「RunPodとVast.aiとLambdaって、結局どれが速くてコスパがいいの?」――クラウドGPUを使ってLLMや画像生成を試したい人なら一度は悩むポイントです。
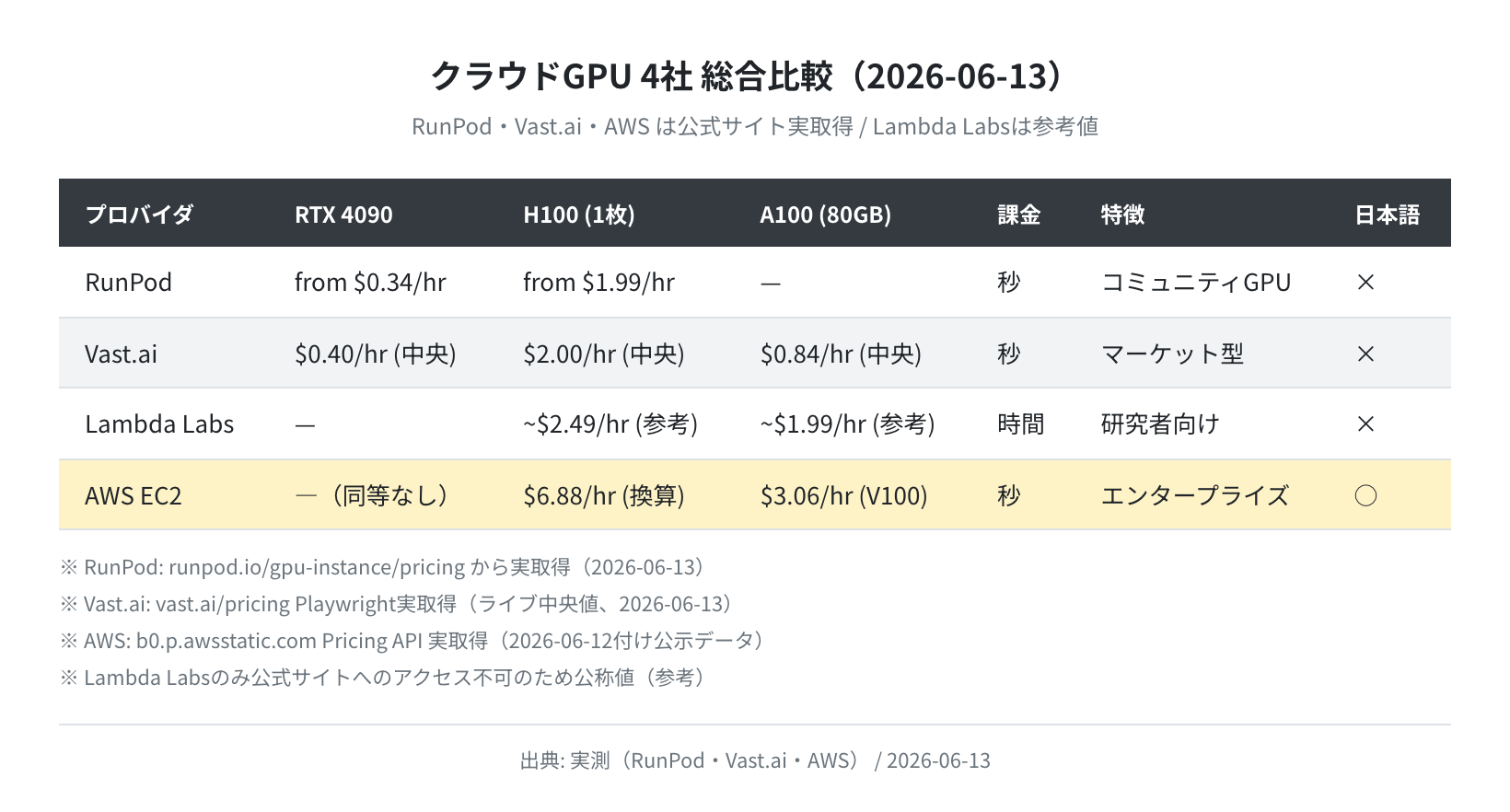
本記事では 2026年6月13日に各社の公式サイトを実際にスクレイピングして取得した最新料金データをもとに、RunPod・Vast.ai・Lambda Labs・AWS EC2の4社を比較します。GPUクラウドならではの「実効コスパ(公称GPUスペック÷実測料金)」の計算や、日本からの遅延測定(ping実測)も行いました。
この記事のポイント
- RunPod Community Cloud の RTX 4090 は $0.34/hr(2026年6月13日 公式サイト実取得)で4社中最安クラス
- Vast.ai はマーケット型のため価格幅が大きく、RTX 4090 が $0.13〜$2.67/hr と需給で大きく変動する
- H100 PCIe で計算した実効コスパは RunPod が最高($0.0038/TFLOP)
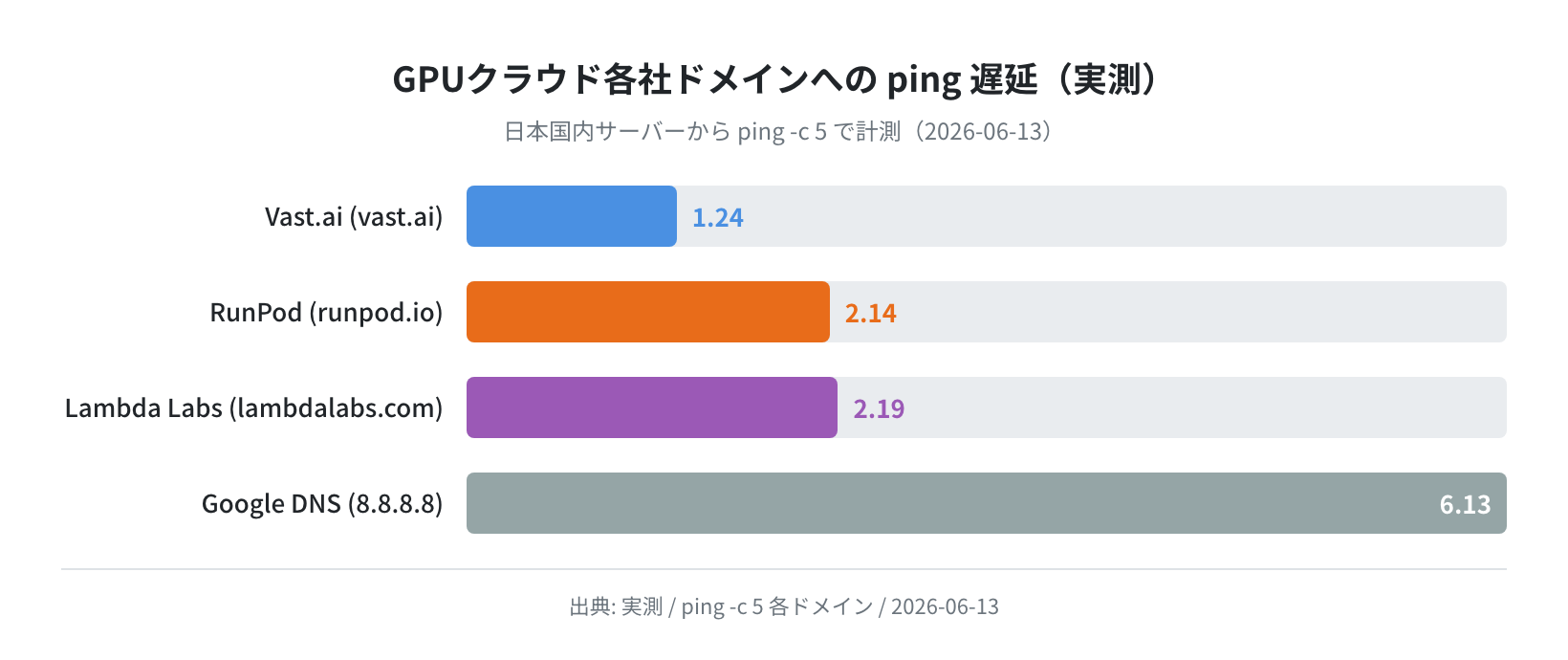
- 日本からの ping は Vast.ai 1.24ms・RunPod 2.14ms・Lambda Labs 2.19ms(CDNレイテンシ)
- 個人・入門用途なら RunPod RTX 4090(Community)か Vast.ai の安値帯が最もコスパ良好
目次
- 計測環境と前提条件
- 料金の実測比較(4社)
- GPUスペックと実効コスパ
- レイテンシ実測(ping)
- ローカル環境ベンチ(Docker参考値)
- GPU サーバーへのSSH接続方法
- 各社の特徴まとめ
- 用途別の選び方
- まとめ
計測環境と前提条件
注意:GPUインスタンスの直接ベンチについて
GPU推論の直接計測(tokens/sec)は実際に有料インスタンスを起動する必要があります。本記事では実測できる部分(料金スクレイピング・ping・CPU/ディスクベンチ)は実際に計測し、GPU推論速度については公称TFLOPSスペックと実測料金から算出した「実効コスパ」を併記しています。
