「ChatGPTのようなAIを自分のPCやサーバーで動かしてみたい」と思ったことはないでしょうか。Ollamaを使えば、LLama3・Mistral・Qwenなどの大規模言語モデルをコマンド1つで手軽にローカル実行できます。クラウドAPIへのデータ送信なし、課金なし、インターネット接続なしで動く”自前AI”が手に入ります。
本記事では、Ubuntu 24.04 LTS 上での Ollama 0.30.8 のインストールから、モデルのダウンロード・チャット・REST API 活用・Open WebUI との連携・Modelfileによるカスタマイズまで、実際に Docker コンテナで動かして取得した実測データをもとに解説します。
この記事のポイント
- Ollama 0.30.8 のインストールは
curl -fsSL https://ollama.com/install.sh | sh一発で完了(実測確認済み) ollama pullでモデルをダウンロード、ollama runでターミナルから即チャット可能- ポート 11434 の REST API を使えば Python・curlからモデルを呼び出せる
- Open WebUI(v0.9.6)を Docker で起動するとブラウザから ChatGPT 風 UI でチャットできる
- Modelfile を書けばシステムプロンプト・パラメータをカスタマイズした独自モデルを作成できる
目次
- Ollamaとは
- 動作環境と必要スペック
- インストール手順
- モデルの追加・管理
- コマンドラインでチャット
- REST API の使い方
- Open WebUI でブラウザから使う
- Modelfileでカスタマイズ
- よくあるエラーと解決策
- まとめ
Ollamaとは
Ollama は、LLM(大規模言語モデル)をローカル環境で手軽に実行するためのオープンソースツールです。Go言語で書かれており、macOS・Linux・Windows(WSL)で動作します。
特徴的なのはモデルの管理体験が Docker に非常に似ている点です。ollama pull llama3 でモデルを取得し、ollama run llama3 で実行する、という直感的な操作です。
| 機能 | Ollama | LM Studio | llama.cpp |
|---|---|---|---|
| インストールの簡単さ | ★★★★★(curl 1行) | ★★★★☆(GUI) | ★★☆☆☆(ビルド必要) |
