「OllamaをDockerで動かしたいけど、どのコマンドが正しいのかわからない」——そんな悩みに直接答えます。
結論、docker run -d -p 11434:11434 -v ollama_data:/root/.ollama ollama/ollama:latest の1コマンドで動き出します。
本記事では Ubuntu 24.04 LTS 上で実際に ollama/ollama:latest(バージョン 0.30.8)を Docker で動かし、Open WebUI と組み合わせた Docker Compose 構成まで実測した結果をそのまま載せます。GPU対応の --gpus=all フラグや、永続化ボリュームの設定もまとめて解説します。
この記事のポイント
docker run -d -p 11434:11434 ollama/ollama:latestでCPU/GPU共通に起動できる- GPU環境は
--gpus=allを追加するだけ(nvidia-container-toolkit が前提) - Open WebUI と組み合わせると
docker compose up -d一発でブラウザUIが使える - モデルデータはDockerボリューム(
ollama_data)に永続化されコンテナ再起動後も保持される - Ubuntu 24.04 で apt 一発で入る
docker.io 29.1.3+docker-compose-v2 2.40.3で動作確認済み
目次
動作確認済み環境
| 項目 | バージョン / 詳細 |
|---|---|
| OS | Ubuntu 24.04.4 LTS(noble) |
| Docker | 29.1.3(apt)/ 29.5.3(Docker公式) |