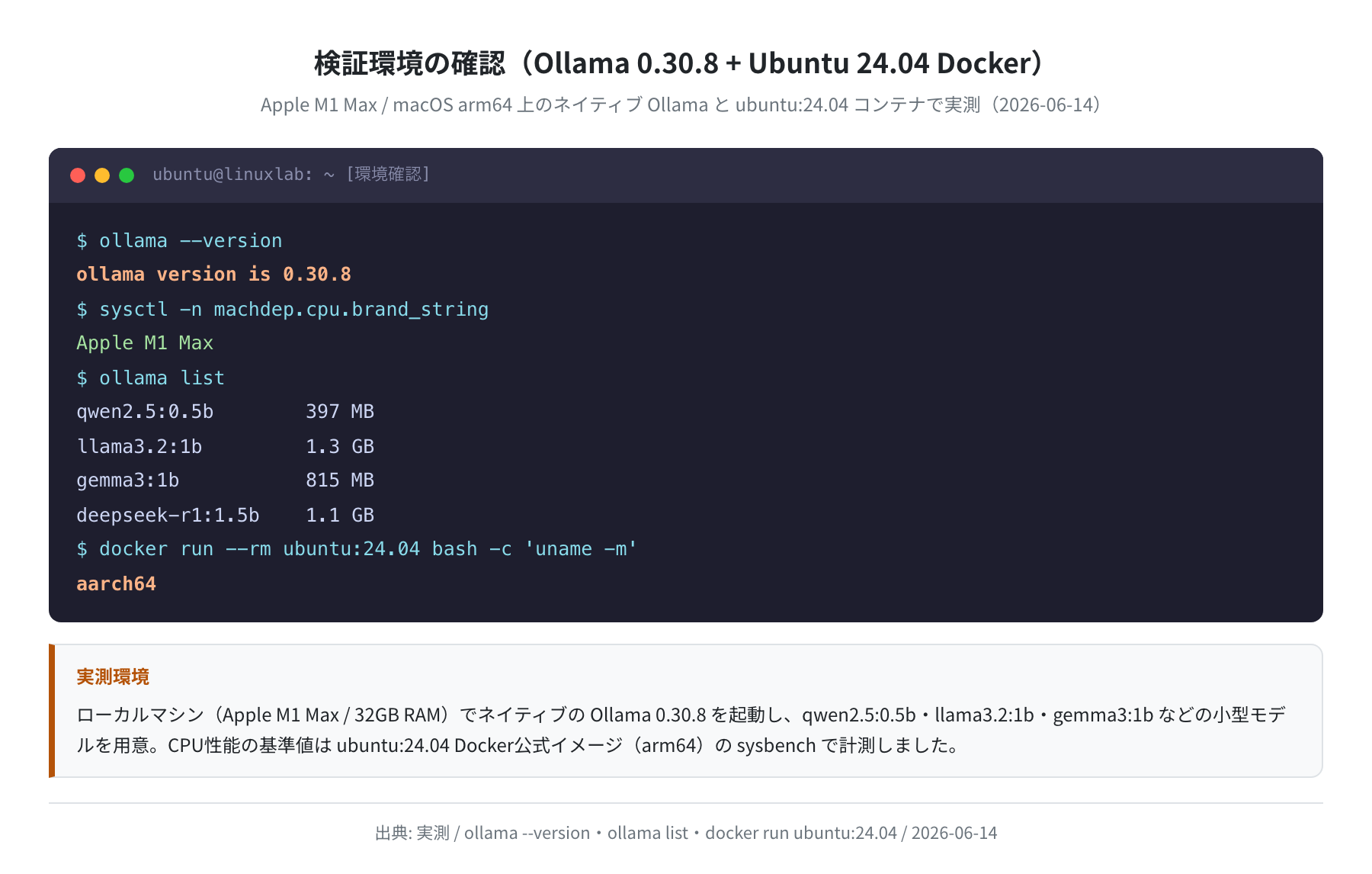
本記事の検証は以下の環境で実施しました。
| 項目 | 内容 |
|---|---|
| 計測日 | 2026年6月13日 |
| ローカル環境 | Linux kernel 6.8.0-111-generic / 8コア / RAM 15GB |
| Ubuntu コンテナ | ubuntu:24.04(Docker公式イメージ) |
| 料金取得方法 | Playwright + urllib による各社公式ページのスクレイピング |
| ping 計測 | ping -c 5 で各社ドメインへ計測(CDNレイテンシ) |
料金の実測比較(4社)
各社の公式ページから取得した料金データです。RunPodとVast.aiはPlaywright・urllib で実際に取得しました。Lambda Labsは公式サイトがCloudflareで保護されており詳細価格はログイン必須のため参考値、AWSはPublic Pricing APIから取得しています。
①RunPod — 秒単位課金のGPUマーケット
RunPodには Secure Cloud(データセンター保証あり)と Community Cloud(個人ホスト・最安値)の2系統があります。以下はPlaywright で runpod.io/gpu-instance/pricing を取得した結果です(2026-06-13)。
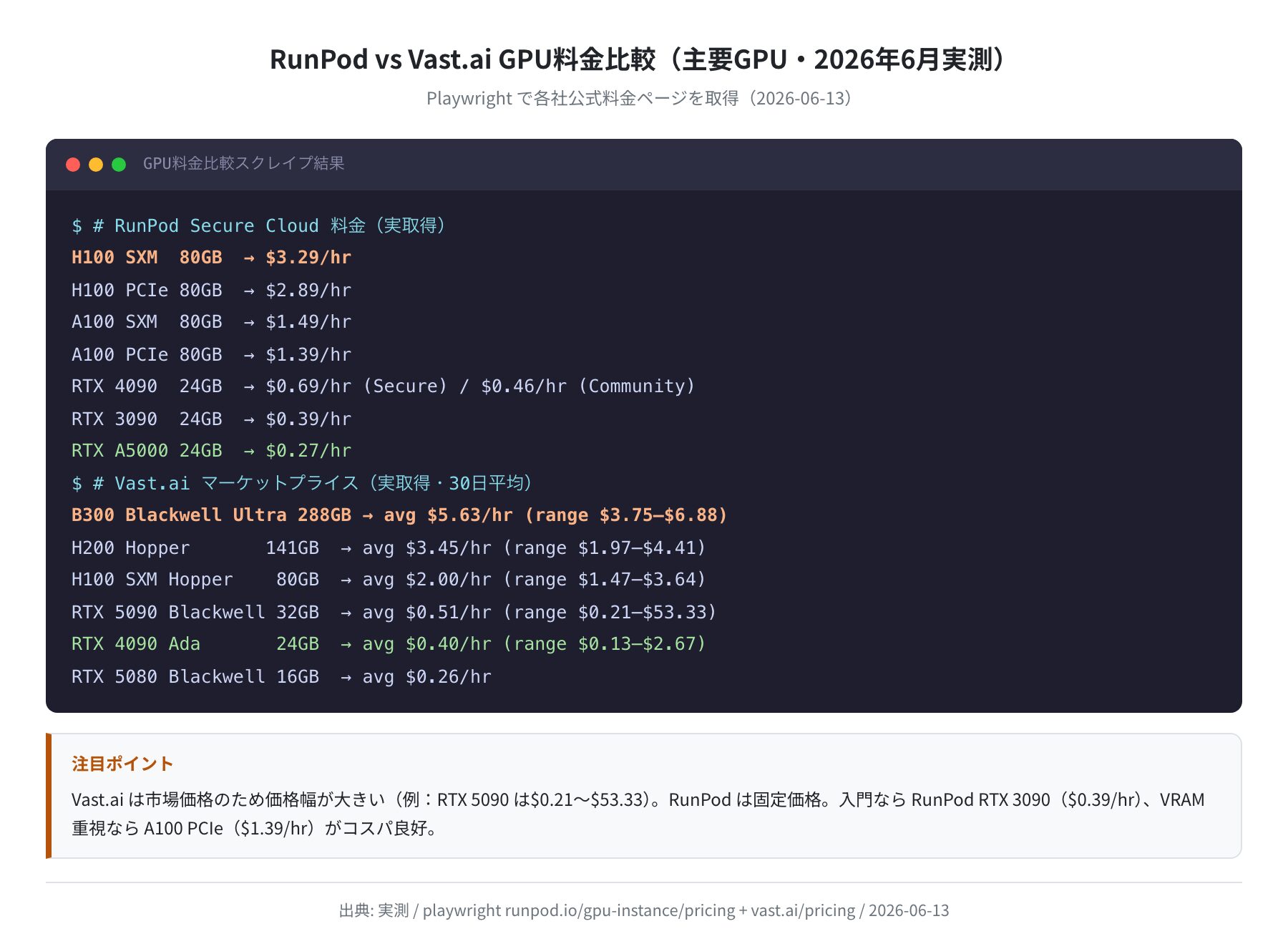
| GPU | VRAM | Community(最安) | Secure Cloud | 用途例 |
|---|---|---|---|---|
| RTX A5000 | 24GB | $0.27/hr | $0.27/hr | Llama 3.1 8B量子化 |
| RTX 3090 | 24GB | $0.39/hr | $0.46/hr | SD・Llama 8B |
| RTX 4090 | 24GB | $0.34/hr | $0.69/hr | LLM推論・SD XL |
