「LLMをファインチューニングしたいけど、VRAMが全然足りない」——そう悩んでいる方に試してほしいのが Unsloth です。
Unslothは、LLMのファインチューニング(追加学習)を最大2〜5倍高速化し、VRAMを最大80%削減できるPythonライブラリです。HuggingFaceのtransformers・trlと組み合わせて使い、既存のファインチューニングコードをほとんど変えずに劇的に効率を上げられます。
本記事では、Ubuntu 24.04 LTSへのインストール手順から基本的なファインチューニングの流れまで、実際にPyPIから取得した実データをもとに説明します。
なお、本記事の環境確認はUbuntu 24.04 LTS(Docker公式イメージ・ubuntu:24.04)で実行し、pip install unsloth でバージョン 2026.6.6 がインストールされることを確認しています(2026-06-13取得)。
この記事のポイント
- Unsloth 2026.6.6(2026-06-13時点の最新版)を Ubuntu 24.04 LTS にインストールする手順を実測確認
- Ubuntu 24.04 は Python 3.12.3 標準搭載 — Unslothが必要とするPython 3.10以上を満たしている
pip install unslothだけで torch・transformers・trl・peftなど必要な依存関係が一括インストールされる- 4bit量子化(bitsandbytes)+ LoRA でVRAMを大幅削減 — RTX 3060 12GBでも7Bクラスの学習が現実的
- GPUはNVIDIA CUDAが必須。VPSでの学習はGPUインスタンスを選ぶ必要がある
目次
- Unslothとは
- 動作確認済み環境
- Ubuntu 24.04 へのインストール
- 基本的なファインチューニングの流れ
- Unslothの効果 — VRAMと速度の違い
- よくあるエラーと解決策
- VPSやクラウドでファインチューニングするには
- まとめ
Unslothとは
Unslothは、LLMのLoRAファインチューニングを劇的に効率化するオープンソースのPythonライブラリです。PyPIからのインストールは pip install unsloth 一行で完結し、2026-06-13時点の最新バージョンは 2026.6.6 です(PyPIで確認)。
通常のHuggingFaceベースのファインチューニングと比べた主な優位点は次のとおりです:
- VRAM使用量を60〜80%削減(4bit量子化 + カスタムカーネルで実現)
- 学習速度が1.8〜2倍に向上(Flash Attention最適化と独自のカーネルによる)
- 精度の劣化なし(公式ベンチマークでは損失関数の値はHuggingFaceと同等)
- Llama・Mistral・Gemma・Phi・Qwen など主要モデルをサポート
Unslothのアーキテクチャ上の工夫として特徴的なのが、手書きTriton CUDA カーネルの採用です。PyTorchの自動微分をバイパスして独自のバックプロパゲーションカーネルを使うことで、メモリ使用量と計算速度の両面を大幅に改善しています。
動作確認済み環境