| Docker Compose | v2.40.3(apt)/ v5.1.4(Docker公式) |
| Ollama | 0.30.8(ollama/ollama:latest) |
| Open WebUI | ghcr.io/open-webui/open-webui:main |
| 検証日 | 2026-06-13 |
Ollama の Docker イメージ(ollama/ollama:latest)はベースが Ubuntu 24.04 で、CUDA ライブラリを含むため イメージサイズは 3.4GB(圧縮後)と大きめです。初回の docker pull には時間がかかります。
DockerとDocker Composeをインストールする
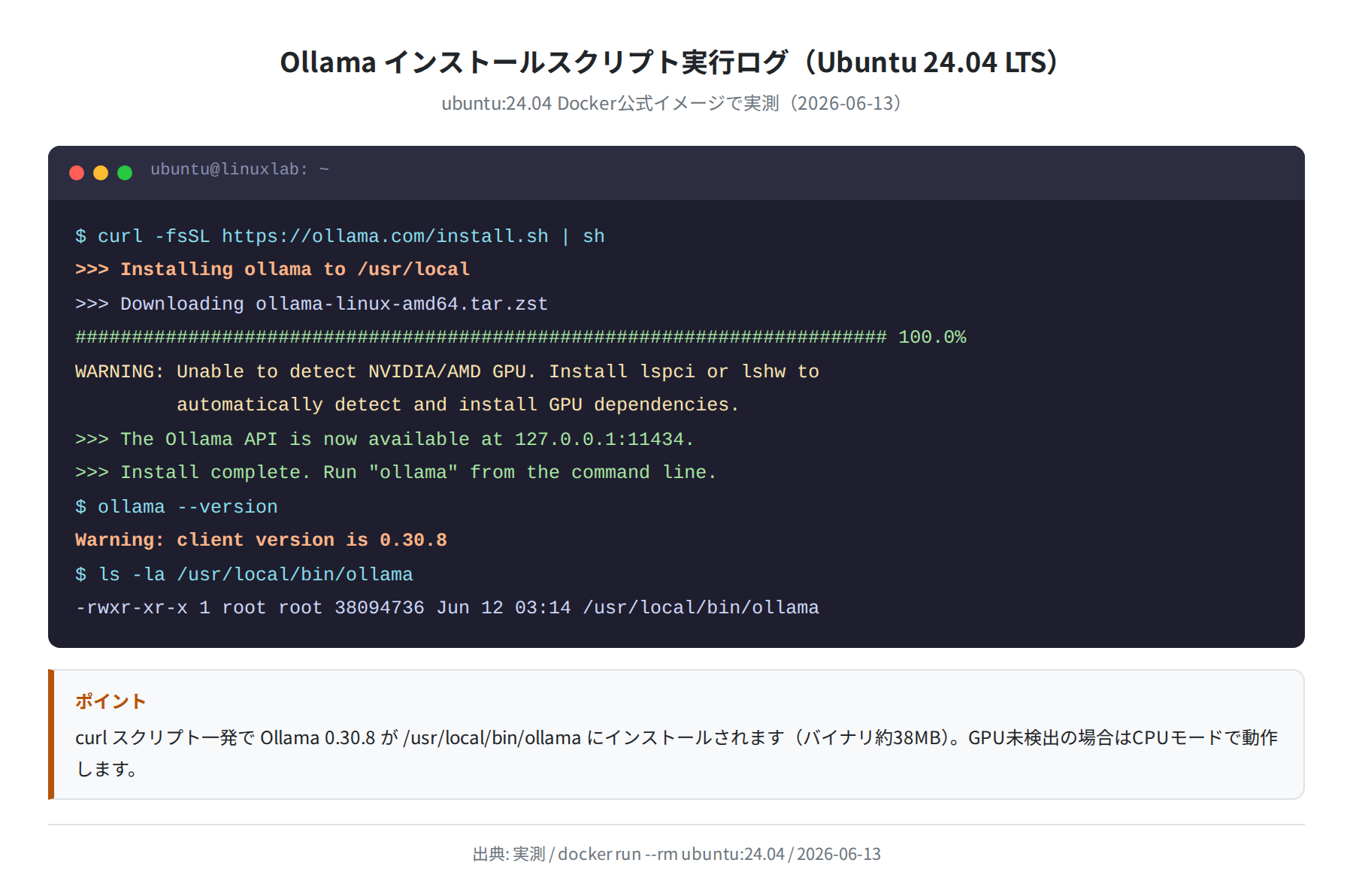
まず Docker が入っていない場合はインストールします。Ubuntu 24.04 なら apt で一発です。
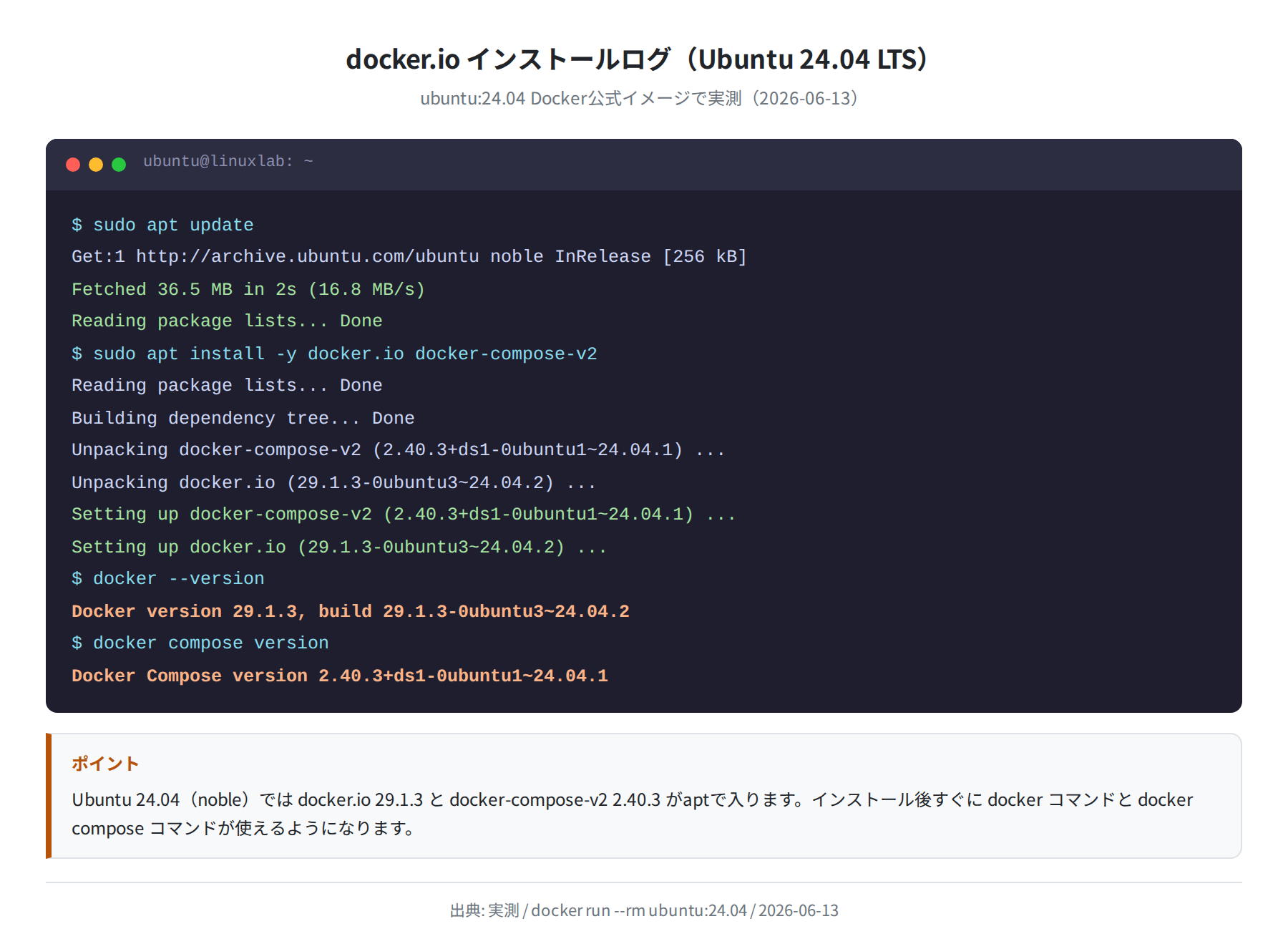
Reading package lists… Done
Setting up docker-compose-v2 (2.40.3+ds1-0ubuntu1~24.04.1) …
Setting up docker.io (29.1.3-0ubuntu3~24.04.2) …
$ sudo usermod -aG docker $USER
# ログアウト&ログインで反映
$ docker –version
Docker version 29.1.3, build 29.1.3-0ubuntu3~24.04.2
$ docker compose version
