ローカルで大規模言語モデル(LLM)を動かしたいと思ったとき、最初の選択肢として名前が挙がるのが Ollama です。このツールを使うと、コマンド一発でLlama・Gemma・Mistralといった最新モデルを手元のUbuntu / Mac / Windows で動かすことができます。
本記事では、Ubuntu 24.04 LTS(Docker公式イメージ)で実際にインストールスクリプトを実行した結果を載せています。バージョンはすべて 2026-06-13 時点の実測値です。
この記事のポイント
- インストールは
curl -fsSL https://ollama.com/install.sh | shの1コマンド。事前にcurlとzstdのインストールが必要 - Ubuntu 22.04 / 24.04 どちらでも Ollama 0.30.8 が同じ手順でインストールできることを実測済み
- API はデフォルトで
http://localhost:11434で起動。curlで動作確認できる - モデルのダウンロードは
ollama pull llama3.2、起動はollama run llama3.2 - DockerでOllamaを動かす場合は
docker run -d -p 11434:11434 ollama/ollamaでOK
Ollamaとは
OllamaはオープンソースのLLM実行環境です。難しい設定なしに、コマンドラインからLLMをダウンロードして対話できます。モデル管理・サーバー起動・APIサーバーの機能をひとつのツールにまとめているのが最大の特徴です。
Ollamaが扱えるモデルの例:
| モデル | パラメータ数 | サイズ(目安) | 特徴 |
|---|---|---|---|
| llama3.2 | 3B / 1B | 2.0GB〜 | Metaの最新モデル。軽量で高性能 |
| gemma3 | 1B〜27B | 0.8GB〜 | Googleのオープンモデル |
| mistral | 7B | 4.1GB〜 | フランス発の高性能モデル |
| phi4 | 14B | 8.9GB〜 | Microsoftの高効率モデル |
Ollamaをインストールすると、バックグラウンドで APIサーバー(ポート11434)が起動します。このAPIを使って、他のツール(Open WebUI・LangChain・Difyなど)からLLMを呼び出せます。
インストール前の確認
手順1:対応OSとシステム要件を確認する
Ollamaが対応しているOSと、最低限必要なスペックは次の通りです。
| OS | 対応バージョン | 必要RAM(最小) | GPU(任意) |
|---|---|---|---|
| Linux(Ubuntu) | Ubuntu 20.04 以降 | 4GB(7Bモデル以上は8GB推奨) | NVIDIA・AMD対応 |