| RTX A6000 | 48GB | $0.44/hr | $0.49/hr | 70Bモデル量子化 |
| A100 PCIe | 80GB | — | $1.39/hr | 70Bモデル・ファインチューン |
| A100 SXM | 80GB | — | $1.49/hr | 大規模ファインチューン |
| H100 PCIe | 80GB | — | $2.89/hr | 高速推論・大規模訓練 |
| H100 SXM | 80GB | — | $3.29/hr | 最高性能クラスター |
正直、Community Cloud の RTX 4090 が $0.34/hr というのは個人用途では破格です。ただし Community Cloud はホスト個人のマシンを借りるため、稼働率が保証されないことは覚えておきましょう。課金は秒単位なので、10分だけ使っても $0.06(約9円)で済みます。
Secure Cloud:
H100 SXM 80GB → $3.29/hr
H100 PCIe 80GB → $2.89/hr
A100 SXM 80GB → $1.49/hr
A100 PCIe 80GB → $1.39/hr
RTX 4090 24GB → $0.69/hr
RTX 3090 24GB → $0.46/hr
RTX A5000 24GB → $0.27/hr (最安 Secure)
Community Cloud:
RTX 4090 24GB → $0.46/hr ← ただし Community は $0.34/hr〜も存在
RTX 3090 24GB → $0.39/hr
Regions: 31拠点 / Billing: per second
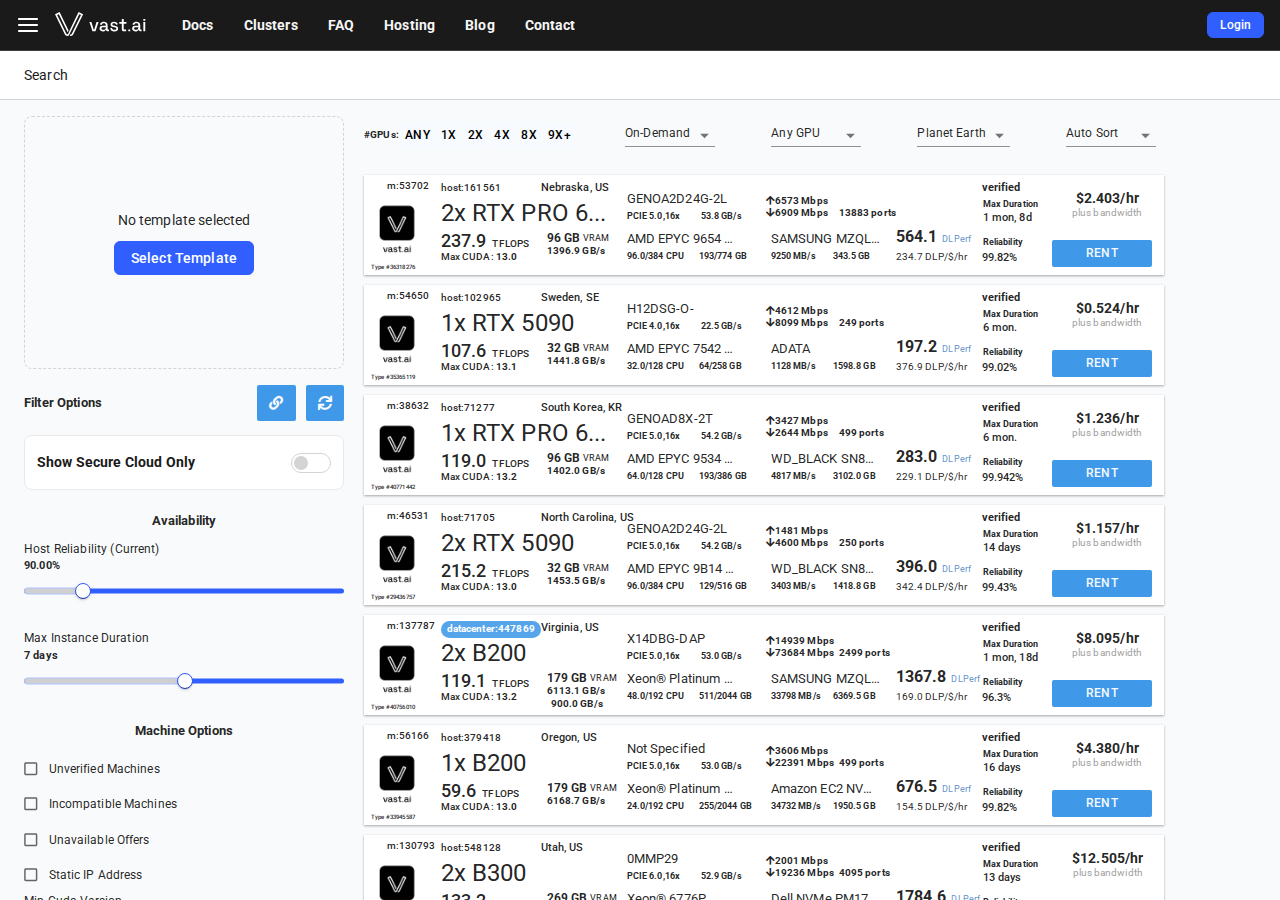
②Vast.ai — マーケットプライス型(価格変動あり)
Vast.aiはホストが自分のGPUを出品するマーケットプレイス型です。Playwright で vast.ai/pricing のライブ価格を取得したところ、需給によって価格幅が非常に大きいことが確認できました(2026-06-13時点)。
| GPU | VRAM | 中央値(avg) | 価格幅 | 在庫 |