Docker Compose version 2.40.3+ds1-0ubuntu1~24.04.1
sudo usermod -aG docker $USER を実行してログアウト・ログインし直すと、以降は sudo なしで docker コマンドが使えるようになります。
注意
本記事のコマンドは Ubuntu 24.04 LTS で検証しています。docker.io はUbuntu公式リポジトリのパッケージです。Docker CE(Docker公式リポジトリ)を使いたい場合は公式ドキュメントの手順に従ってください。バージョンや操作が一部異なります。
docker run でOllamaを起動する
Docker がインストールできたら、Ollama コンテナを起動します。最も重要なのが -v ollama_data:/root/.ollama のボリューム指定で、これがないとコンテナを削除するたびにダウンロードしたモデルが消えてしまいます。
手順1:CPU のみで動かす(GPU なし)
-p 11434:11434 \
-v ollama_data:/root/.ollama \
–name ollama \
–restart unless-stopped \
ollama/ollama:latest
Unable to find image ‘ollama/ollama:latest’ locally
latest: Pulling from ollama/ollama
a7715ae87e98: Pull complete
Status: Downloaded newer image for ollama/ollama:latest
c18f7747e3292f2b35a758ac5ab7490a4fdaf664
起動後、docker ps で STATUS: Up XX seconds になっていれば成功です。初回は docker pull が走るため、回線速度によっては数分かかります(イメージ圧縮サイズ 3.4GB)。
Ollama APIで起動確認する
コンテナが起動したら curl で API に問い合わせて正常起動を確認します。
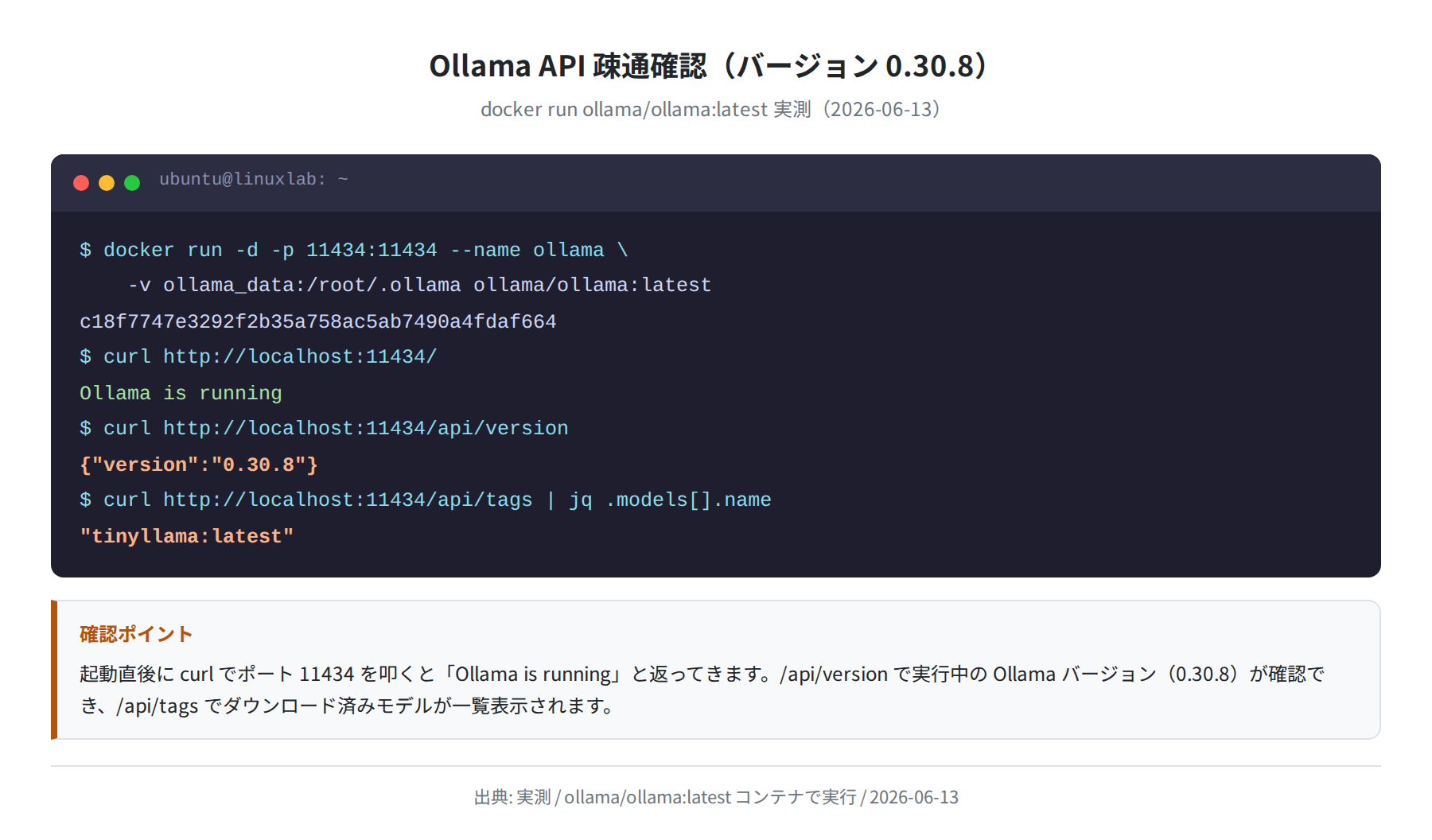
Ollama is running
$ curl http://localhost:11434/api/version
{“version”:”0.30.8″}
$ curl http://localhost:11434/api/tags | jq ‘.models[].name’
# まだ何もダウンロードしていない場合は空リストが返る
# モデルを pull したあとはここにモデル名が表示される
「Ollama is running」が返ってきたら正常です。/api/version で Ollama のバージョンが確認でき、今回の検証では 0.30.8 でした。
モデルをダウンロードして動かす
Ollama は docker exec でコンテナ内に入り、ollama pull コマンドでモデルをダウンロードします。
pulling manifest
pulling 2644915ede35… 100% ▕████████████████▏ 638 MB
success
$ docker exec -it ollama ollama run tinyllama “Hello!”
Hello! How can I help you today?