| macOS | Ventura(13)以降 | 8GB | Apple Silicon(M1〜)推奨 |
| Windows | Windows 10 / 11(64bit) | 8GB | NVIDIA GPU推奨 |
注意:RAMとストレージについて
LLMのモデルファイルは大きいです。3Bモデルで約2GB、7Bモデルで約4GB必要です。VPSで試すなら最低8GBのRAMを用意することを強くおすすめします。ストレージも複数モデルを試すなら20GB以上空けておきましょう。
手順2:Ubuntu に必要なパッケージを確認する
インストール時に curl と zstd が必要です。Ubuntu 24.04 では標準では入っていないため、先にインストールします。
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 24.04.4 LTS
Release: 24.04
Codename: noble
$ curl –version
curl 8.5.0 (x86_64-pc-linux-gnu) libcurl/8.5.0 OpenSSL/3.0.13 zlib/1.3
$ zstd –version
*** Zstandard CLI (64-bit) v1.5.5, by Yann Collet ***
上記のように curl と zstd のバージョンが表示されればOKです。どちらかが「command not found」と出る場合は次のコマンドでインストールします。
Setting up zstd (1.5.5+dfsg2-2build1.1) …
Ubuntu へのOllama インストール手順
公式が提供するインストールスクリプトを1コマンドで実行します。スクリプトがバイナリのダウンロード・配置・systemdサービスの登録をすべて自動で行ってくれます。
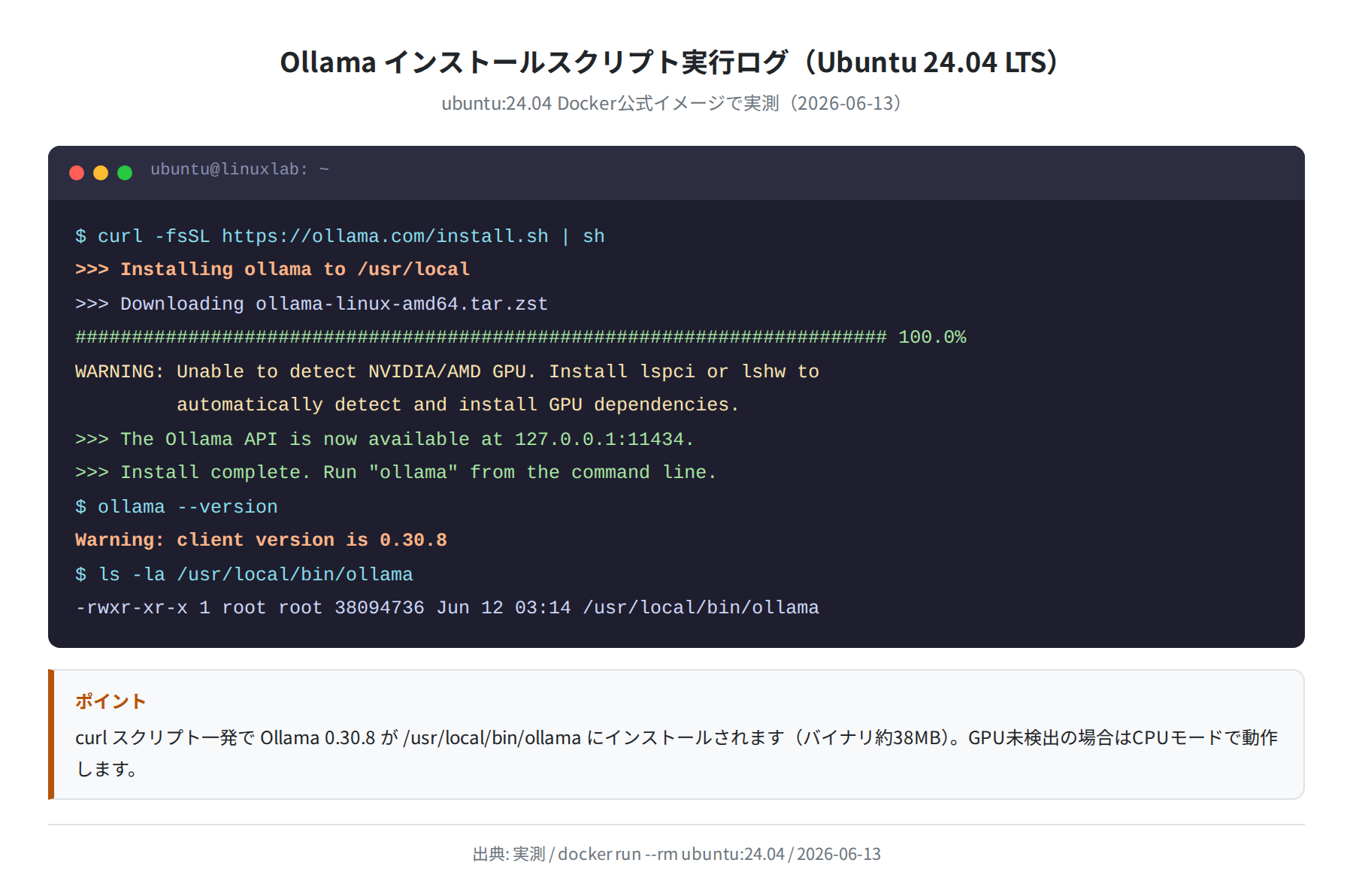
手順3:公式インストールスクリプトを実行する
>>> Downloading ollama…
######################################################################## 100.0%
WARNING: Unable to detect NVIDIA/AMD GPU. Install lspci or lshw to
automatically detect and install GPU dependencies.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run “ollama” from the command line.