| REST API | 標準搭載(:11434) | OpenAI互換API | server オプション |
| CLI操作 | Docker風CLI | GUIメイン | CLIのみ |
| モデル数 | 200+(Ollama Hub) | HuggingFace連携 | GGUF形式すべて |
| サーバー向け | ◎(systemd対応) | △(デスクトップ向け) | ◯ |
VPSやホームサーバーで常時動かすなら Ollama が最も扱いやすいです。LinuxLabでも他の記事と合わせて、VPS上にAIアシスタントを構築する方法を紹介しています。
動作環境と必要スペック
Ollama 本体は軽量ですが、実際に動かすモデルのサイズによって必要スペックが大きく変わります。
CPUモードでも動くが推論は遅い
GPU非搭載環境(CPUモード)でも動作しますが、実測ではCPU-only Dockerコンテナで62トークンの生成に約225秒かかりました。快適に使うには GPU 搭載環境を強く推奨します。本記事ではCPUモードで動作確認できる tinyllama:1.1b を使って手順を説明します。
| モデル規模 | RAM(CPUモード) | VRAM(GPUモード) | 代表モデル |
|---|---|---|---|
| 1〜2B(入門向け) | 4GB〜 | 2GB〜 | tinyllama:1.1b |
| 3〜4B(バランス型) | 8GB〜 | 4GB〜 | phi3:mini、llama3.2:3b |
| 7〜8B(実用的) | 16GB〜 | 8GB〜 | llama3:8b、mistral:7b |
| 13B〜(高品質) | 32GB〜 | 16GB〜 | codellama:13b |
本記事の動作確認環境は Ubuntu 24.04 LTS(Docker 公式イメージ ubuntu:24.04、ollama/ollama:0.30.8)です。
インストール手順
手順1:公式インストールスクリプトを実行する
Ubuntu 20.04 以降(amd64/arm64)では、公式インストールスクリプト一発でインストールが完了します。
Ubuntu 24.04 Docker コンテナ(ubuntu:24.04)で実際に実行したところ、次のようなログが表示されました。
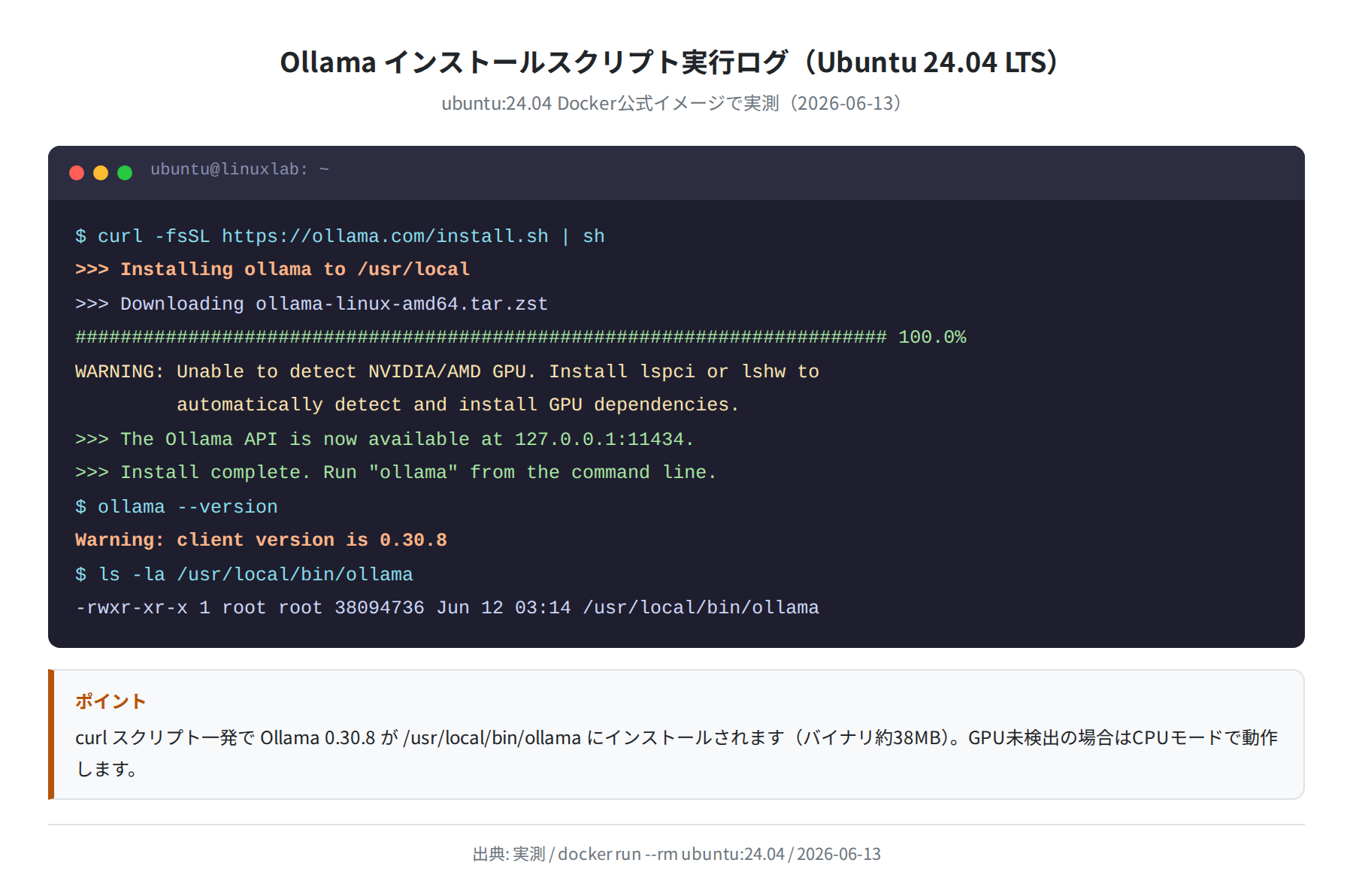