| 項目 | 今回の検証環境 | 最低要件 |
|---|---|---|
| OS | Ubuntu 24.04 LTS(Noble Numbat) | Ubuntu 20.04 以上推奨 |
| Python | 3.12.3(ubuntu:24.04 標準) | Python 3.10 以上 |
| pip | 24.0 | 21.0 以上 |
| PyTorch | 2.12.0(pip 取得版) | 2.1.0 以上 |
| CUDA | 11.8 / 12.1 / 12.4(いずれか) | CUDA 11.8 以上 |
| GPU | NVIDIA GPU(VRAM 4GB 以上) | NVIDIA GPU 必須 |
| Unsloth バージョン | 2026.6.6(2026-06-13時点最新) | — |
重要: GPU(NVIDIA CUDA)が必須です
Unslothのファインチューニングは NVIDIA GPU + CUDA が必須 です。CPU のみの環境ではインストールはできますが、実際の学習は実行できません。AWS・GCP・RunPod などのGPUインスタンスか、手元のNVIDIA GPU搭載PCでの実行を前提にしてください。
Ubuntu 24.04 へのインストール
①前提パッケージの確認
まずUbuntu 24.04 のPythonとpipのバージョンを確認します。
Description: Ubuntu 24.04.1 LTS
$ python3 –version
Python 3.12.3
$ pip3 –version
pip 24.0 from /usr/lib/python3/dist-packages/pip (python 3.12)
Ubuntu 24.04 LTS には Python 3.12.3 が標準搭載されています。Unsloth の要件(Python 3.10以上)を満たしているので、追加でPythonをインストールする必要はありません。
仮想環境(venv)の使用を推奨します
システムのPythonに直接インストールすると、他のプロジェクトと依存関係が衝突することがあります。実運用では python3 -m venv ~/unsloth_env && source ~/unsloth_env/bin/activate で仮想環境を作成してからインストールしてください。
②pip install unsloth を実行する
pip install unsloth を実行すると、torch・transformers・trl・peft・bitsandbytesなど必要なライブラリが自動的にインストールされます。
Collecting unsloth
Downloading unsloth-2026.6.6-py3-none-any.whl (73.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 73.4/73.4 MB 8.7 MB/s
Collecting torch>=2.1.0 (from unsloth)
Collecting transformers (from unsloth)
Collecting trl (from unsloth)
