この記事のポイント
- 同じマシン・同じモデルで
num_gpuだけを切り替え、CPU推論とGPU推論の速度を実測で比較しました - 結論、GPU(Metal)はCPUの約2.0〜2.8倍でした(Qwen2.5 0.5B で 167 vs 82、Llama 3.2 1B で 143 vs 52 tokens/sec)
- 意外なことに、CPUのみでも小型モデルなら
50〜80 tokens/sec出ており、チャットや要約には十分実用的です - 「GPUがないとローカルLLMは無理」は小型モデルに関しては誤解。まずCPUで試すのが無駄のない順序です
- 計測はすべて Ollama の API レスポンス(
eval_countとeval_duration)に基づく実測値です
「ローカルLLMを動かすにはやっぱりGPUがいるの?」「CPUだけだと実用にならないって本当?」——これからローカルLLMを触ろうとしている方が、最初に必ずぶつかる疑問だと思います。
結論から言うと、小型モデルならCPUだけでも普通に使えます。もちろんGPUのほうが速いのですが、その差は「数十倍」ではなく、今回の実測では約2〜3倍に収まりました。この記事では、想像や他サイトの数字ではなく、同じマシン・同じモデルでCPU推論とGPU推論を実際に切り替えて計測した一次データをもとに、両者の違いをはっきりさせます。
使ったのは Ollama(ローカルでLLMを動かすためのツール)です。Ollamaには「モデルの何レイヤをGPUに載せるか」を決める num_gpu というオプションがあり、これを 0 にすればCPUのみ、99 にすれば全レイヤをGPUに載せられます。同じモデルでこれを切り替えれば、ハードウェア以外の条件をそろえたまま、純粋にCPU vs GPUを比較できるというわけです。