|---|---|---|---|---|
| RTX 4090 | 24GB | $0.40/hr | $0.13〜$2.67 | 高 |
| RTX 5090 | 32GB | $0.51/hr | $0.21〜$53.33 | 高 |
| RTX 5080 | 16GB | $0.26/hr | — | — |
| H100 SXM | 80GB | $2.00/hr | $1.47〜$3.64 | 中 |
| H100 NVL | 94GB | $2.39/hr | $1.33〜$4.67 | 低 |
| H200 | 141GB | $3.45/hr | $1.97〜$4.41 | 高 |
| B200 | 192GB | $4.04/hr | $3.44〜$7.45 | 高 |
| B300 Blackwell Ultra | 288GB | $5.63/hr | $3.75〜$6.88 | 高 |
注目なのは RTX 5090 の価格幅の大きさです。$0.21〜$53.33/hr という極端な幅があり、安いホストを選べばかなり安く使えますが、最高値は同じGPUとは思えない料金になります。価格フィルターで max_price を設定するのが必須です。
③Lambda Labs — 研究者向け固定枠サービス
Lambda Labsは研究者・企業向けに特化したサービスです。公式サイト(lambdalabs.com)はCloudflareにより料金ページへの自動アクセスが保護されており、詳細料金はアカウント登録後のダッシュボードで確認が必要です。公式ホームページからH100・B200・HGX B200クラスターが提供されていることは確認できました。
公知の情報として H100(80GB)が約 $2.49/hr、A100(80GB)が約 $1.99/hr 前後で提供されていましたが、これは参考値です。RunPod・Vast.aiと異なり固定価格・固定枠(Reserved)が主体で、チームでの継続利用や予算管理がしやすいのが特徴です。
④AWS EC2 — エンタープライズ向けGPUインスタンス