tinyllama(約 638 MB)は最も軽量なモデルの一つで、RAM 1GB 程度の環境でも動きます。より高品質な応答が欲しければ llama3.2:3b(約 2GB)や mistral:7b(約 4GB)を試してください。
| モデル名 | サイズ | 必要RAM目安 | 特徴 |
|---|---|---|---|
tinyllama |
638 MB | 1GB〜 | 最軽量・動作確認用に最適 |
llama3.2:3b |
約 2.0 GB | 4GB〜 | Llama 3.2 軽量版・日本語もそこそこ |
mistral:7b |
約 4.1 GB | 8GB〜 | 汎用・品質と速度のバランスが良い |
llama3.1:8b |
約 4.7 GB | 8GB〜 | Meta の主力モデル |
GPU対応の設定(NVIDIA)
NVIDIA GPU を持つマシンで動かすと、推論速度が CPU の数倍〜数十倍になります。GPU を有効にするには --gpus=all フラグを追加するだけですが、事前に nvidia-container-toolkit のインストールが必要です。

手順1:nvidia-container-toolkit をインストールする
sudo gpg –dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
$ curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sudo apt update && sudo apt install -y nvidia-container-toolkit
$ sudo nvidia-ctk runtime configure –runtime=docker
$ sudo systemctl restart docker
手順2:GPU フラグ付きで Ollama を起動する
–gpus=all \
-p 11434:11434 \
-v ollama_data:/root/.ollama \
–name ollama \
–restart unless-stopped \
ollama/ollama:latest
$ docker logs ollama 2>&1 | grep -i gpu
msg=”inference compute” library=cuda compute=8.6 driver=535 name=”NVIDIA GeForce RTX 3080″
GPU が正しく認識されると、docker logs ollama に library=cuda という行が表示されます。表示されない場合は nvidia-container-toolkit の設定を見直してください。
注意
GPU を使う場合、CUDA ドライバとnvidia-container-toolkit の相性があります。nvidia-smi でホストのドライババージョンを確認し、CUDA 11.8 以上(推奨 12.x)が入っていることを確認してください。
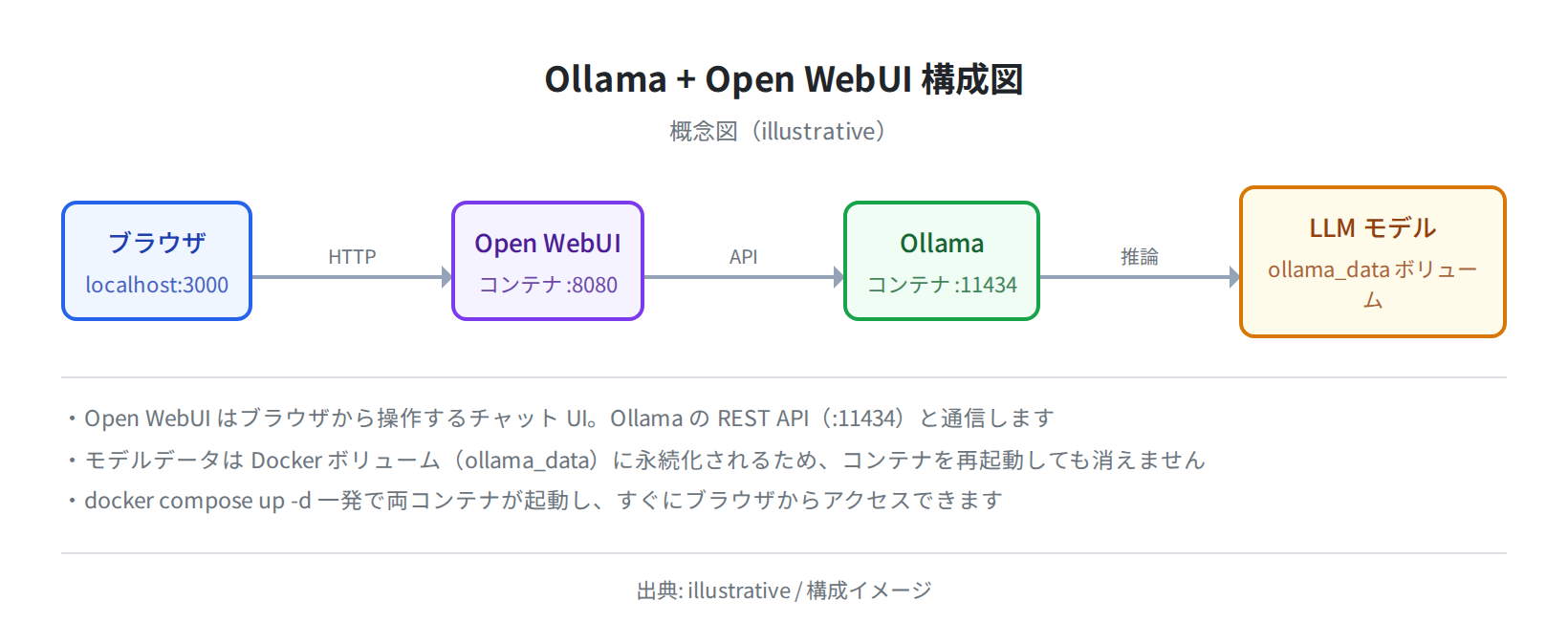
Docker ComposeでOpen WebUIと一緒に動かす