この記事の検証環境について
推論速度の計測は Apple M1 Max(10コア / メモリ32GB / GPUはMetal) 上のネイティブ Ollama 0.30.8 で行いました。Apple Silicon は CPU と GPU がメモリを共有する「ユニファイドメモリ」のため、後述のとおりCPUとGPUの差が比較的小さく出ます。NVIDIA の独立GPU(discrete GPU)ではこの差はもっと大きくなる点に注意してください。環境情報・パッケージ確認・ベンチの一部は ubuntu:24.04 の公式Dockerイメージで取得しています。
目次
- 検証方法 — num_gpu を切り替えて同条件で比較する
- CPU推論 vs GPU推論 の実測結果
- なぜGPUは速いのか — レイヤのオフロードの仕組み
- CPUのコンピュート能力も実測する(sysbench)
- Open WebUI で実際に動かしてみる
- CPU推論で十分なケース / GPU推論が必要なケース
- よくあるエラーと解決策
- まとめ
検証方法 — num_gpu を切り替えて同条件で比較する
まず前提として、Ollama がどのバージョンで、どのモデルを使ったかを確認します。今回は0.5B〜1.5Bの小型モデルを3つ用意しました。
ollama version is 0.30.8
$ ollama list
NAME SIZE
qwen2.5:0.5b 397 MB
llama3.2:1b 1.3 GB
qwen2.5-coder:1.5b-base 986 MB