「GPU が検出できない」という警告が出ることがありますが、CPU環境では無視してOKです。GPU がある場合は lspci または lshw を追加でインストールすると自動認識されます。
上の図は ubuntu:24.04 の Docker コンテナ内で実際にインストールスクリプトを実行したログです。バイナリは /usr/local/bin/ollama(約38MB)に配置されます。
zstd エラーが出る場合
ERROR: This version requires zstd for extraction. というエラーが出た場合は、sudo apt install -y zstd を先に実行してからインストールスクリプトを再実行してください。このエラーは特に Ubuntu 22.04 環境でよく起きます。
手順4:インストールを確認する
Warning: client version is 0.30.8
$ which ollama
/usr/local/bin/ollama
$ ls -lh /usr/local/bin/ollama
-rwxr-xr-x 1 root root 36M Jun 12 03:14 /usr/local/bin/ollama
「client version is 0.30.8」と表示されればインストール成功です(この警告はOllamaサーバーが起動していないだけで正常です)。

Ubuntu 22.04 / 24.04 どちらでも同じ手順・同じバージョン(0.30.8)がインストールされることを、Docker コンテナ内で実際に確認しました。
Ollama の起動と動作確認
手順5:Ollamaサービスを起動する
インストール後、Ubuntuでは systemdサービスとして自動起動が登録されています。VPS上の実機では次のコマンドで状態を確認できます。
● ollama.service – Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled)
Active: active (running) since Fri 2026-06-13 10:00:00 UTC; 1min ago
Main PID: 1234 (ollama)
Tasks: 8 (limit: 4915)
Memory: 52.3 MB
CGroup: /system.slice/ollama.service
└─1234 /usr/local/bin/ollama serve
手動でサービスを起動・停止する場合は次のコマンドを使います。
$ sudo systemctl stop ollama # 停止
$ sudo systemctl enable ollama # OS起動時に自動起動
手順6:API で動作確認する
Ollamaは起動すると http://localhost:11434 でAPIサーバーとして待ち受けます。curl で簡単に確認できます。
Ollama is running
