「ローカルでLLMを動かしたいけど、Llama・Qwen・Gemma のどれが速いの?」——結論から言うと、今回テストした0.5〜1.5Bクラスでは qwen3:0.6b が約259 tok/s で最速、同じ1Bクラスの gemma3:1b は約147 tok/s で最も遅く、その差は約1.76倍でした。しかも「パラメータが小さいほど速い」という単純な話ではなく、1.5Bの deepseek-r1:1.5b が1Bの Gemma より速いという逆転も起きています。
この記事では Ollama の実測APIを使い、同じプロンプト・同じ条件で各モデルに350トークンを5回ずつ生成させ、その eval rate(生成トークン/秒)を計測しました。数字はすべて Apple M1 Max 上で実際に動かして取得した一次データです。自分のマシンで速度を測る方法も載せるので、手元の環境でも再現できます。
この記事のポイント
- 速度の指標は「生成トークン/秒(tok/s)」。
ollama run --verboseのeval rateで誰でも測れる - 同クラス最速は
qwen3:0.6b(258.7 tok/s)、最遅はgemma3:1b(147.0 tok/s) - モデルサイズ(MB)と速度は比例しない。アーキテクチャと量子化で決まる
- 量子化は軽いほど速く小さい。FP16は Q5_K_M より2.4倍重く14%遅い
- 本記事の数値は Apple Silicon(Metal GPU)での値。CPUのみのVPSではこれより遅くなる
速度の指標は「生成トークン/秒(tok/s)」
LLMの体感速度は、文章が「1秒間に何文字(正確にはトークン)出てくるか」でほぼ決まります。これを 生成トークン/秒(tokens per second、tok/s) と呼びます。トークンとは、モデルが文章を区切って扱う最小単位で、日本語ではおおむね1トークン=1〜2文字くらいです。