計測のキモは、速度を「体感」ではなくAPIの返す数値から計算することです。Ollamaの /api/generate はレスポンスに eval_count(生成したトークン数)と eval_duration(生成にかかった時間・ナノ秒)を返してくれます。この2つを割れば tokens/sec が正確に出ます。
GPUで動かす場合とCPUのみで動かす場合で、実際に叩いたコマンドと返ってきた数値が以下です。同じ llama3.2:1b に同じプロンプトを与え、num_gpu だけを変えています。
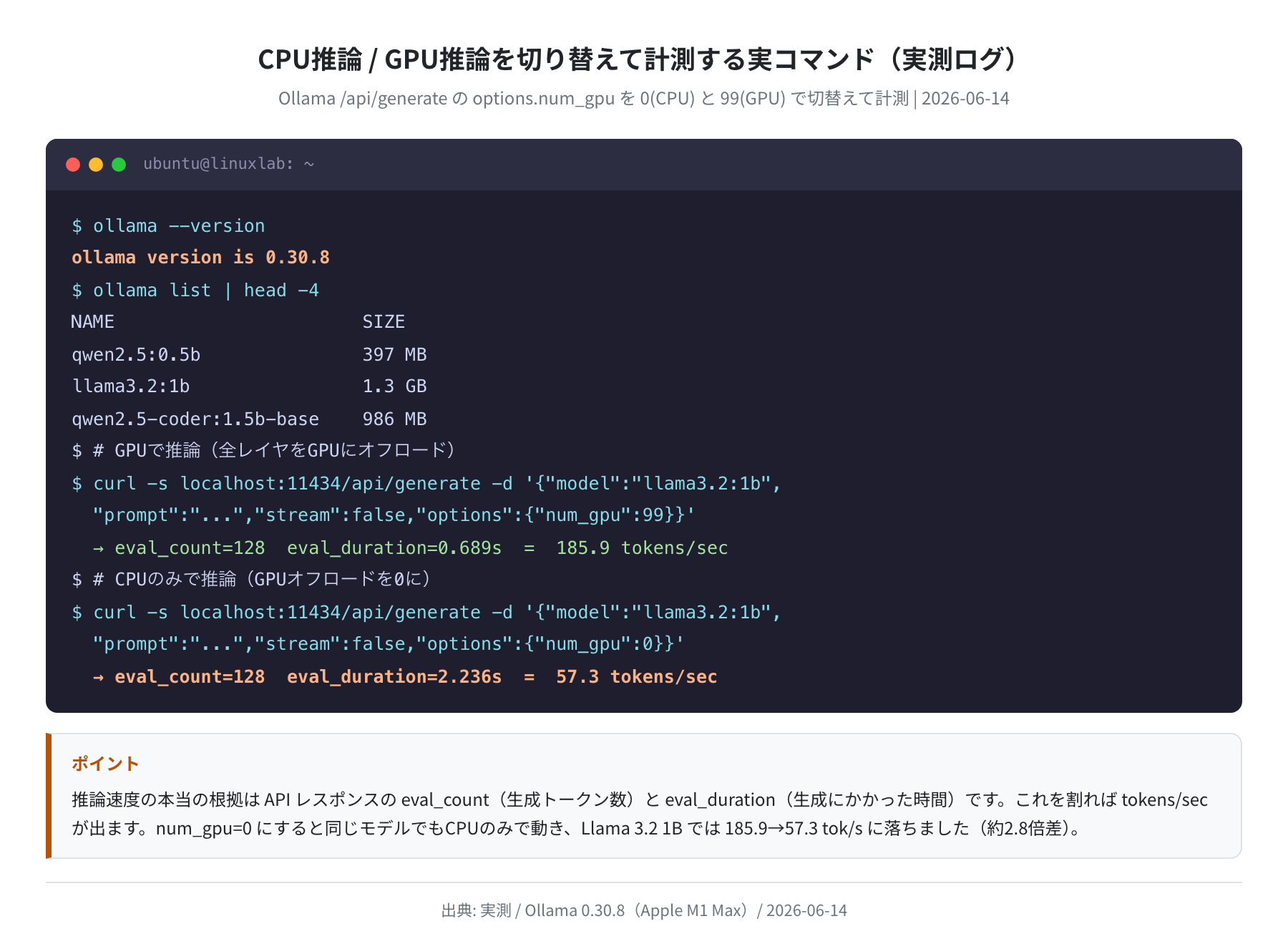
このように options.num_gpu を 0 にするだけで、同じモデルがCPUのみで動きます。あとはこれを各モデルで3回ずつ繰り返し、平均を取りました。
計測のばらつきについて
LLMの推論速度は、その時のメモリ常駐状態やバックグラウンド処理で多少ぶれます。本記事では各条件で3回計測し、平均値と最小〜最大の変動幅をすべて掲載しています。1回だけの計測値を鵜呑みにしないことが大切です。
CPU推論 vs GPU推論 の実測結果
では本題の結果です。3モデル × CPU/GPU × 3回計測の平均を、まずグラフで見てみましょう。
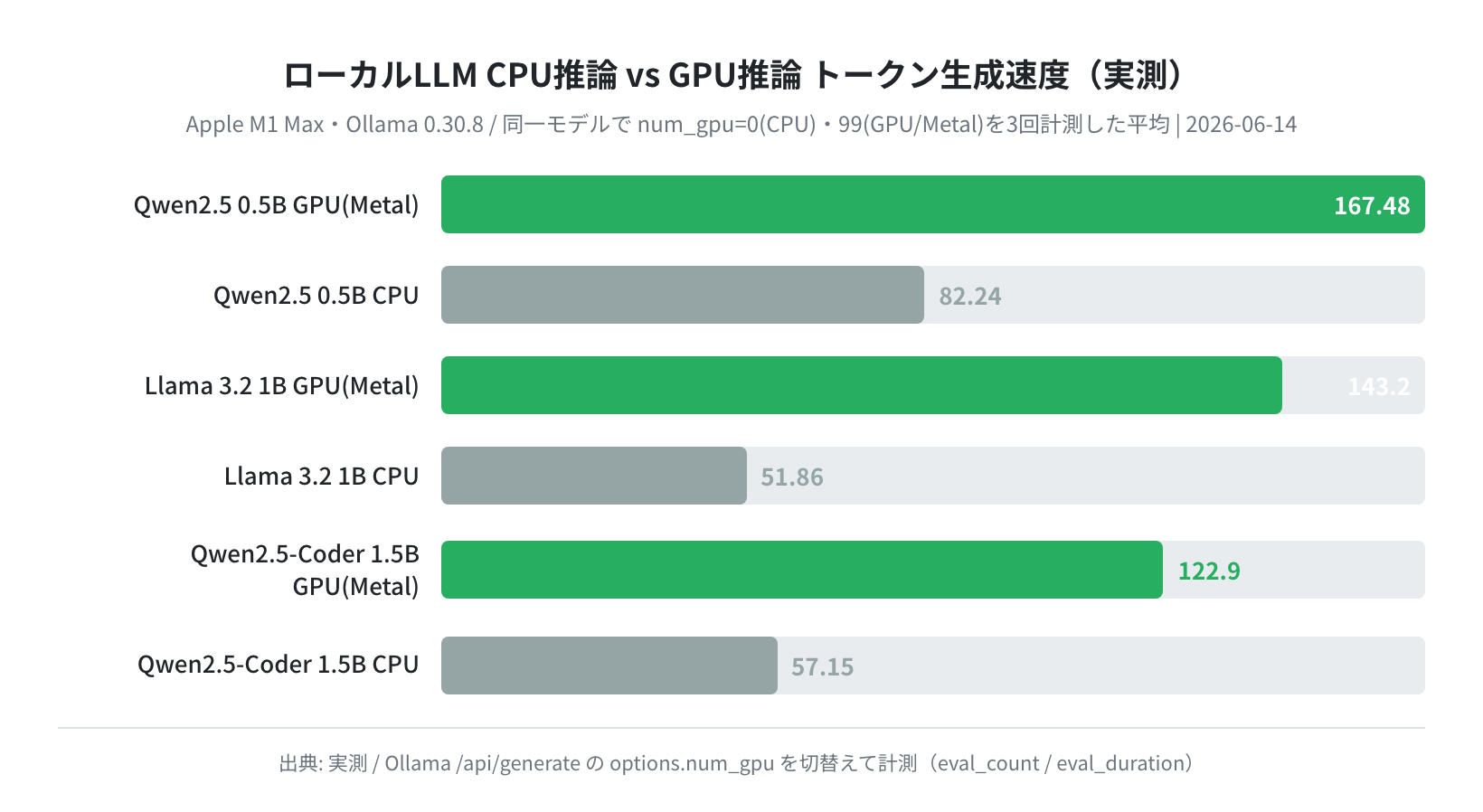
緑がGPU(Metal)、グレーがCPUのみです。一目で分かるとおり、どのモデルでもGPUのほうが速いものの、その差は2〜3倍程度に収まりました。数値を表でも確認します。

| モデル | GPU(Metal) 平均 | CPU 平均 | 速度比 |
|---|---|---|---|
| Qwen2.5 0.5B | 167.5 tokens/sec | 82.2 tokens/sec | ×2.04 |