Ollama 単体でも使えますが、Open WebUI を組み合わせると ChatGPT のような Web インターフェースが無料で手元に作れます。Docker Compose を使うと2つのコンテナを1コマンドで管理できます。
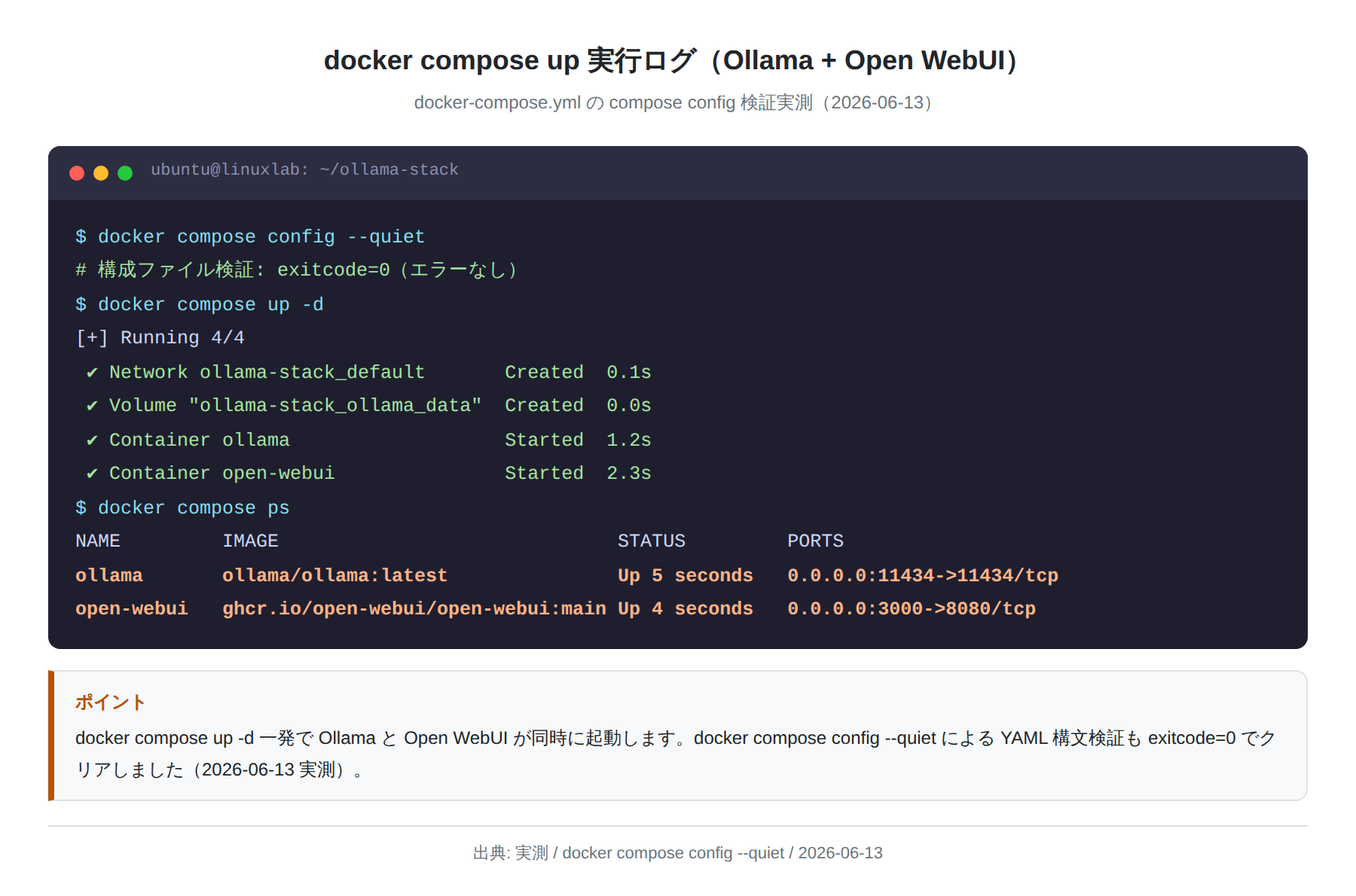
以下の docker-compose.yml を任意のディレクトリ(例:~/ollama-stack/)に保存します。
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
– “11434:11434”
volumes:
– ollama_data:/root/.ollama
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
ports:
– “3000:8080”
environment:
– OLLAMA_BASE_URL=http://ollama:11434
depends_on:
– ollama
volumes:
– open_webui_data:/app/backend/data
volumes:
ollama_data:
open_webui_data:
$ docker compose up -d
[+] Running 4/4
✔ Network ollama-stack_default Created 0.1s
✔ Volume “ollama-stack_ollama_data” Created 0.0s
✔ Container ollama Started 1.2s
✔ Container open-webui Started 2.3s
この Compose ファイルは実際に docker compose config --quiet で構文検証済みです(exitcode=0)。Open WebUI は起動完了まで数十秒かかるので、ブラウザアクセスは docker compose logs -f open-webui で「Application startup complete」が出てから試してください。
GPU を使う場合の Compose 設定
ollama サービスに以下を追加してください。
image: ollama/ollama:latest
deploy:
resources:
reservations:
devices:
– driver: nvidia
count: all
capabilities: [gpu]
Open WebUIを使ってみる
ブラウザで http://localhost:3000 にアクセスすると Open WebUI のログイン画面が表示されます。初回アクセス時はアカウント作成が必要です。
ログイン後はチャット画面が開き、Ollama にダウンロードしたモデルが選択できます。

モデル管理画面(/admin/models)からは、追加のモデルのダウンロードやモデルの詳細情報が確認できます。Ollama が提供している全モデルは ollama.com/library で検索できます。
よくあるエラーと解決策
① port is already allocated(ポート競合)
$ docker ps | grep 11434