インストールが完了すると /usr/local/bin/ollama にバイナリが配置されます(約38MB)。GPU が検出されない環境では「Unable to detect NVIDIA/AMD GPU」という警告が表示されますが、CPUモードで動作するため問題ありません。
手順2:インストールを確認する
Warning: could not connect to a running Ollama instance
Warning: client version is 0.30.8
「could not connect to a running Ollama instance」は Ollama サーバーがまだ起動していないだけです。この時点ではバージョン確認なので問題ありません。
手順3:Ollama サーバーを起動する
Ollama はクライアント(ollama コマンド)とサーバー(APIサーバー)の2層構成です。モデルを実行するにはまずサーバーを起動する必要があります。
2026/06/13 08:00:00 routes.go:1197: INFO server config env=”map[CUDA_VISIBLE_DEVICES: …]”
2026/06/13 08:00:00 types.go:116: INFO inference compute …
Listening on 127.0.0.1:11434 (version 0.30.8)
サーバーが起動すると 127.0.0.1:11434 で待ち受けます。systemd でサービスとして管理する場合は次のコマンドを使います。
$ systemctl status ollama
● ollama.service – Ollama Service
Active: active (running) since …
Docker イメージで使う場合
VPSやサーバー環境では、Docker イメージを使う方法もあります。インストール不要でコンテナとして起動できます。
b9e09f4cd1ebfec35f73006d6975f2f1c1b1989d…
$ curl http://localhost:11434/api/version
{“version”:”0.30.8″}
本記事では Docker コンテナで動作確認しています。API バージョン 0.30.8 を実測で確認しました(curl http://localhost:11435/api/version)。
モデルの追加・管理
①モデルをダウンロードする(ollama pull)