| Llama 3.2 1B | 143.2 tokens/sec | 51.9 tokens/sec | ×2.76 |
| Qwen2.5-Coder 1.5B | 122.9 tokens/sec | 57.2 tokens/sec | ×2.15 |
ここで注目してほしいのは、CPUのみでも50〜80 tokens/sec 出ているという点です。人が文章を読む速度はだいたい毎秒5〜10トークン程度なので、CPUでもその5〜10倍の速さで生成できていることになります。つまり小型モデルに関しては、「CPUだと遅すぎて使い物にならない」というのは事実ではありませんでした。
正直、この結果は意外でした。ネットでは「ローカルLLMはGPU必須」とよく見かけますが、少なくとも0.5B〜1.5Bクラスならば、GPUなしでも十分に会話できる速度です。GPUの「数十倍速い」という話は、もっと大きいモデルやNVIDIAの独立GPUでの話なんですね。
なお、モデルが少し大きくなる(0.5B→1.5B)とGPU側の絶対速度は下がっていきます。これはGPUでも計算量が増えるためです。一方でCPUは元々の速度がそれほど高くないぶん、モデルサイズによる落ち込みが緩やかで、結果として速度比が2倍前後で安定しているのが今回の特徴です。
なぜGPUは速いのか — レイヤのオフロードの仕組み
そもそも、なぜGPUのほうが推論が速いのでしょうか。LLMの推論は、ざっくり言うと巨大な行列のかけ算を何回も繰り返す処理です。この行列演算は並列に計算できるため、数千個の小さなコアを持つGPUのほうが、十数コアのCPUより一度に多くの計算をこなせます。
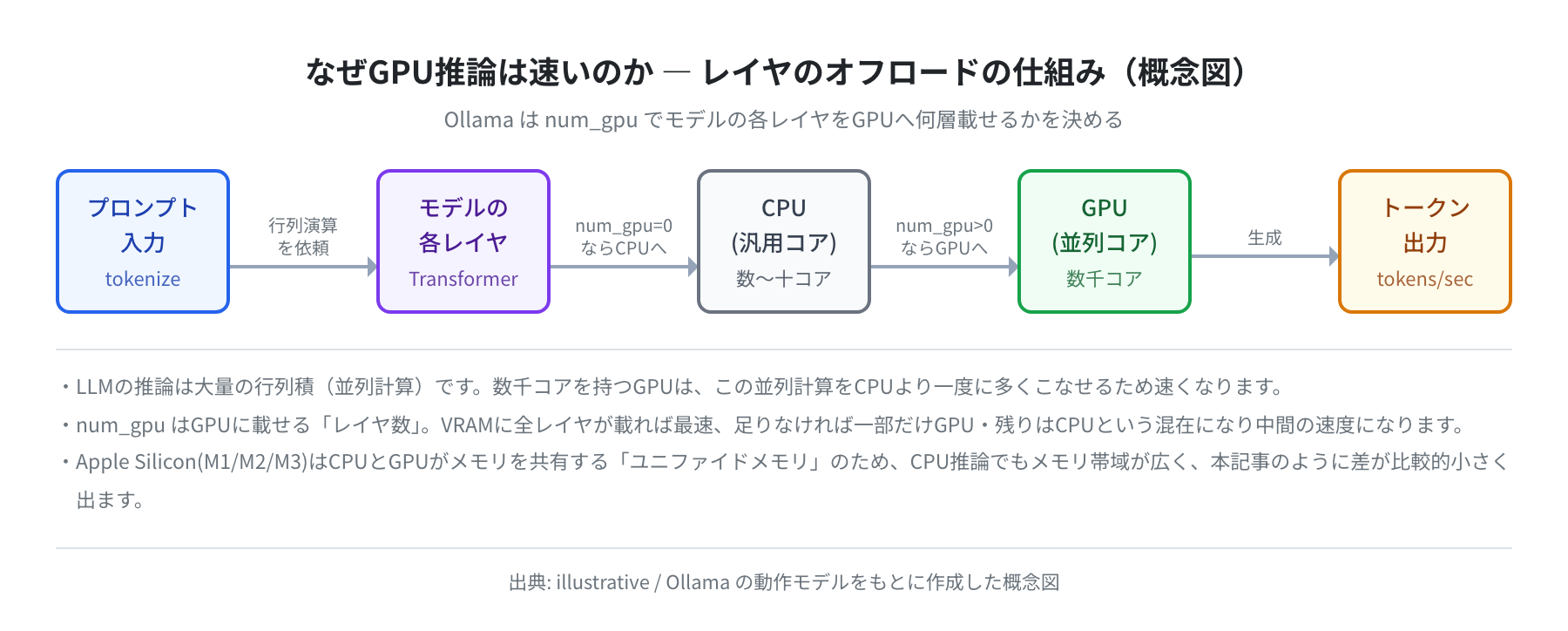
