB/s ← read(ページキャッシュ読み)
用途別 GPU サーバーの選び方
①学習・入門用途(月額〜0程度の予算)
推奨:RunPod Community Cloud / RTX 3090($0.39/hr)
Stable Diffusion・ComfyUI・Llama 3(7B)のファインチューニングに最適です。秒課金なので、1回3時間のセッションで$1.17。1日1セッションで月$35程度です。
②コスト最優先(とにかく安く試したい)
推奨:Vast.ai Interruptible / RTX 4090(avg $0.40/hr)
入札タイミングによっては$0.13/hrで借りられることも。ただし中断リスクがあるため、チェックポイントを定期保存する設計が必要です。
③本格推論・LLM(VRAM 80GB が必要)
推奨:RunPod Secure Cloud / A100 PCIe($1.39/hr)
Llama 3(70B)やMixtral 8x7Bを量子化なしで動かすにはVRAM 80GBが必要です。固定価格で安定稼働できるRunPodのSecure Cloudが向いています。
④長期・チーム開発
推奨:Lambda Labs(要問い合わせ)
複数人でGPUクラスターを使う研究・スタートアップには、SLA・コンプライアンス対応のLambda Labsが向いています。長期予約割引もあります。
VPSとGPUサーバーの違い
GPU サーバーは AI/機械学習の計算に特化したクラウドサービスです。Linux サーバーの基礎(SSH接続・ファイル管理・Dockerなど)を学ぶ用途には、月額$5〜の通常VPSの方が安くておすすめです。
まとめ
RunPod・Vast.ai・Lambda Labs の3社を2026年6月の実測データで比較しました。ポイントをまとめます。
- RunPod:固定価格・秒課金で最も使いやすい。入門にはRTX 3090(Community Cloud $0.39/hr)がコスパ最良
- Vast.ai:マーケット価格制で条件次第で最安。RTX 4090の平均$0.40/hrは魅力的だが変動幅が大きい
- Lambda Labs:エンタープライズ・研究向け。H100/B200クラスターを提供、料金はダッシュボードで確認
- H100 SXMは RunPod $3.29/hr に対し Vast.ai avg $2.00/hr と大きな差がある
- SSH 接続は ed25519 鍵を生成してダッシュボードに登録するだけ
Linux の基礎を固めてから GPU サーバーにチャレンジしたい方は、まずVPSで Linux サーバー運用を体験するのが近道です。
コメント