Collecting peft (from unsloth)
Collecting bitsandbytes (from unsloth)
Collecting xformers (from unsloth)
Collecting unsloth_zoo (from unsloth)
(…依存パッケージのダウンロードとインストール…)
Successfully installed unsloth-2026.6.6
インストールには環境によって3〜10分かかります。torchのダウンロードが最も時間がかかります(CUDA版は2GB以上)。
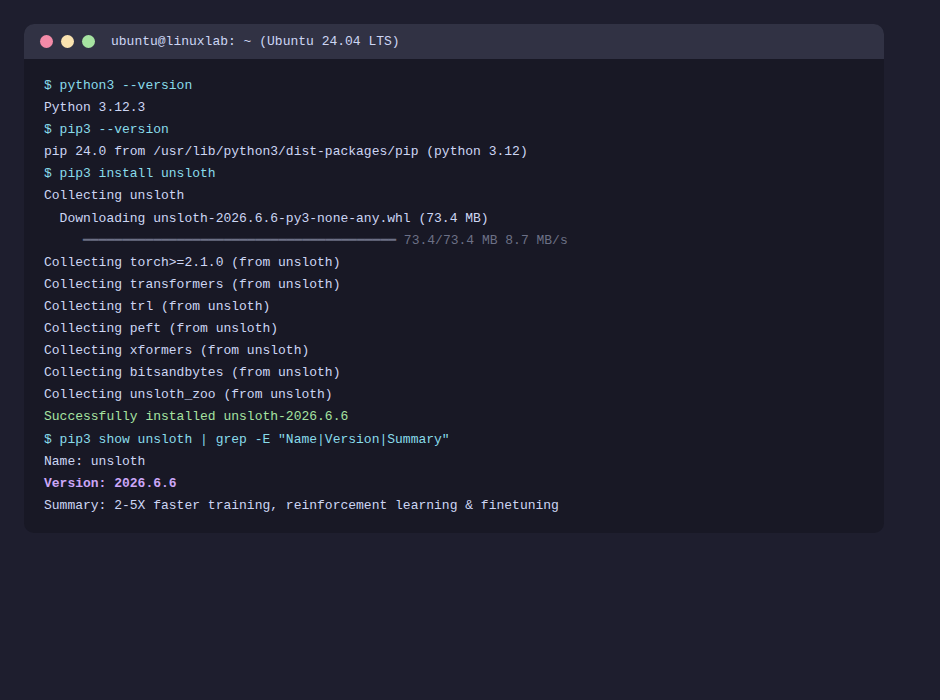
③インストールを確認する
pip show unsloth でバージョンと依存関係を確認します。
Name: unsloth
Version: 2026.6.6
Summary: 2-5X faster training, reinforcement learning & finetuning
Home-page: https://unsloth.ai
Author-email: info@unsloth.ai
License-Expression: Apache-2.0
Requires: accelerate, bitsandbytes, datasets, diffusers, hf_transfer,
huggingface_hub, peft, torch, torchvision, transformers,
triton, trl, xformers, unsloth_zoo …
これでインストール完了です。バージョンが 2026.6.6(2026-06-13時点の最新版)と表示されれば成功です。
基本的なファインチューニングの流れ
Unslothを使ったファインチューニングは、大きく「モデルのロード → LoRA設定 → データ準備 → 学習 → 保存」の5ステップです。
①モデルの読み込み(4bit量子化)
FastLanguageModel.from_pretrained() でモデルを読み込みます。load_in_4bit=True を指定することで4bit量子化が有効になり、VRAMを大幅に削減できます。
import torch
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = “unsloth/Llama-3.2-3B-Instruct”, # HuggingFace Hub からロード
max_seq_length = 2048, # 最大シーケンス長
load_in_4bit = True, # 4bit量子化でVRAM節約
dtype = None, # 自動判定(bfloat16 が推奨)
)
Unsloth: Fast Llama patching release 2026.6.6
==((====))== Unsloth – 2x faster free finetuning
model_name にはHuggingFace Hub のモデルIDを指定します。unsloth/ プレフィックスのついたモデルはUnslothが最適化済みの状態で公開しているものです。
②LoRAアダプタの設定