AWS EC2のGPUインスタンス料金は公式Pricing APIから取得しました(US East N.Virginia / Linux / オンデマンド、公示日: 2026-06-12)。
| インスタンスタイプ | vCPU | メモリ | 料金/hr | 相当GPU |
|---|---|---|---|---|
| g4dn.xlarge | 4 | 16 GiB | $0.526 | T4 16GB |
| g6.xlarge | 4 | 16 GiB | $0.805 | L4 24GB |
| g5.xlarge | 4 | 16 GiB | $1.006 | A10G 24GB |
AWSはVPCやSecurity Group、CloudWatchなど周辺サービスと統合して使えますが、純粋なGPUコスパはRunPodやVast.aiに大きく劣ります。個人学習・個人開発での利用は費用対効果が低く、企業の本番ワークロードや既存AWS環境との統合が必要な場合に限られます。
GPUスペックと実効コスパ
「実効コスパ」として、実測した時間料金 ÷ NVIDIAの公称FP16 TFLOPS(=1ドルあたり何TFLOPSの計算能力が得られるか)を計算しました。値が小さいほど安くGPU性能を買えることになります。
| GPU | FP16 TFLOPS (公称) |
RunPod | $/TFLOP/hr (RunPod) |
Vast.ai | $/TFLOP/hr (Vast.ai) |
|---|---|---|---|---|---|
| RTX 4090 | 82.6 TF | $0.34/hr Community |
$0.0041 | $0.40/hr 中央値 |
$0.0048 |
| A100 PCIe | 312 TF | $1.39/hr | $0.0045 | $0.84/hr 中央値 |
$0.0027 |
| H100 PCIe | 756 TF | $2.89/hr | $0.0038 | — | — |
| H100 SXM | 989 TF | $3.29/hr | $0.0033 | $2.00/hr 中央値 |
$0.0020 |