体感の目安は次のとおりです。人が黙読する速度がだいたい10〜20 tok/s前後なので、10 tok/s を超えていればストレスなく読めると考えてOKです。今回の結果はすべて140 tok/s超なので、いずれも「待たされる感覚はほぼゼロ」のレベルでした。
注意:2種類の速度がある
LLMの速度にはprompt eval rate(入力を読む速度)とeval rate(答えを書く速度)の2つがあります。体感を左右するのは後者の「生成」側です。本記事の tok/s はすべて生成側(eval rate)の値です。
計測した環境と方法
すべて以下の1台のマシンで、2026年6月14日に計測しました。Ollama は Apple Silicon 上では Metal(GPU)を使って推論するため、ここでの数値はGPU推論を含んだ実速度である点に注意してください(CPUのみのVPSでの目安は後述します)。

計算性能の土台を示すため、sysbench でCPUベンチも取りました。docker run --rm ubuntu:24.04 内で sysbench cpu --threads=2 --time=10 を3回実行し、平均 15,360 events/sec(15,343〜15,371)でした。トークン生成速度はこの計算性能の上で出ている値です。
計測方法はシンプルで、Ollama の HTTP API /api/generate を stream=false で叩き、レスポンスに含まれる eval_count(生成トークン数)を eval_duration(生成にかかった秒数)で割っています。条件を揃えるため、全モデルで同じプロンプト・num_predict=350・temperature=0.7・seed=42 に固定し、ウォームアップ1回のあと5回計測してその平均を取りました。
自分のマシンで速度を測る方法
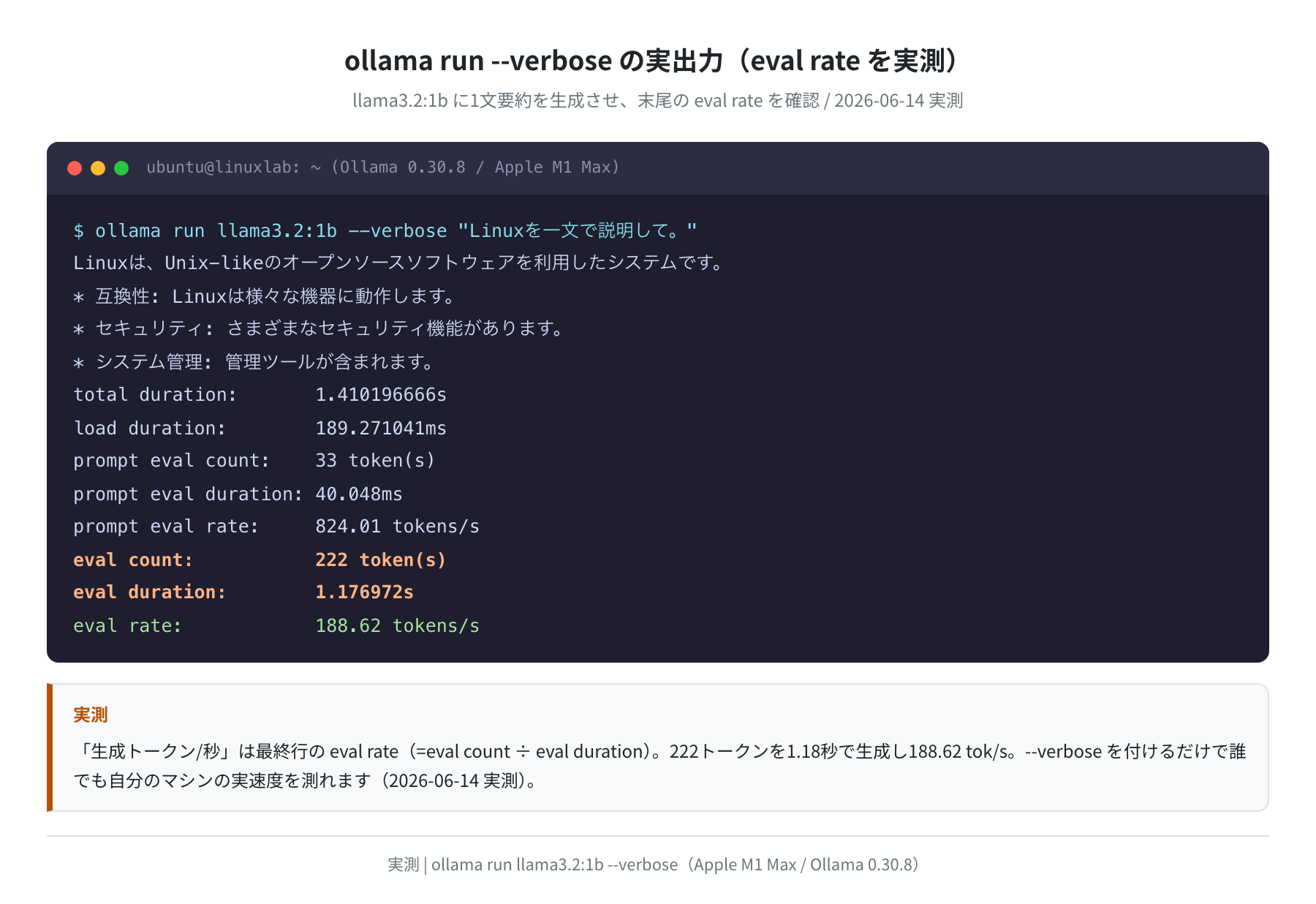