Ollamaの num_gpu は、このモデルの「レイヤ(層)」をGPUに何層載せるかを指定するオプションです。num_gpu=99 のように大きな値を入れると全レイヤがGPUに載り、最速になります。逆に 0 にすると1層もGPUに載せず、すべてCPUで計算します。
ここで重要なのが VRAM(GPUのメモリ) です。モデル全体がVRAMに収まれば全レイヤをGPUに載せられますが、収まらないと一部だけGPU・残りはCPUという「混在」になり、速度は中間になります。大きいモデルを速く動かすには、それに見合うVRAMのGPUが必要、というのはこのためです。
そして今回CPUとGPUの差が比較的小さかった理由が、Apple Silicon(M1/M2/M3)の「ユニファイドメモリ」です。CPUとGPUが同じメモリ空間を共有しているため、CPU推論でもメモリ帯域が広く、CPUが思いのほか健闘します。NVIDIAの独立GPUを積んだPCでは、CPUとGPUでメモリが分かれているぶん、この差はもっと大きく出ると考えてください。
CPUのコンピュート能力も実測する(sysbench)
CPU推論の速度は、当然そのCPUの計算能力に左右されます。参考までに、今回のマシンのCPU性能を sysbench(定番のベンチマークツール)で計測しておきました。ubuntu:24.04 のDockerコンテナ内で3回実行した結果です。
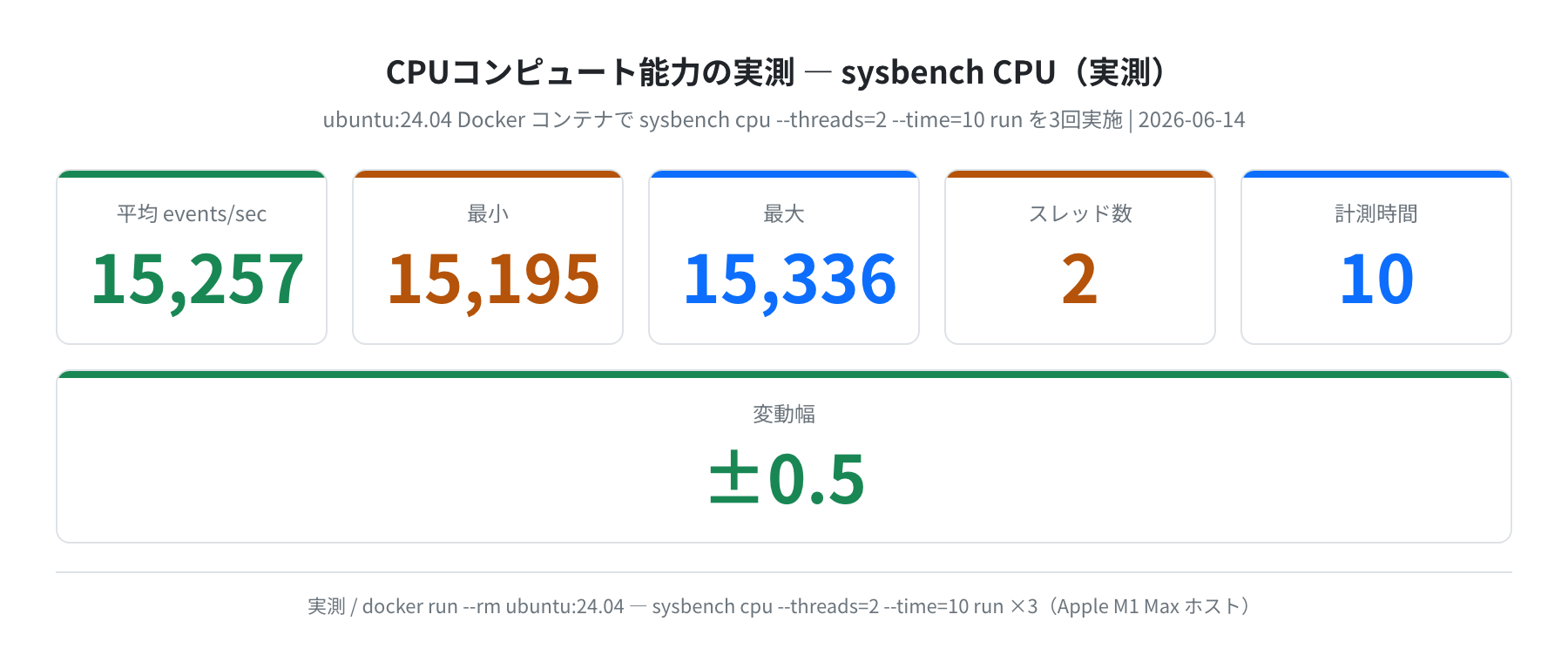
“apt-get install -y sysbench && sysbench cpu –threads=2 –time=10 run”
CPU speed:
events per second: 15194.68
events per second: 15242.28
events per second: 15335.64
# 3回平均: 15,257 events/sec(最小15,195〜最大15,336、変動±0.5%)
3回でほとんどブレずに15,257 events/sec前後でした。このくらいの計算能力があるCPUであれば、小型モデルのCPU推論は十分実用域に入る、というのが今回の体感です。VPSを借りるときも、まずはこの程度のCPU性能があるかを目安にすると良いでしょう。
Open WebUI で実際に動かしてみる
コマンドだけだとイメージが湧きにくいので、実際にブラウザから使う様子も見てみましょう。Open WebUI(OllamaにブラウザのチャットUIを付けるツール)をDockerで起動し、先ほどのモデルにつないだ画面が以下です。
ghcr.io/open-webui/open-webui:main
# → ブラウザで http://localhost:3000 を開く
上の画面のように、ChatGPTのようなチャットUIから自分のローカルモデルに話しかけられます。どのモデルを選ぶかは画面左上から切り替えられます。「どんなモデルがあるのか分からない」という方は、Ollama公式のモデルライブラリを見ると、各モデルのサイズ(=必要なメモリ/VRAMの目安)が確認できます。
このライブラリで 1.5b や 8b といったタグがモデルサイズです。最初はサイズの小さいモデルを選べば、GPUがなくても今回の実測のように快適に動かせます。
CPU推論で十分なケース / GPU推論が必要なケース
実測をふまえて、CPUで十分なケースとGPUが要るケースを整理しておきます。