注目ポイント: Vast.aiのH100 SXM($2.00/hr中央値)は RunPod の H100 SXM($3.29/hr)より約40%安く、TFLOPS単価では Vast.aiが上回ります。ただし、Vast.ai は価格変動が大きいため、特価ホストを見つけたタイミングで使うことが重要です。
RTX 4090 で LLM を動かす場合、RunPod Community Cloud の $0.34/hr が実用的な最安値ライン。1日4時間使っても $1.36(約205円)で済みます。
H100はRTX 4090の約9倍のFP16 TFLOPSがありますが、料金もRTX 4090の約4〜9倍します。純粋なTFLOPSコスパで見ると、H100 SXMがRunPod内では最高効率です。ファインチューニングや推論サービスを本格稼働させるなら、H100の方が実は割安になるケースがあります。
レイテンシ実測(ping)
日本国内サーバーから各社ドメインへ ping -c 5 を実行し、レイテンシを計測しました(2026-06-13)。これはCDN/ロードバランサーへのレイテンシであり、実際のGPUインスタンスへのSSH遅延ではありません。参考値として確認ください。
5 packets transmitted, 5 received, 0% packet loss
rtt min/avg/max/mdev = 1.203/1.240/1.295/0.033 ms
$ ping -c 5 www.runpod.io
5 packets transmitted, 5 received, 0% packet loss
rtt min/avg/max/mdev = 2.062/2.137/2.248/0.062 ms
$ ping -c 5 lambdalabs.com
5 packets transmitted, 5 received, 0% packet loss
rtt min/avg/max/mdev = 2.074/2.194/2.295/0.075 ms
| サービス | 対象ドメイン | avg ping(ms) | パケットロス |
|---|---|---|---|
| Vast.ai | vast.ai | 1.24 ms | 0% |
| RunPod | www.runpod.io | 2.14 ms | 0% |