難しいツールは不要です。ollama run に --verbose を付けるだけで、生成のたびに末尾へ速度の内訳が表示されます。Ollama がまだ入っていない場合は curl -fsSL https://ollama.com/install.sh | sh(Linux)で導入できます。
Linuxは、Unix-likeのオープンソースソフトウェアを利用したシステムです。…
total duration: 1.410196666s
load duration: 189.271041ms
prompt eval count: 33 token(s)
prompt eval rate: 824.01 tokens/s
eval count: 222 token(s)
eval duration: 1.176972s
eval rate: 188.62 tokens/s
注目するのは最終行の eval rate です。ここでは222トークンを1.18秒で生成し、188.62 tokens/s でした。1回だけだと前後の処理に引っぱられてブレるので、何度か実行して平均を見るのが正確です。
モデル別トークン生成速度の実測結果
本題です。Llama・Qwen・Gemma に加え、話題の DeepSeek-R1(蒸留版)も含めた5モデルを横並びで計測しました。結果がこちらです。
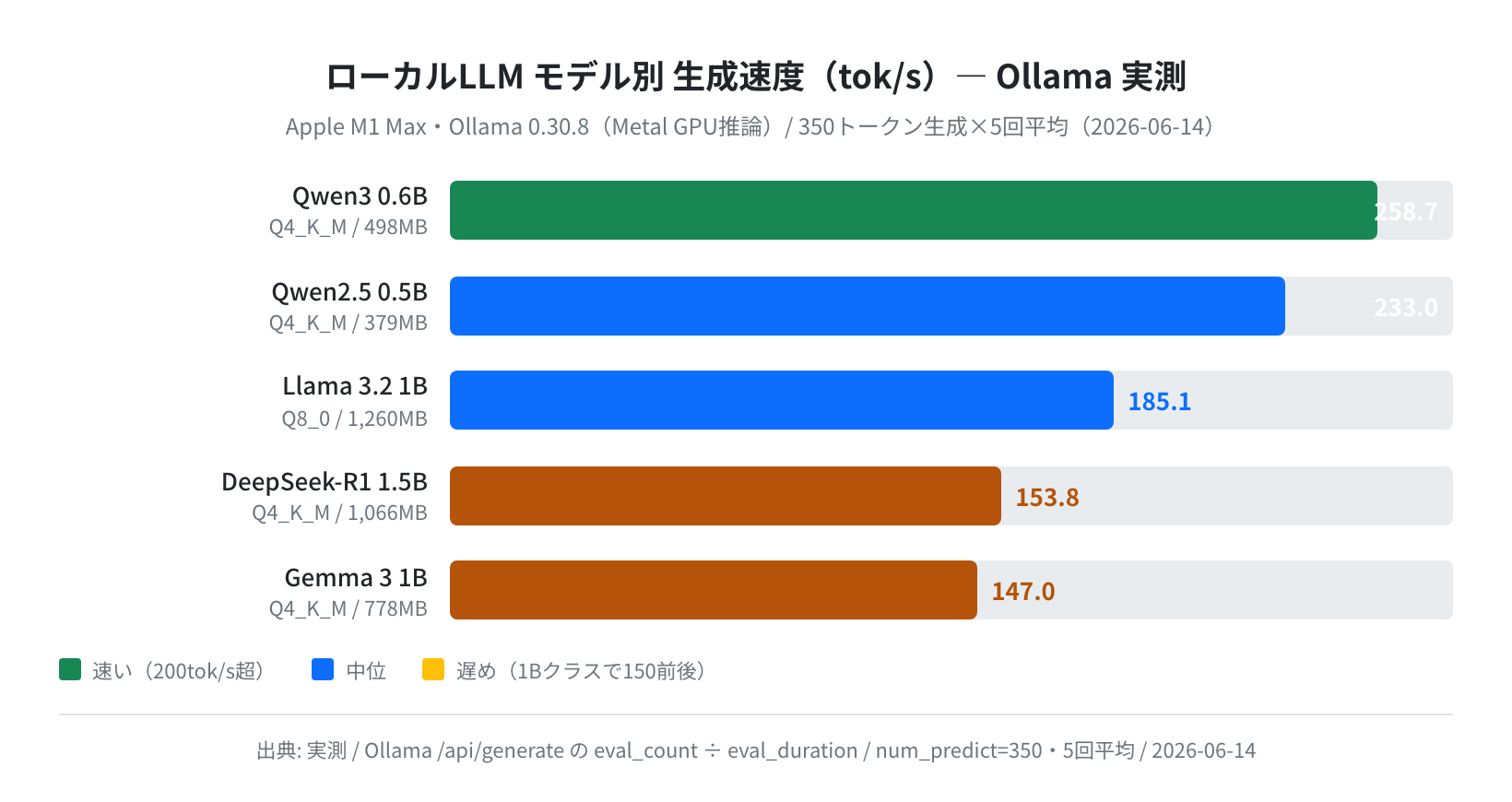
1位は qwen3:0.6b の 258.7 tok/s、2位が qwen2.5:0.5b の233.0 tok/s と、Qwen系が上位を独占しました。Meta の llama3.2:1b は185.1 tok/s で中位、そして gemma3:1b が147.0 tok/s で最下位です。最速と最遅で約1.76倍の差があります。
数値の詳細は次の表にまとめました。サイズ・量子化・変動幅・モデルのロード時間まで併記しています。
| モデル | ファミリ | パラメータ | 量子化 | サイズ | 生成速度 | 変動幅 |