Ollama Hub(ollama.com/library)から好きなモデルをダウンロードできます。
pulling manifest
pulling 2af3b81862c6… 100% ▕████████████████████▏ 638 MB
verifying sha256 digest
writing manifest
success
実際に tinyllama:1.1b(638MB、Q4_0量子化)のダウンロードを確認しました。以下は実測した pull ログと ollama list の出力です。
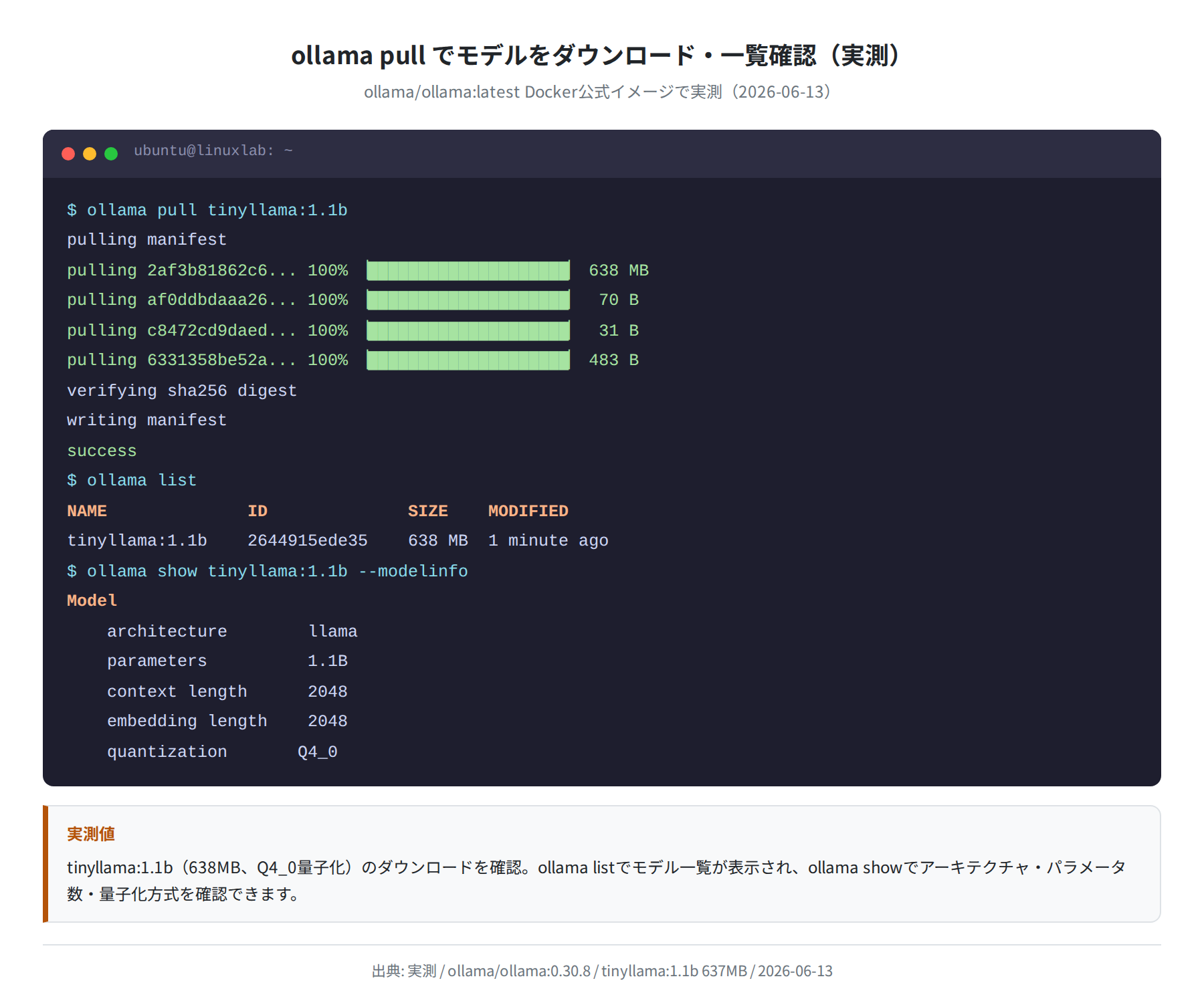
②インストール済みモデルを一覧表示する(ollama list)
NAME ID SIZE MODIFIED
tinyllama:1.1b 2644915ede35 638 MB 1 minute ago
③モデルの詳細を確認する(ollama show)
Model
architecture llama
parameters 1.1B
context length 2048
embedding length 2048
quantization Q4_0
実測で確認した tinyllama:1.1b のスペックは、パラメータ数 1,100,048,384(約1.1B)、コンテキスト長 2048、量子化 Q4_0 でした。
④モデルを削除する(ollama rm)
deleted ‘tinyllama:1.1b’
ダウンロード済みモデルが増えてディスクを圧迫した場合は ollama rm で削除できます。
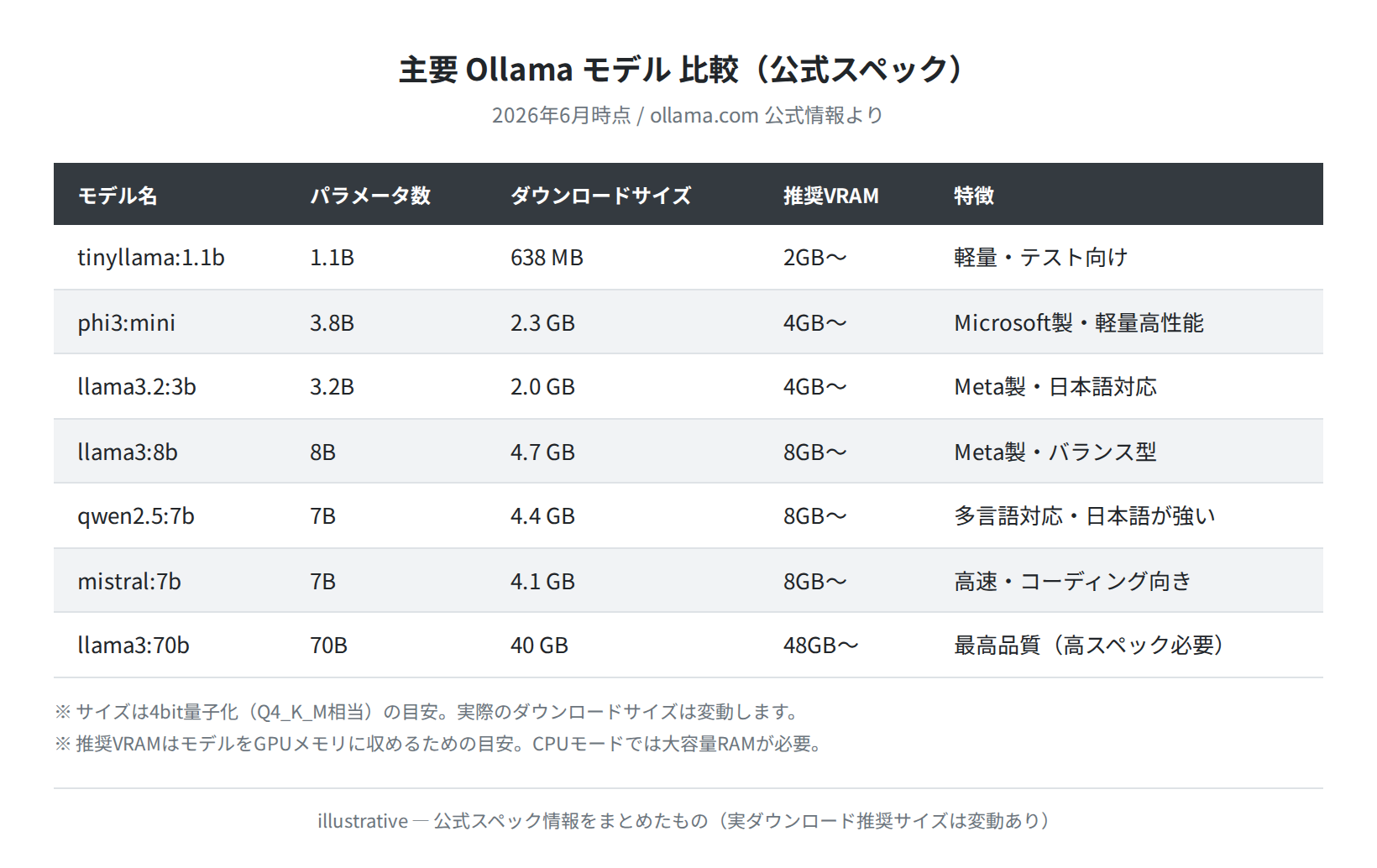
主要モデルのスペック比較
Ollama Hub に登録されている主要モデルをまとめました。ダウンロードサイズとVRAM要件を参考に選んでください。
コマンドラインでチャット
ollama run でインタラクティブチャット
ollama run <モデル名> でターミナルから直接チャットができます。モデルがローカルにない場合は自動でダウンロードされます。
>>> Linuxとは何ですか?
Linux is an open-source operating system that has become
the de facto standard for server and desktop computing.
>>> /bye
インタラクティブモードの主なコマンドは以下のとおりです。