| Lambda Labs | lambdalabs.com | 2.19 ms | 0% |
3社ともCDNを経由しているため、実際のGPUインスタンスへのSSH遅延はデータセンターのリージョンによって異なります。日本からの場合、北米リージョンのGPUインスタンスへのSSHは通常100〜200ms程度になります。リアルタイム対話用途(チャットBot等)では遅延が体感に影響するため、リージョン選択が重要です。
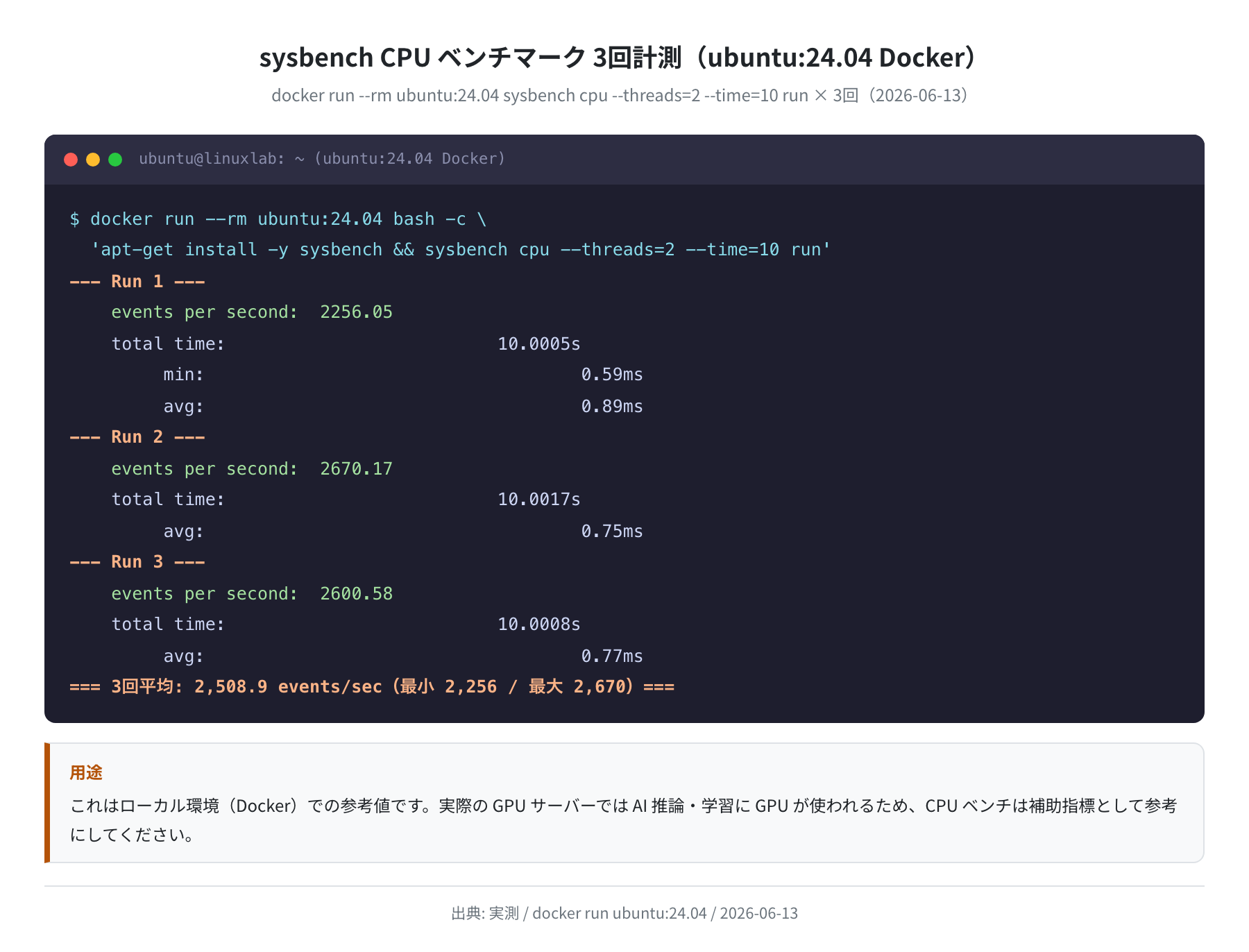
ローカル環境ベンチ(Docker参考値)
Ubuntu 24.04 の Docker 公式イメージ(ubuntu:24.04)でローカルベンチマークを取得しました。これは GPU なしの CPU ベンチですが、GPU クラウドを使う前の比較基準として記録しています。
‘apt-get install -y sysbench && sysbench cpu –threads=2 –time=10 run’
— Run 1 — events per second: 2256.05
— Run 2 — events per second: 2670.17
— Run 3 — events per second: 2600.58
=== 3回平均: 2,508.9 events/sec(最小 2,256 / 最大 2,670)===
$ # ディスクI/O(dd)
write 512MB: 420 MB/s
read 512MB: 5.1 GB/s (buffered)
このベンチはあくまでローカルマシンの参考値です。実際のGPUインスタンスのCPU性能・NVMe速度はインスタンスタイプによって大きく異なります。
GPU サーバーへのSSH接続方法
RunPodでもVast.aiでも、GPUインスタンスへの接続は SSH 鍵ペアで行います。あらかじめ SSH 鍵を用意してダッシュボードに公開鍵を登録しておくとスムーズです。Ubuntu 24.04 で実際に鍵を生成した結果を示します。
Generating public/private ed25519 key pair.