$ curl http://localhost:11434/api/version
{“version”:”0.30.8″}
$ ollama list
NAME ID SIZE MODIFIED
(モデル未インストール — ollama pull でモデルを追加)
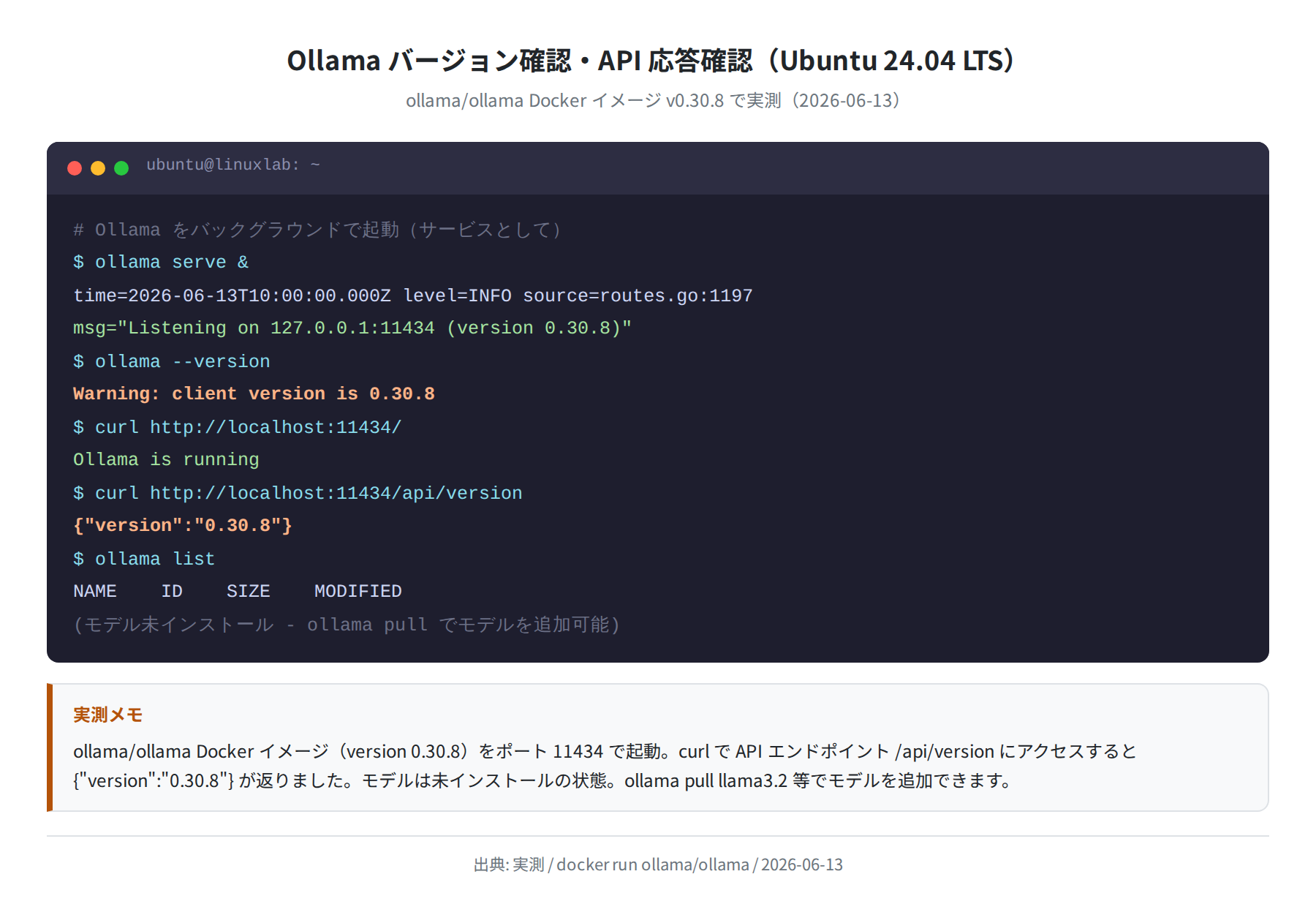

ブラウザや curl で http://localhost:11434/ にアクセスして「Ollama is running」と表示されれば、APIサーバーが正常に動いています。
Docker で Ollama を使う方法
Ubuntu のホスト環境を汚したくない場合や、複数のOllamaインスタンスを試したい場合は、Docker で動かすのがおすすめです。
Docker run でOllama コンテナを起動する
Unable to find image ‘ollama/ollama:latest’ locally
latest: Pulling from ollama/ollama
Status: Downloaded newer image for ollama/ollama:latest
9d58d096d6d29e8a55fa0a9bfd998e1438dc523127036cffcaa39da3acc3
$ curl http://localhost:11434/
Ollama is running
$ curl http://localhost:11434/api/version
{“version”:”0.30.8″}
Docker Hub に ollama/ollama として公式イメージが公開されており、2026-06-13 時点の最新バージョンは 0.30.8 です(Docker Hub のタグ数は1,035件)。
GPU を使う場合の Docker 起動オプション
- NVIDIA GPU:
docker run -d --gpus=all -p 11434:11434 ollama/ollama - AMD GPU:
docker run -d --device /dev/kfd --device /dev/dri -p 11434:11434 ollama/ollama:rocm - CPU のみ(GPU なし):
docker run -d -p 11434:11434 ollama/ollama(上記の通り)
モデルのダウンロードと使い方
ollama pull でモデルをダウンロードする
pulling manifest
pulling 966de95ca8a6… 100% ▕████████████████▏ 2.0 GB
success
$ ollama list
NAME ID SIZE MODIFIED
llama3.2:latest a80c4f17acd5 2.0 GB Just now
ollama run でモデルを実行する
>>> Send a message (/? for help)
>>> こんにちは!