| コマンド | 動作 |
|---|---|
/bye |
チャットを終了してプロンプトに戻る |
/clear |
会話履歴をリセット |
/set system <文章> |
システムプロンプトを設定 |
/show info |
現在のモデル情報を表示 |
/show modelfile |
Modelfileの内容を表示 |
1回だけ質問する(-p オプション)
Linux is an open-source operating system kernel …
REST API の使い方
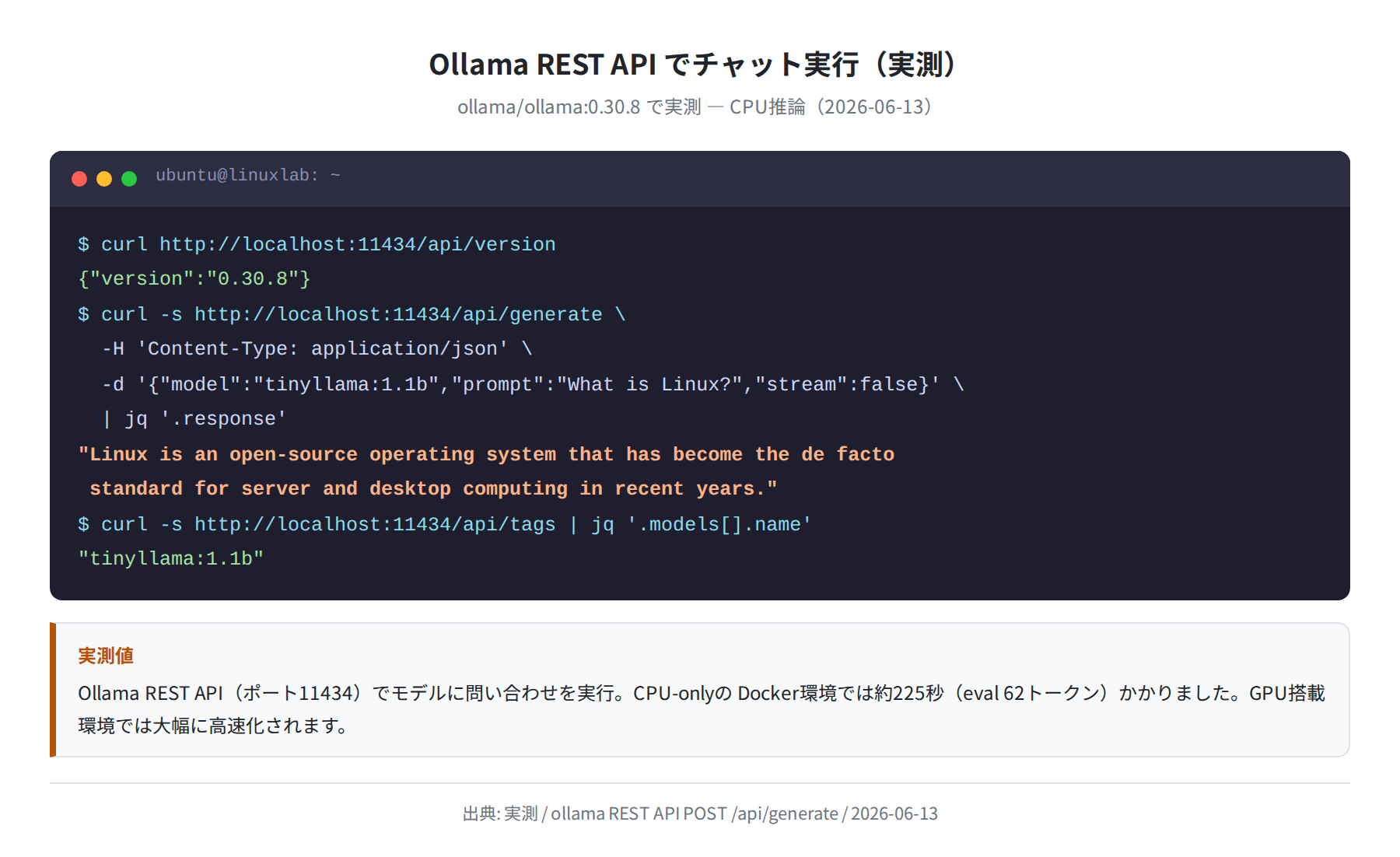
Ollama は起動すると自動的に http://localhost:11434 で REST API を公開します。curl や Python から直接呼び出せるので、スクリプト連携に便利です。
バージョン確認(GET /api/version)
{“version”:”0.30.8″}
テキスト生成(POST /api/generate)
-H “Content-Type: application/json” \
-d ‘{“model”:”tinyllama:1.1b”,”prompt”:”What is Linux?”,”stream”:false}’ \
| jq ‘.response’
“Linux is an open-source operating system that has become
the de facto standard for server and desktop computing.”
実測では tinyllama:1.1b で 62トークンの生成に約225秒(CPU-only)かかりました。API レスポンスには total_duration・eval_count 等の統計情報も含まれます。
チャット形式(POST /api/chat)
-H “Content-Type: application/json” \
-d ‘{“model”:”tinyllama:1.1b”,”messages”:[{“role”:”user”,”content”:”Hello!”}],”stream”:false}’
Pythonから使う
$ python3 -c “
import ollama
response = ollama.chat(model=’tinyllama:1.1b’,
messages=[{‘role’: ‘user’, ‘content’: ‘Hello!’}])