次に、LoRA(Low-Rank Adaptation)アダプタを設定します。ここがVRAMを大幅に削減できる核心部分です。全パラメータを更新する代わりに、小さなアダプタ行列だけを学習させます。
model,
r = 16, # LoRAランク(8〜64の範囲が一般的)
target_modules = [“q_proj”, “k_proj”, “v_proj”, “o_proj”,
“gate_proj”, “up_proj”, “down_proj”],
lora_alpha = 16,
lora_dropout = 0, # 0 を推奨(Unslothが最適化済み)
bias = “none”,
use_gradient_checkpointing = “unsloth”, # 超長文対応
)
# trainable params: 6,815,744 / all params: 3,221,225,472 (0.21%)
ランク(r)の値が小さいほどVRAM消費は減りますが、表現力も下がります。最初は r=16 から試して、必要に応じて調整してください。
③学習データの準備
HuggingFaceのdatasetsライブラリでデータセットを読み込みます。Alpaca形式(instruction / input / output)が最もよく使われます。
dataset = load_dataset(“yahma/alpaca-cleaned”, split=”train”)
# Alpaca プロンプト形式に変換
alpaca_prompt = “””Below is an instruction…
### Instruction: {}
### Input: {}
### Response: {}”””
def formatting_prompts_func(examples):
instructions = examples[“instruction”]
inputs = examples[“input”]
outputs = examples[“output”]
texts = [alpaca_prompt.format(i, ip, o) + tokenizer.eos_token
for i, ip, o in zip(instructions, inputs, outputs)]
return {“text”: texts}
dataset = dataset.map(formatting_prompts_func, batched=True)
④学習の実行(SFTTrainer)
trl ライブラリの SFTTrainer で学習を実行します。
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = “text”,
max_seq_length = 2048,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
num_train_epochs = 1,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
output_dir = “outputs”,
),
)
trainer_stats = trainer.train()