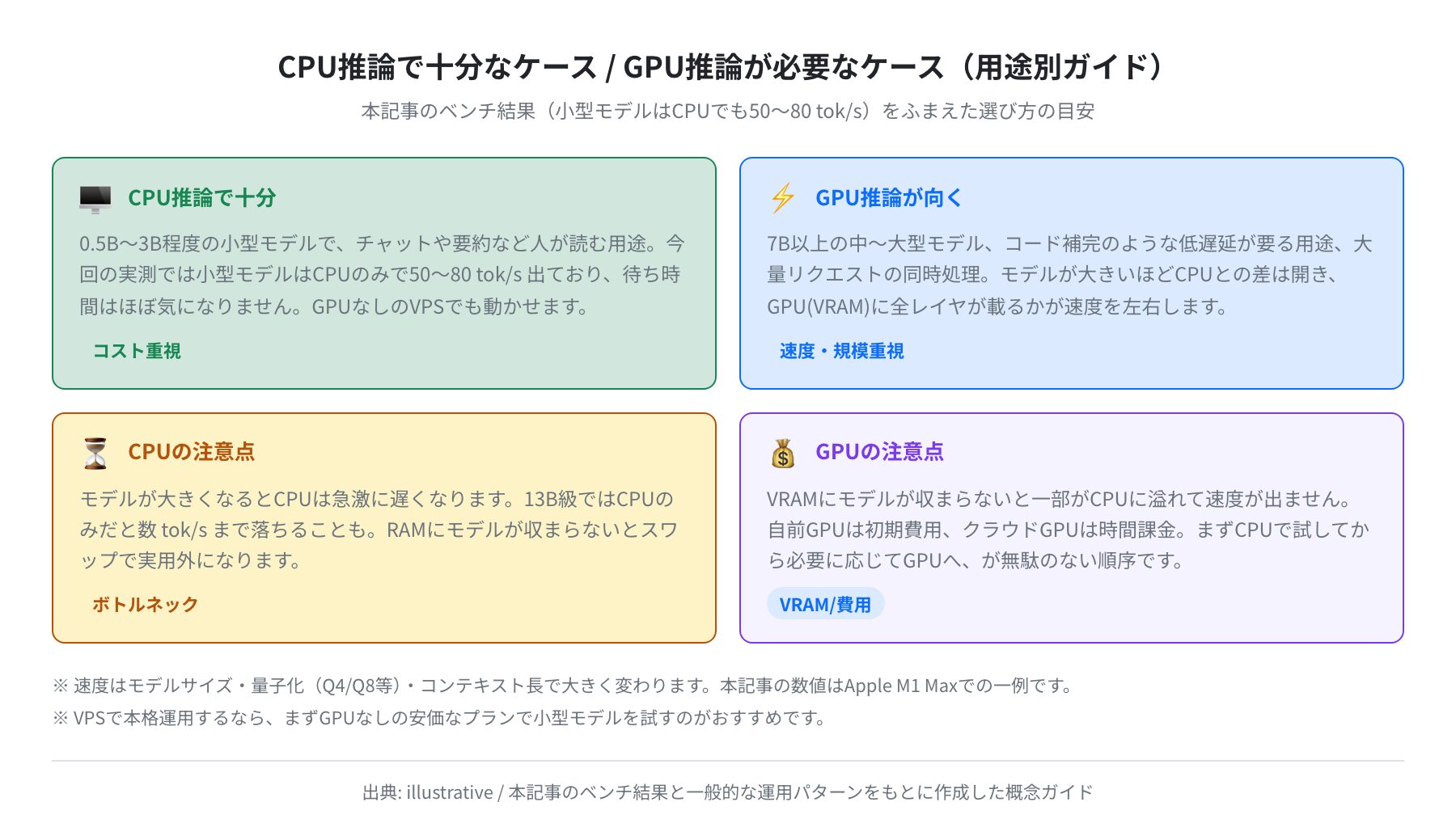
ざっくりまとめると、0.5B〜3B程度の小型モデルで、チャットや要約のような「人が読む」用途ならCPUで十分です。一方、7B以上の中〜大型モデルを使いたい、コード補完のように低遅延が要る、たくさんのリクエストを同時にさばきたい、といった場合はGPUの恩恵が大きくなります。
モデルが大きくなるほどCPUは急に遅くなり、13Bクラスではメモリにも収まりにくくなって一気に実用外になることもあります。逆にGPUも、VRAMにモデルが載りきらないと一部がCPUに溢れて速度が出ません。まずCPUで小さいモデルを試し、足りなければGPUへ、という順序が一番ムダがありません。
自宅のPCにGPUがない場合でも、VPSを借りればサーバー上でローカルLLMを動かせます。小型モデルならGPUなしの安価なプランでも今回のように動きますし、本格的に大きいモデルを使いたくなったらGPU付きプランへ移行する、という育て方ができます。VPS各社の実測比較は別記事でまとめているので、あわせて参考にしてください。
よくあるエラーと解決策
① num_gpu を指定しても速度が変わらない
ホストにGPUがない、もしくはOllamaがGPUを認識していない場合、num_gpu=99 にしても自動的にCPUで動くため速度は変わりません。ollama ps を実行すると、現在のモデルが GPU と CPU のどちらで動いているか(PROCESSOR列)を確認できます。
② モデルのロードに毎回時間がかかる