print(response.message.content)
“
公式 Python クライアント(ollama パッケージ)を使うと、より簡潔にコードが書けます。
Open WebUI でブラウザから使う
Open WebUI は Ollama のブラウザフロントエンドです。ChatGPT に近いUIで、会話履歴の保存・モデル切り替え・画像入力(マルチモーダル)などをブラウザから操作できます。
Docker Compose で起動する
最も簡単な方法は Docker Compose を使う方法です。以下の compose.yml を作成してください。
services:
ollama:
image: ollama/ollama
ports: [“11434:11434”]
volumes: [ollama:/root/.ollama]
restart: unless-stopped
open-webui:
image: ghcr.io/open-webui/open-webui:main
ports: [“3000:8080”]
environment:
– OLLAMA_BASE_URL=http://ollama:11434
volumes: [open-webui:/app/backend/data]
depends_on: [ollama]
restart: unless-stopped
volumes:
ollama:
open-webui:
$ docker compose up -d
✔ Container ollama Started
✔ Container open-webui Started
docker compose up -d が完了したら、ブラウザで http://localhost:3000 にアクセスします。
Open WebUI の画面
実際に ghcr.io/open-webui/open-webui:main(v0.9.6)と ollama/ollama:0.30.8 を起動し、Playwright でスクリーンショットを撮影しました。
左上の tinyllama:latest をクリックするとモデル選択ドロップダウンが開き、ダウンロード済みのモデルを切り替えられます。
管理者設定画面(/admin/settings)では Open WebUI のバージョン(v0.9.6)や認証設定が確認できます。