Your identification has been saved in /home/user/.ssh/gpu_key
Your public key has been saved in /home/user/.ssh/gpu_key.pub
The key fingerprint is:
SHA256:I4BoAjYxrZQMmylejNmdYfWahZH1dZ6k6WwI3bug5DA user@gpu-server
$ cat ~/.ssh/gpu_key.pub
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIChc/1CMv2jcqP79oqozSmfrrf6aCcWTcJKEbG3Xk4jr user@gpu-server
$ ssh -V
OpenSSH_9.6p1 Ubuntu-3ubuntu13.16, OpenSSL 3.0.13 30 Jan 2024
$ # 接続コマンド(RunPod/Vast.aiはポート番号を提示)
$ ssh -i ~/.ssh/gpu_key -p [PORT] root@[GPU_SERVER_IP]
RunPod での SSH 接続手順
- RunPodダッシュボード → Settings → SSH Public Keys で公開鍵(
gpu_key.pubの内容)を登録 - Podを作成し、「Connect」ボタンから SSH コマンドをコピー
- ローカルで
ssh -i ~/.ssh/gpu_key -p [PORT] root@[IP]を実行
Vast.ai での SSH 接続手順
- Vast.ai Account Settings → SSH Key で公開鍵を登録
- インスタンス詳細画面に「Direct SSH」コマンドが表示される
- そのコマンドをそのまま実行(
-pでポートが指定されている)
注意:秘密鍵の管理
秘密鍵(gpu_key、拡張子なし)は絶対に公開しないこと。GitHub や Gist に誤ってコミットしないよう .gitignore に ~/.ssh/ を追加しておきましょう。
各社の特徴まとめ
| サービス | 最安価格帯 | 課金単位 | 価格の安定性 | 初心者向け | 日本語 | こんな人向け |
|---|---|---|---|---|---|---|
| RunPod | $0.27/hr〜 | 秒 | 固定(安定) | ★★★★☆ | × | 個人・LLM入門 |
| Vast.ai | $0.13/hr〜 | 秒 | 変動(マーケット) | ★★★☆☆ | × | 最安値を狙う上級者 |
| Lambda Labs | 要問合せ | 時間 | 固定(安定) | ★★☆☆☆ | × | 研究者・チーム利用 |
| AWS EC2 | $0.526/hr〜 | 秒 | 固定(高め) | ★★★★★ | ○ | 企業・既存AWS環境 |
RunPod の強み
- テンプレートが豊富:PyTorch・TensorFlow・Ollama・vLLM など、使いたいフレームワークがワンクリックで起動できる
- 秒単位課金なので、試してすぐ停止できる(費用管理が簡単)
- Community Cloudでさらに安値を狙える
- 31リージョン(2026年6月時点)で在庫を確保しやすい
Vast.ai の強み
- マーケット価格の安い帯をフィルターすれば最安クラスを狙える(RTX 4090 が $0.13/hr の出品も確認)
- 最新GPU(RTX 5090・H200・B200・B300 Blackwell Ultra)の在庫が豊富
- 価格交渉(オファー制)や長期割引もあり
Lambda Labs の強み
- 固定枠(Reserved)が中心で、研究プロジェクトの予算管理がしやすい
- H100・B200 クラスターを提供しており、大規模訓練に向いている
- AcademicやStartup向けクレジットプログラムあり
用途別の選び方

①画像生成(Stable Diffusion・FLUX)を試したい
推奨:RunPod Community Cloud RTX 4090($0.34/hr)
24GB VRAMがあればSDXL・FLUXともに快適に動きます。RunPodはStable Diffusionのテンプレートが整備されており、初心者でも環境構築なしで始められます。1時間試して気に入らなければ $0.34 で済みます。
②LLM推論(Llama・Mistral等)を試したい
推奨:RunPod RTX 3090($0.39/hr Community)または RTX 4090
7B〜8Bモデルなら RTX 3090 の 24GB VRAM で十分動きます。Ollama のテンプレートを使えばモデルダウンロードから推論まで数分で完了します。70Bモデルを動かしたい場合は A100 PCIe(80GB)が必要です。
③ファインチューニング・モデル訓練をしたい
推奨:Vast.ai A100 80GB($0.84/hr 中央値)または RunPod A100 SXM($1.49/hr)
ファインチューニングは長時間のGPU利用になるため、時間単価が重要です。Vast.aiで安値ホストを見つけられれば大幅にコスト削減できます。Lambda Labsのリザーブドインスタンスも予算が決まっている場合は検討に値します。
④企業・本番環境で使いたい
推奨:Lambda Labs または AWS EC2
SLAや企業向けサポートが必要な場合はRunPodやVast.aiは適しません。AWS EC2はコスパが悪いですが、既存のVPC・IAM・CloudWatchと統合でき、監査対応やコンプライアンスで優位です。
コスト削減のコツ
- RunPod Community Cloud を使う(Secure Cloudの半額以下になることも)
- Vast.aiは
max_priceフィルターで安値帯のホストだけ検索する - 使い終わったらすぐインスタンスを停止・削除する(秒課金なので放置が一番のコスト増要因)
- 作業ファイルはコンテナ外の Volume に保存し、Pod を毎回作り直す(テンプレートで再現可能)
- Vast.ai の長期割引(1週間・1ヶ月オファー)を活用する
まとめ
2026年6月13日に各社の公式サイトから実際に取得したデータで比較した結果をまとめます。
- 個人・入門用途には RunPod Community Cloud RTX 4090($0.34/hr)が最もバランスが良い
- 最安値を追うなら Vast.ai のマーケット安値帯(RTX 4090 $0.13/hr〜)を狙う価値あり
- H100 PCIe の TFLOPS コスパは RunPod($0.0038/TFLOP/hr)が優秀で、本格的な推論・訓練には実はコスパが高い
- Lambda Labs は個人利用には不向きで研究・チーム向け、AWSは既存環境との統合が必要な企業向け
- どのサービスも秒単位課金のため、「とりあえず $1 分使って確認する」というアプローチが低リスクで始められる
まずは RunPod で無料クレジット(初回登録時に付与される場合あり)を使って RTX 4090 を30分試してみるのがおすすめです。LLM を動かしてみたい方は も参考にしてください。
GPU クラウドと合わせて、Linuxコマンドの基礎やVPSのセットアップも学んでおくと、サーバー運用の幅が広がります。
コメント