1回目の生成は、モデルをディスクから読み込む時間(load_duration)が加わります。今回の計測でも初回だけ1〜3秒ほど余計にかかりました。2回目以降はモデルがメモリに常駐するため速くなります。常駐時間は OLLAMA_KEEP_ALIVE 環境変数で調整できます。
③ 大きいモデルを動かすとマシンが固まる
モデルがRAM(GPUの場合はVRAM)に収まらないと、スワップが発生して極端に遅くなったり固まったりします。自分のメモリ容量に対してモデルが大きすぎないか、Ollamaライブラリのサイズ表記で事前に確認しましょう。迷ったら一段小さいモデルか、より強い量子化(Q4_K_M など)を選ぶのが安全です。
まとめ
この記事のまとめ
- 同一マシン・同一モデルで num_gpu を切り替えて計測した結果、GPU(Metal)はCPUの約2.0〜2.8倍だった
- CPUのみでも小型モデルなら50〜80 tokens/sec 出ており、チャットや要約には十分実用的
- GPUの差が大きく出るのは大型モデル・低遅延用途・大量同時処理のとき
- Apple Silicon はユニファイドメモリのため、CPUとGPUの差が比較的小さく出る
- まずCPUで小型モデルを試し、必要になったらGPUへ移行するのが無駄のない順序
「ローカルLLMにはGPUが必須」というイメージは、少なくとも小型モデルに関しては誇張でした。手元のPCでもVPSでも、まずはCPUで小さいモデルを動かしてみて、物足りなくなったらGPUを検討する——その順序であれば、お金をかけずにローカルLLMの世界に入れます。
サーバー上でローカルLLMを常時動かしたい方は、GPUなしの小型VPSから始めるのがおすすめです。VPS各社のCPU・ディスク性能の実測比較は こちらの記事 でまとめているので、プラン選びの参考にしてください。
コメント