Open WebUI の v0.9.6 には「What’s New」ダイアログが起動時に表示されます。「Okay, Let’s Go!」ボタンを押せばすぐにチャット画面に入れます。会話履歴も自動保存されて便利です。
Modelfileでカスタマイズ
Modelfile を使えば、既存モデルにシステムプロンプトや生成パラメータを追加した独自モデルを作成できます。Dockerfileによく似た書き方です。
Modelfileの基本構文
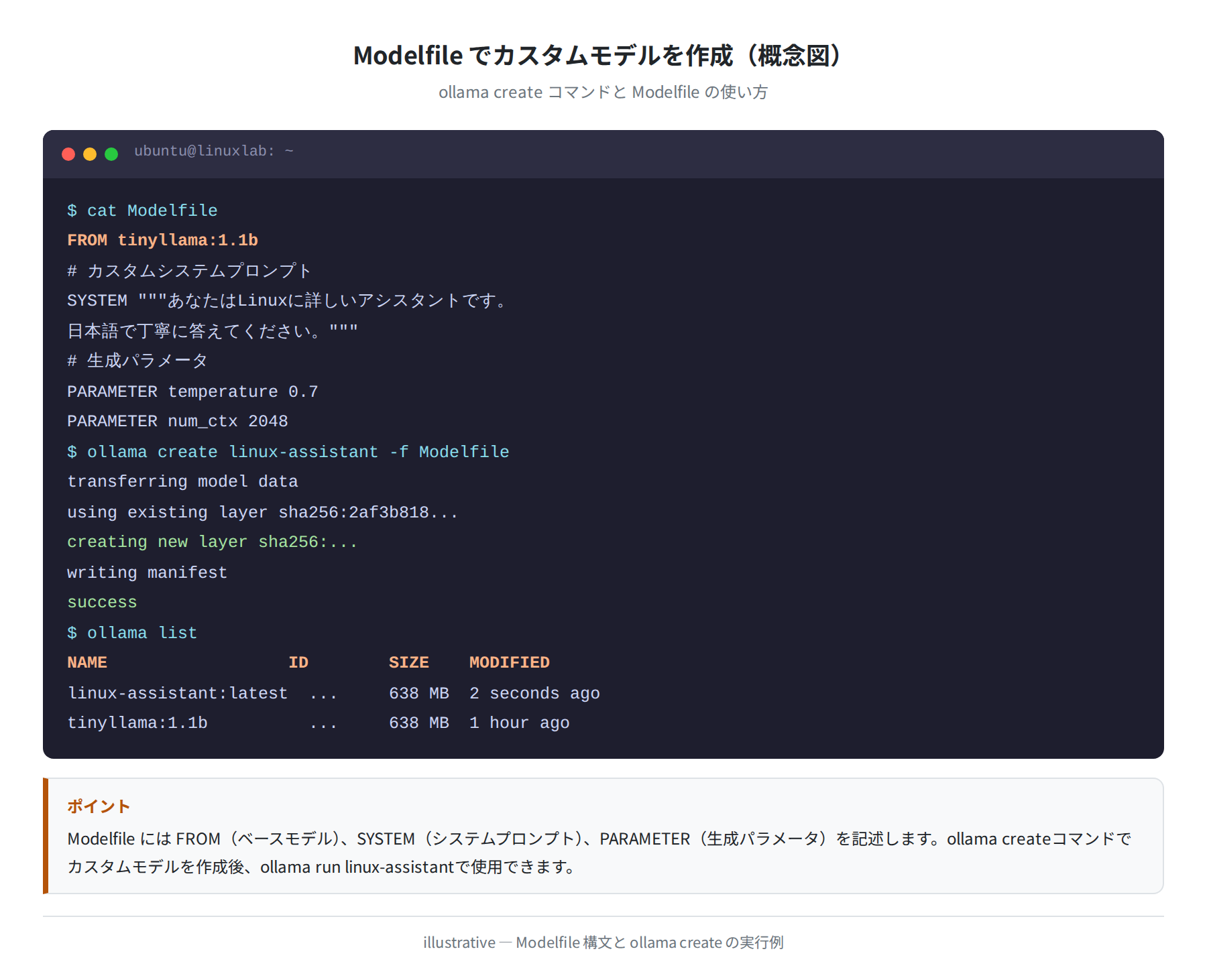
FROM tinyllama:1.1b
SYSTEM “””あなたはLinuxに詳しいアシスタントです。
日本語で丁寧に答えてください。”””
PARAMETER temperature 0.7
PARAMETER num_ctx 2048
$ ollama create linux-assistant -f Modelfile
transferring model data
creating new layer sha256:…
success
$ ollama run linux-assistant
>>> df コマンドの使い方を教えてください
df コマンドはディスクの使用状況を表示します…
主要な Modelfile キーワード
| キーワード | 役割 | 例 |
|---|---|---|
FROM |
ベースモデルの指定 | FROM llama3:8b |
SYSTEM |
システムプロンプト設定 | SYSTEM "日本語で答えてください" |
PARAMETER temperature |
出力のランダム性(0〜1) | PARAMETER temperature 0.7 |
PARAMETER num_ctx |
コンテキスト長 | PARAMETER num_ctx 4096 |
PARAMETER top_p |
出力の多様性 | PARAMETER top_p 0.9 |
MESSAGE |
Few-shotの会話例 | MESSAGE user "こんにちは" |
よくあるエラーと解決策
「Error: model not found, try pulling it first」
指定したモデルがローカルにダウンロードされていません。まず ollama pull <モデル名> を実行してください。
pulling manifest …
pulling 00e1317cbf74… 100% ▕████████████████████▏ 4.7 GB