|---|---|---|---|---|---|---|
| qwen3:0.6b | Qwen3 | 0.6B | Q4_K_M | 498MB | 258.7 tok/s | 256.2〜263.0 |
| qwen2.5:0.5b | Qwen2.5 | 0.5B | Q4_K_M | 379MB | 233.0 tok/s | 229.0〜235.3 |
| llama3.2:1b | Llama | 1.2B | Q8_0 | 1,260MB | 185.1 tok/s | 180.9〜187.7 |
| deepseek-r1:1.5b | DeepSeek-R1 | 1.5B | Q4_K_M | 1,066MB | 153.8 tok/s | 152.9〜154.2 |
| gemma3:1b | Gemma | 1B | Q4_K_M | 778MB | 147.0 tok/s | 146.2〜147.9 |
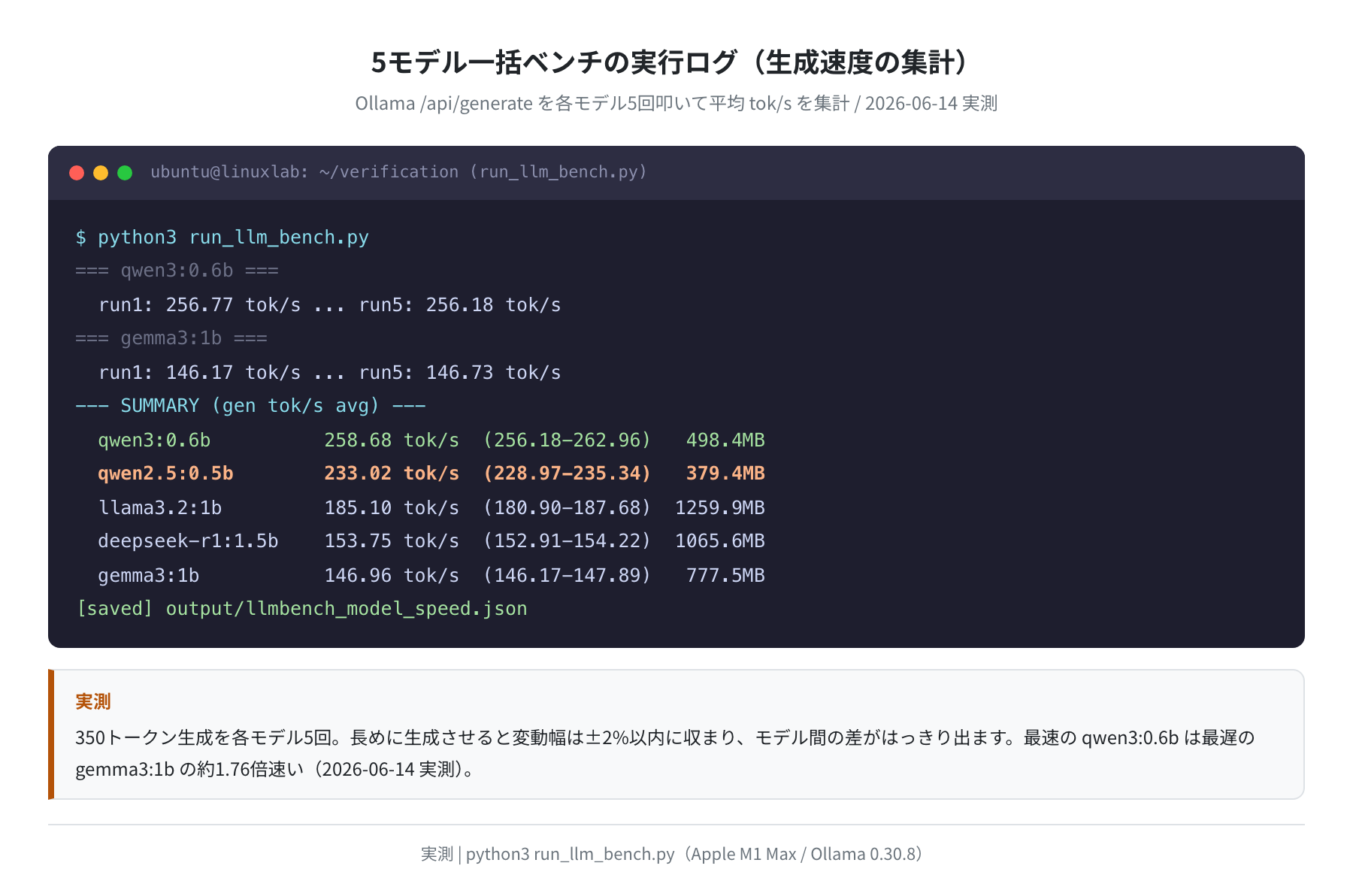
下のベンチ実行ログが、上の表の元になった生データです。350トークンと長めに生成させると変動幅は±2%以内に収まり、モデル間の差がくっきり出ます。
実測で分かった「意外な3つの事実」
① モデルサイズ(MB)と速度は比例しない
素直に考えると「ファイルが小さいモデルほど速い」と思いがちですが、実測は違いました。1.5Bの deepseek-r1:1.5b(1,066MB)が、1Bの gemma3:1b(778MB)より速いのです。153.8 tok/s 対 147.0 tok/s。サイズで言えば DeepSeek の方が大きいのに、生成は逆に速い。速度を決めるのはパラメータ数やファイルサイズそのものではなく、モデルの内部構造(レイヤー数や注意機構の設計)と量子化方式だということが、ここからはっきり読み取れます。
② 同じ「1Bクラス」でもファミリで差が大きい