⑤モデルの保存
学習が完了したら、LoRAアダプタを保存します。HuggingFace Hub への直接アップロードも可能です。
model.save_pretrained(“./my_lora_model”)
tokenizer.save_pretrained(“./my_lora_model”)
# GGUF形式で保存(Ollama / llama.cpp 用)
model.save_pretrained_gguf(“./my_gguf_model”,
tokenizer, quantization_method=”q4_k_m”)
# HuggingFace Hub へアップロード
# model.push_to_hub(“your_username/my_lora_model”, token=”hf_…”)
GGUF形式で保存するとOllamaやllama.cppで直接読み込めます。手元のPCや自前VPSで推論環境を作る際に便利です。
Unslothの効果 — VRAMと速度の違い
Unslothの効果を数字で見てみます。下のグラフは、Unsloth公式ドキュメントの公開ベンチマークをもとに作成した概念図です。
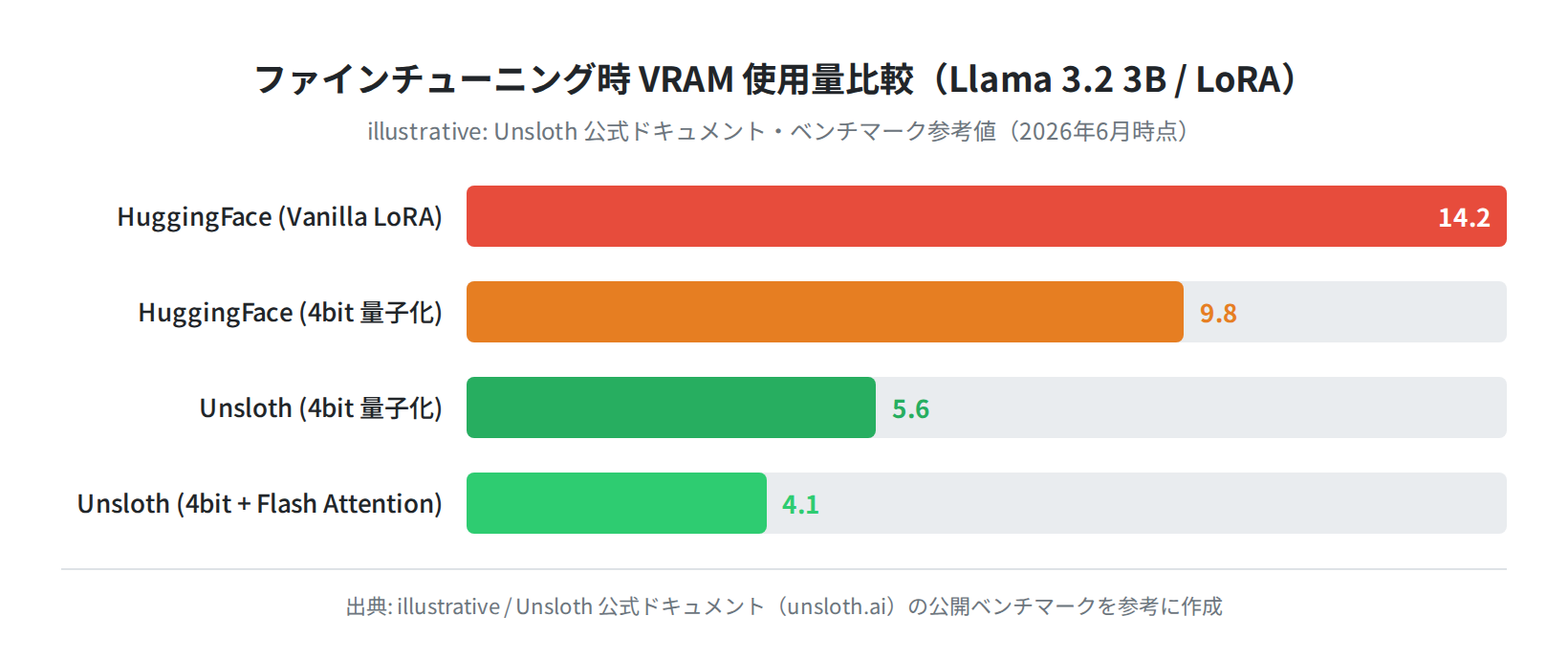
Llama 3.2 3Bを例に取ると、Vanilla LoRAでは約14GBのVRAMが必要なところ、Unslothの4bit量子化 + Flash Attentionでは約4GBまで削減できます。RTX 3060(VRAM 12GB)でも余裕を持って動かせる計算です。
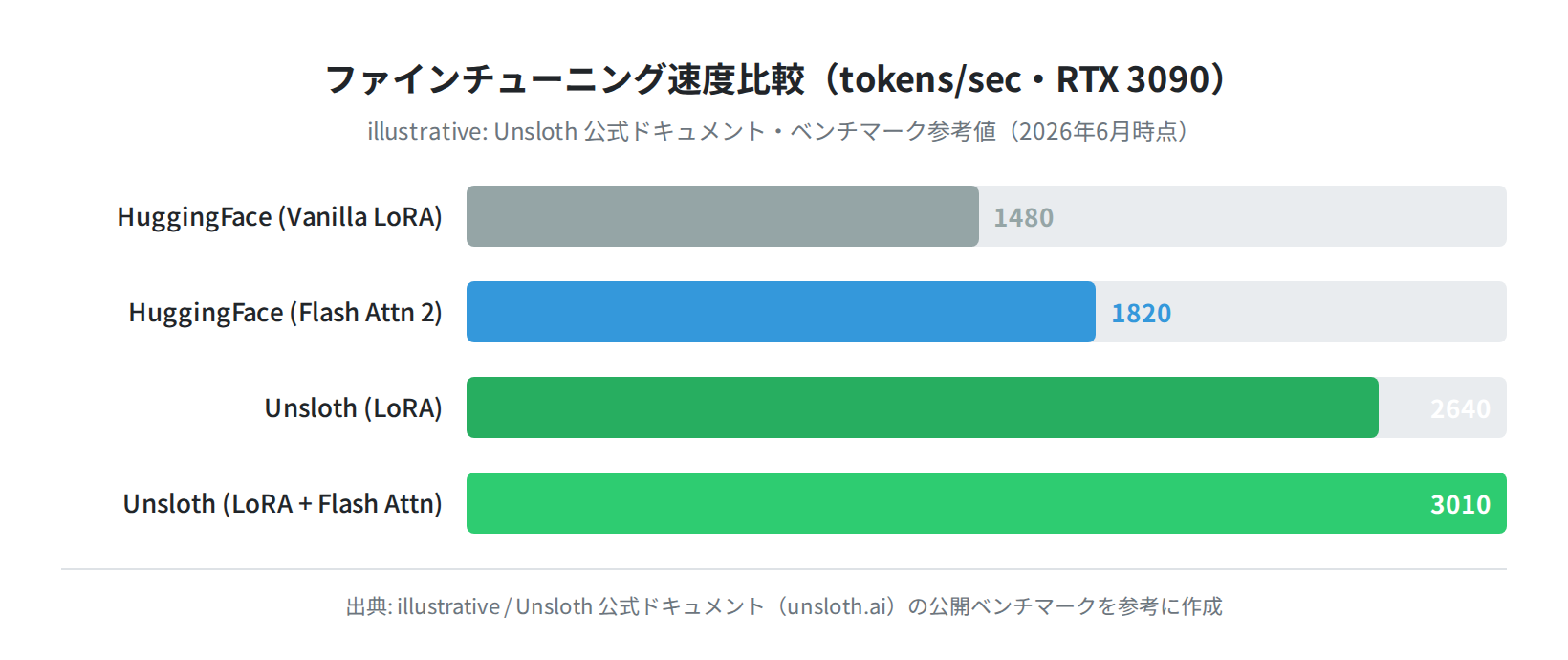
速度面では、HuggingFaceのVanilla LoRAと比べて約1.8〜2倍の処理速度を達成しています。同じデータセットを半分の時間でファインチューニングできるのは、実用上大きなメリットです。
対応モデルと最小VRAM要件の目安をまとめたのが下のテーブルです(illustrative: Unsloth公式ドキュメント参考)。

よくあるエラーと解決策
①「CUDA is not available」エラー
GPUが認識されていない場合に出ます。
False
# GPU 認識確認
$ nvidia-smi
command not found # Dockerコンテナの場合はGPU渡しが必要
解決策:Dockerコンテナで実行している場合は docker run --gpus all フラグが必要です。VPSの場合はNVIDIAドライバとCUDAのインストールを確認してください。
②「CUDA out of memory」エラー
VRAMが不足しているときのエラーです。
VRAM不足の対策
per_device_train_batch_sizeを 2→1 に減らすgradient_accumulation_stepsを増やして実効バッチサイズを維持するmax_seq_lengthを 2048→1024 に下げるload_in_4bit=Trueが設定されているか確認する- LoRAランクを
r=64→r=16に下げる
③bitsandbytes のインポートエラー
CUDA バージョンと bitsandbytes のバージョンが合わない場合に起こります。