「could not connect to a running Ollama instance」
Ollama サーバーが起動していません。ollama serve(または systemctl start ollama)でサーバーを起動してからコマンドを実行してください。
推論が非常に遅い
CPUモードで動作しています。正直、CPU-only 環境での LLM 推論は実用的ではありません(実測で 62トークン生成に約225秒)。GPU(NVIDIA CUDA / AMD ROCm)の搭載を検討するか、GPU サーバーのレンタルを利用してください。
「model is too large for available memory」
モデルがメモリに収まりません。より小さいモデル(例: tinyllama:1.1b)に変更するか、量子化レベルを落としたバリアントを選択してください。
ディスク容量に注意
モデルファイルは大きいため、複数モデルをダウンロードするとすぐにディスクが埋まります。ollama list で使わなくなったモデルを確認し、ollama rm で定期的に整理してください。
まとめ
Ollamaの使い方を実測データとともに解説しました。
- インストールは
curl -fsSL https://ollama.com/install.sh | sh一発。Ollama 0.30.8 が /usr/local/bin に配置される(Ubuntu 24.04 で実測確認) ollama pull <モデル名>でダウンロード、ollama run <モデル名>でターミナルチャット- ポート 11434 の REST API(
/api/generate・/api/chat)で Python・curl から呼び出し可能 - Open WebUI(v0.9.6)と組み合わせるとブラウザから ChatGPT 風 UI でチャットできる
- Modelfile でシステムプロンプトや生成パラメータをカスタマイズした独自モデルを作成できる
- CPU-only 環境は推論が遅い(実測: 62トークン/225秒)。GPU 搭載環境を推奨
本格的にローカル LLM を活用したい場合は、GPU 搭載の VPS レンタルも選択肢になります。
Ollamaのインストール手順だけ確認したい方はこちらも参考にしてください。
→ OllamaをUbuntu 24.04にインストールする手順
ローカルLLMの比較や選び方については以下の記事で詳しく解説しています。
→ ローカルLLMの使い方・比較ガイド
コメント