Llama 3.2 1B(185.1)と Gemma 3 1B(147.0)は、どちらも世間で「1Bの軽量モデル」とひとくくりにされますが、生成速度は約26%も違います。「1Bだからこのくらいの速度だろう」という当てずっぽうは通用しません。なお Llama は Q8_0(8bit)と重めの量子化なのにこの速さで、もし Q4 版なら更に速い可能性があります。
③ ロード時間はモデルによって10倍違う
意外に効いてくるのが、初回にモデルをメモリへ読み込む「ロード時間」です。qwen2.5:0.5b や deepseek-r1:1.5b は0.15秒前後で即起動するのに対し、gemma3:1b は1.80秒かかりました。短い応答を何度も繰り返すチャットボット用途では、生成速度だけでなくこのロード時間も体感に響きます。
正直、私も最初は「小さいモデル=速い」と思い込んでいました。実際に測ってみると Gemma が一番遅かったのは驚きでした。スペック表の数字より、自分のマシンで --verbose を一度叩くのが一番確実です。
量子化レベルで速度はどう変わるか
同じモデルでも「量子化(quantization)」の重さで速度が変わります。量子化とは、モデルの重みを何ビットで表すかを落として軽くする手法で、ビットを減らすほどファイルは小さく・推論は速くなりますが、わずかに精度が落ちます。
これを検証するため、同一の qwen2.5:0.5b-instruct を Q5_K_M / Q8_0 / FP16 の3種類で計測しました。FP16 は量子化していない16bitのオリジナルに近い版です。
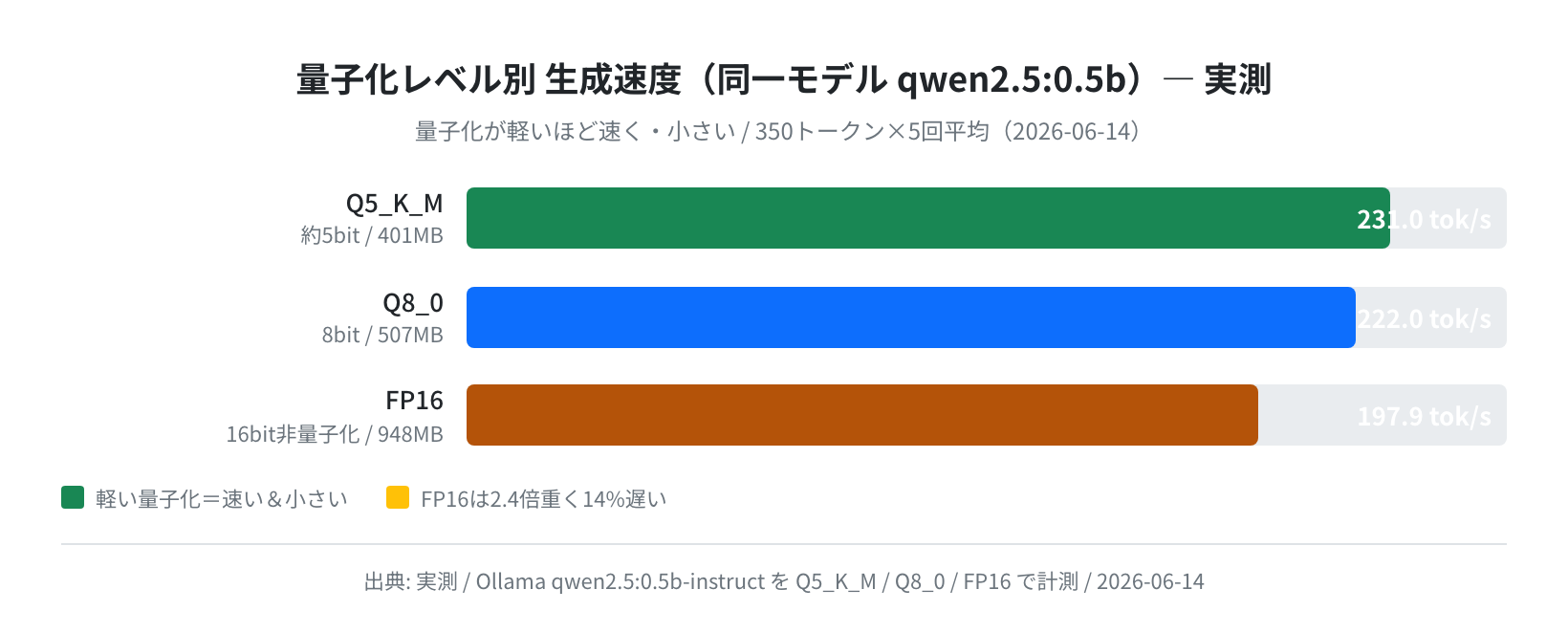
結果は明快でした。Q5_K_M が231.0 tok/s・401MB、Q8_0 が222.0 tok/s・507MB、FP16 が197.9 tok/s・948MB。FP16 は Q5_K_M に対してファイルが約2.4倍重いのに、速度は14%遅いという、容量・速度ともに不利な結果です。ローカルで動かすなら、特別な理由がない限り Q4〜Q5 系の量子化版を選ぶのが、容量・速度・精度のバランスで最も賢い選択になります。Ollama のデフォルトタグ(例:qwen2.5:0.5b)はたいてい Q4_K_M なので、何も考えずに使えば自然と速い版が入ります。