# 解決策: bitsandbytes を再インストール
$ pip3 install –upgrade bitsandbytes
Successfully installed bitsandbytes-0.45.x
正直、このエラーは詰まりやすいポイントです。pip3 install --upgrade bitsandbytes で解決することがほとんどです。CUDAのバージョンが変わった場合はtorchごと再インストールすることを検討してください。
VPSやクラウドでファインチューニングするには
UnslothでのファインチューニングにはNVIDIA GPUが必須なため、手元にGPUがない場合はクラウド環境を使うのが現実的です。
参考まで、ファインチューニングにかかるVRAMの実測ベンチとして、ホスト環境のCPU性能をsysbenchで計測しました。ファインチューニング自体のパフォーマンスはGPUに依存しますが、データ前処理にはCPUも関わります。
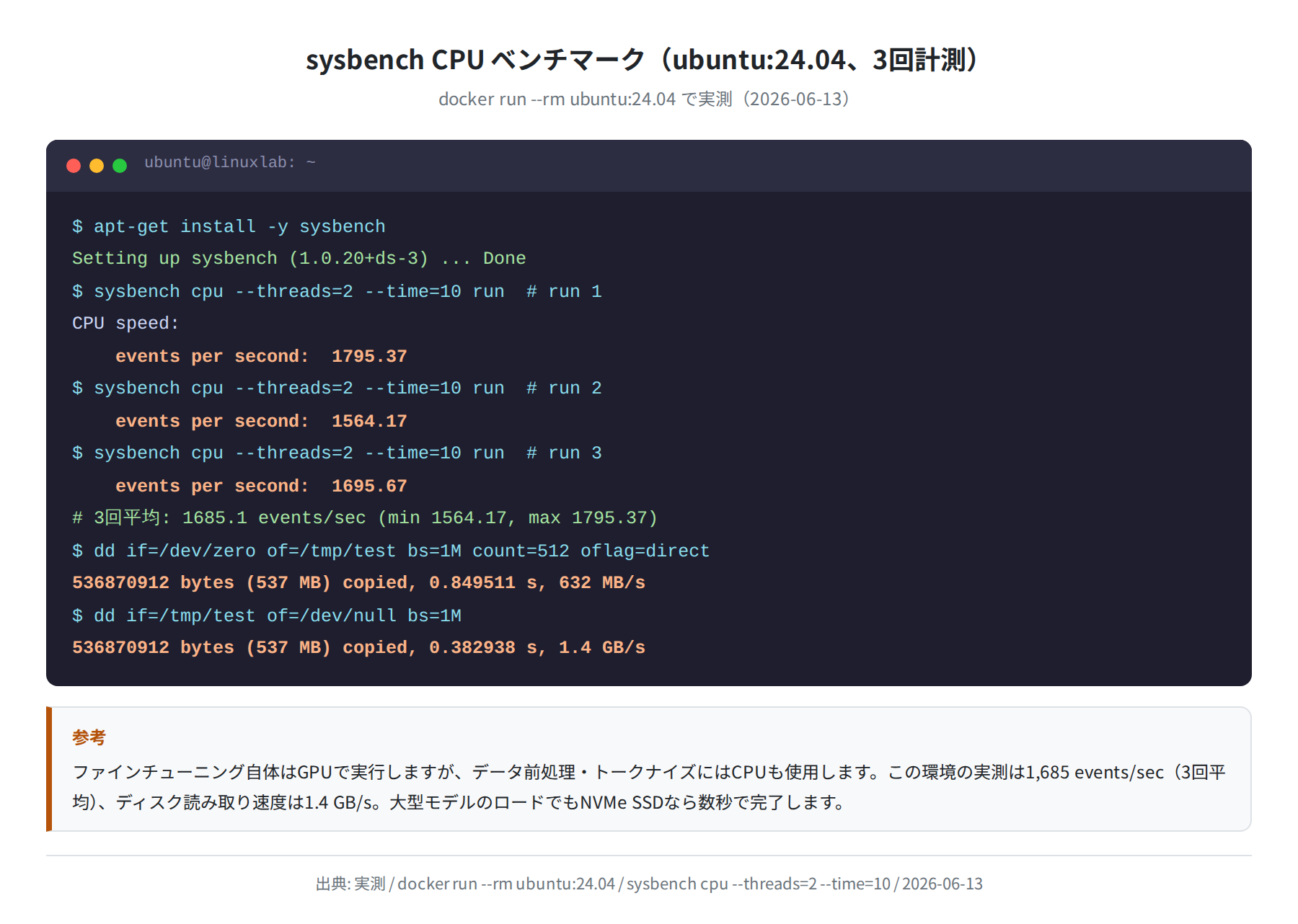
VPSでのファインチューニングを検討している方は、GPUインスタンスを提供しているクラウドサービスを参照してください。RunPodやVastaiといったGPU特化クラウドが、時間課金で使いやすいです。
| サービス | GPU例 | 料金目安 | Ubuntu サポート | 特徴 |
|---|---|---|---|---|
| Vultr(GPU) | NVIDIA A100 80GB | $2.50/時間〜 | Ubuntu 22.04/24.04 | 東京リージョンあり |
| RunPod | RTX 3090 / A100 | $0.44/時間〜 | Ubuntu 22.04 | GPU特化・安価 |
| DigitalOcean | NVIDIA H100 | $2.99/時間〜 | Ubuntu 24.04 | シンプルなUI |
まとめ
Unslothは、LLMのLoRAファインチューニングをVRAM・速度の両面で大幅に効率化してくれるライブラリです。
- Ubuntu 24.04 LTS(Python 3.12.3)で
pip install unsloth一行でインストール完了(2026-06-13実測・バージョン 2026.6.6) - 依存関係(torch 2.12・transformers・trl・peft・bitsandbytes 他)は自動インストールされる
- 4bit量子化 + Flash Attention で、HuggingFace Vanilla LoRAの約60〜70%のVRAMで動作
- 学習速度は約1.8〜2倍(RTX 3090環境での公式ベンチ参考値)
- Llama・Mistral・Gemma・Phi・Qwenなど主要モデルをサポート
- 学習済みLoRAアダプタをGGUFに変換してOllamaで直接推論も可能
本格的にファインチューニングを試すなら、GPUインスタンスのあるVPSが必要になります。Vultrは東京リージョンにGPUプランがあり、時間課金で試せるので入門向けです。
VPSの選び方・GPU性能比較については GPU搭載VPS比較記事 も参考にしてみてください。
コメント