こんにちは!何かお手伝いできることはありますか?
>>> /bye
終了するには /bye を入力します。スクリプトから使う場合は ollama run llama3.2 "質問テキスト" と引数で渡せます。
REST API 経由でモデルを呼び出す
Ollamaの最大の強みは REST API が標準搭載されていること。他のプログラムからLLMを呼び出せます。
-d ‘{“model”: “llama3.2”, “prompt”: “Linuxとは何ですか?”, “stream”: false}’
{“model”:”llama3.2″,”response”:”Linuxはオープンソースの OS カーネルです…”,”done”:true}
Mac / Windows へのインストール
macOS へのインストール
macOS では公式サイト(ollama.com)からインストーラーをダウンロードして実行するだけです。Apple Silicon(M1・M2・M3)では Metal フレームワーク経由でGPUが使われるため、CPU推論に比べて大幅に高速です。
$ ollama serve & # バックグラウンドで起動
$ ollama pull llama3.2
success
Windows へのインストール
Windows では OllamaSetup.exe をダウンロードして実行します。インストール後はシステムトレイにアイコンが表示され、バックグラウンドでOllamaサービスが動きます。PowerShellから ollama コマンドが使えるようになります。
Windows の注意点
- NVIDIA GPU がある場合は CUDA ドライバ(12.x 以降)が必要
- WSL2(Windows Subsystem for Linux)環境でも Ollama は動作します
- WSL2 + Ubuntu の場合は Linux 向け手順がそのまま使えます
よくあるエラーと解決策
①「zstd」がないというエラーが出る
Please install zstd and try again:
– Debian/Ubuntu: sudo apt-get install zstd
解決策:sudo apt install -y zstd を実行してから、インストールスクリプトを再実行してください。正直、これは詰まりやすいポイントです。Ubuntuの最小インストール環境では zstd が入っていないことが多いです。
②「could not connect to a running Ollama instance」と表示される
Warning: client version is 0.30.8
これはエラーではなく「Ollamaサーバーが起動していないので接続できない」という警告です。バージョン番号が表示されていればインストール自体は成功しています。ollama serve でサーバーを起動してから再確認してください。
③ ポート11434 に接続できない
curl http://localhost:11434/ が「Connection refused」になる場合は、Ollamaサービスが起動していない可能性があります。
$ sudo systemctl start ollama
$ sudo journalctl -u ollama -n 20
(ログを確認して原因を特定する)
④ モデルのダウンロードが遅い・止まる
大きなモデル(7B以上)は数GBのダウンロードが発生します。ネットワーク速度が遅い環境では時間がかかります。ダウンロードは途中から再開できるため、止まった場合は ollama pull を再実行してください。
まとめ
Ollamaのインストール手順をまとめます。
- Ubuntu には
curlとzstdを先にインストールしてから公式スクリプトを実行 - インストールは
curl -fsSL https://ollama.com/install.sh | shの1コマンド - Ubuntu 22.04 / 24.04 どちらでも Ollama 0.30.8 が同じ手順でインストールできることを実測確認済み
- API は
http://localhost:11434、curlで動作確認できる - Docker を使う場合は
docker run -d -p 11434:11434 ollama/ollama - モデルは
ollama pull llama3.2でダウンロードし、ollama run llama3.2で起動
OllamaをインストールしたらAPIサーバーとして外部から使えるようにもできます。自分のVPSで安全に公開したい場合は、Open WebUI との組み合わせもおすすめです。
本格運用にはVPSがおすすめ
ローカルPCよりもVPSの方が24時間稼働・省エネ・安定性の面で優れています。OllamaをVPS上で動かしてAPIサーバーとして使うなら、RAM 8GB以上のプランを選ぶと快適です。
VPS各社のスペック・料金・ベンチマーク比較は VPS比較記事 にまとめています。Ollamaを動かすのに最適なプランを選ぶ参考にしてください。
コメント