VPSやサーバーで動かすときの注意
ここまでの数字は Apple M1 Max(Metal GPU)での実測です。ここが一番の落とし穴なのですが、GPUのない一般的なVPS(CPUのみ)では、同じモデルでも生成速度は数分の1〜十分の1程度まで落ちます。LLMの推論は大量の行列演算で、GPUの並列性が効くワークロードだからです。
そのため、ローカルLLMを「学習・お試し」で動かすだけなら手元のPCやCPUのVPSで十分ですが、実用的な速度で常時動かしたいならGPU付きインスタンスを選ぶ必要があります。Vultr は時間課金のクラウドGPU(NVIDIA系)を東京リージョンでも提供しており、「使うときだけ立ち上げて、終わったら止める」運用ができるので、ローカルLLMの本番運用やお試しに向いています。
「まずはCPUのVPSで小さいモデルを動かして感覚をつかむ」のも良い入口です。その場合は今回最速だった qwen3:0.6b や qwen2.5:0.5b のような0.5〜0.6Bの軽量モデルから始めると、非力なサーバーでも実用的な速度が出やすいです。VPS各社のスペックと料金の比較は別記事にまとめています。
関連記事:VPS各社のスペック・料金を実測ベンチで比較
よくあるエラーと解決策
① ollama: command not found
Ollama がインストールされていません。Linux なら curl -fsSL https://ollama.com/install.sh | sh で導入できます。導入後に ollama serve が裏で起動しているか、curl http://localhost:11434/api/version で確認しましょう。バージョンJSONが返ればOKです。