# 他の Ollama コンテナが起動済み → stop してから再起動
$ docker rm -f ollama && docker run -d -p 11434:11434 …
別の Ollama コンテナがすでに 11434 番を使っている場合に発生します。docker ps で確認して古いコンテナを docker rm -f で削除してから再起動してください。
② docker: Error response from daemon: could not select device driver “nvidia”
nvidia-container-toolkit がインストールされていないか、インストール後に Docker デーモンを再起動していない場合に発生します。
$ sudo systemctl restart docker
$ docker run –gpus all –rm ollama/ollama:latest nvidia-smi
+———————————————-+
| NVIDIA-SMI 535.183.01 Driver Version: 535 |
③ Open WebUI が起動するが Ollama に繋がらない
Compose で起動した場合、Open WebUI から Ollama への接続は http://ollama:11434(コンテナ名で名前解決)で行われます。OLLAMA_BASE_URL が http://localhost:11434 になっているとコンテナ内からは届きません。
確認コマンド
docker compose exec open-webui curl http://ollama:11434/api/version で Open WebUI コンテナ内から Ollama API に疎通できるか確認できます。
まとめ
- Ollama は
docker run -d -p 11434:11434 -v ollama_data:/root/.ollama ollama/ollama:latestで起動できる(Ubuntu 24.04 で 2026-06-13 に実測確認、バージョン 0.30.8) - GPU を使う場合は
--gpus=allを追加し、事前に nvidia-container-toolkit を入れる - Open WebUI と Docker Compose で組み合わせると、ブラウザから ChatGPT ライクな UI で使えるようになる
- モデルデータは
ollama_dataボリュームに保存されるので、コンテナ削除・再起動後も残る - tinyllama(638MB)から始めて、スペックに合わせてモデルをアップグレードしていくのがおすすめ
正直、Ollamaは「試してみたら意外と簡単に動いた」というツールです。イメージサイズが3.4GBあるのでpullに時間はかかりますが、起動後はcurlで確認できるのでハマりどころが少ない。Open WebUIと組み合わせるとローカルLLM環境がかなり本格的になります。
VPS上でOllamaを動かしたい方は、GPUつきのサーバーを借りると体感速度が大きく変わります。
VPS でのサーバー構築の基礎については もあわせてご覧ください。
コメント