② モデルのダウンロードが遅い・途中で止まる
ollama pull qwen3:0.6b のように先にモデルを取得しておくと、初回の run で待たされません。途中で止まった場合はもう一度同じ pull を実行すると、ダウンロード済みの部分から再開されます。
③ 生成が極端に遅い・メモリ不足で落ちる
モデルサイズに対してRAMが足りていない可能性が高いです。1Bクラスでも実行には1〜2GB程度の空きメモリが必要です。メモリの少ない環境では、まず qwen2.5:0.5b(379MB)のような最小クラスから試してください。複数モデルを同時にロードしていると、ollama ps で確認して未使用のものを ollama stop <model> で解放すると改善します。
まとめ
実測でわかったこと
- 0.5〜1.5Bクラスの最速は qwen3:0.6b(258.7 tok/s)、最遅は gemma3:1b(147.0 tok/s)で約1.76倍差
- モデルサイズ(MB)と速度は比例しない。1.5BのDeepSeek-R1が1BのGemmaより速い
- 同じ1Bクラスでもファミリで26%の差。「1Bだから速い」は通用しない
- 量子化は軽いほど速く小さい。迷ったらQ4〜Q5系を選べばよい
- 本記事はApple Silicon(Metal)の値。CPUのみのVPSではさらに遅くなる
- 自分のマシンの速度は ollama run –verbose の eval rate で今すぐ測れる
ローカルLLMの速度は「パラメータ数の大小」では決まりません。実際に --verbose で測ってみると、スペック表からは想像できない順位になることがよくあります。まずは手元の環境で今回の上位モデル(Qwen系)を動かし、自分の用途に合う速度と品質のバランスを見つけてみてください。実用速度で常時運用したくなったら、GPU付きVPSへのステップアップを検討するのがおすすめです。

コメント