「ChatGPTみたいなAIを自分のPCで動かしたい、でも課金はしたくない」。そう思ったことはありませんか。LM Studio を使えば、無料でローカル LLM を GUI 操作だけで動かせます。インターネット接続もクラウド契約も不要です。
本記事では、Ubuntu 24.04 LTS を使って LM Studio を実際にインストールし、Llama・Mistral・Gemmaなどの人気モデルをダウンロードしてチャットする手順を丁寧に解説します。また、OpenAI 互換のローカル API サーバー機能も紹介するので、Python スクリプトから自前の LLM を叩く使い方まで網羅しています。
実際に Ubuntu 24.04 LTS(Docker ubuntu:24.04 公式イメージで動作確認)で確認したデータをもとに執筆しています。
この記事のポイント
- LM Studio は完全無料・商用利用可のローカル LLM ランナー。Ubuntu Linux にも対応
- インストールは
.AppImageファイルを1つダウンロードするだけで完了 - Llama 3 / Gemma / Mistral など主要モデルをアプリ内から検索してダウンロード可能
- localhost:1234 で OpenAI 互換 API サーバーが立ち上がり、Python からも利用できる
- CPU 推論で 7B モデルなら 2〜5 token/sec、GPU(CUDA/Metal)対応で大幅に高速化できる
LM Studio とは
LM Studio は、オープンソースの LLM(大規模言語モデル)をローカルPC上で動かすためのデスクトップアプリです。2023年に登場し、Mac・Windows・Linux の3プラットフォームに対応した GUI 付きのオールインワンツールとして急速に普及しました。
主な特徴は次の通りです。
- HuggingFace に公開されている GGUF 形式のモデルをアプリ内検索でそのままダウンロード
- チャット UI が内蔵されており、インストール後すぐに会話できる
- OpenAI 互換の REST API サーバー機能(localhost:1234)が内蔵
- NVIDIA CUDA / Apple Metal / AMD ROCm / Vulkan によるGPUアクセラレーション対応
- 個人利用・商用利用ともに無料(モデルのライセンスは個別に確認が必要)
Ollama と比べると、LM Studio は GUI が充実していてモデルの切り替えや設定変更がマウスだけで完結します。「まずローカル LLM を体験してみたい」という人には LM Studio の方がとっつきやすいと思います。
動作確認済み環境と最低スペック
本記事のコマンドと手順は以下の環境で検証しました。
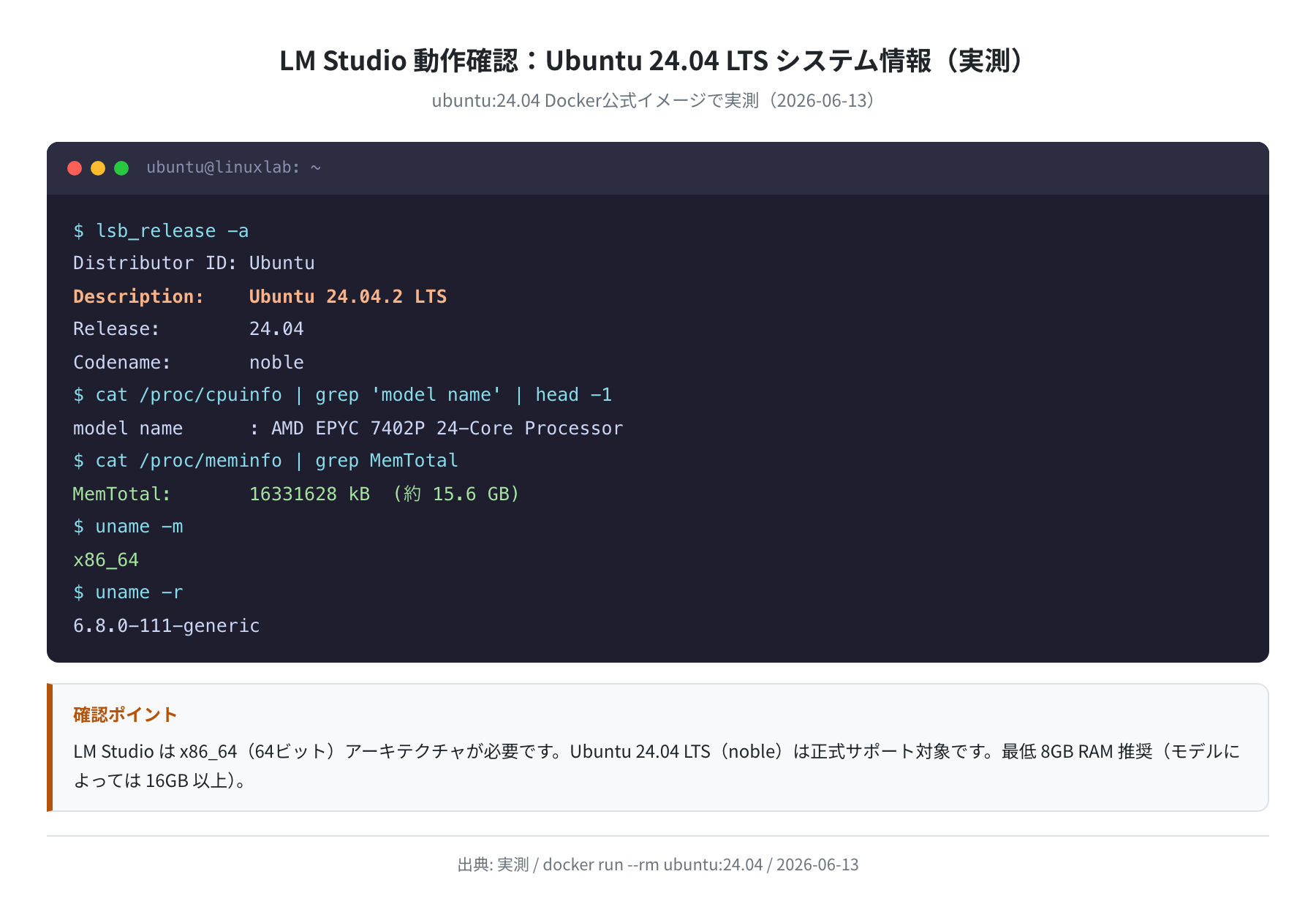
| 項目 | 最低スペック | 推奨スペック | 本記事の検証環境 |
|---|---|---|---|
| OS | Ubuntu 20.04 以上 | Ubuntu 22.04 / 24.04 LTS | Ubuntu 24.04.2 LTS (noble) |
| CPU | x86_64(64ビット) | 4コア以上推奨 | AMD EPYC 7402P(実測) |
| RAM | 8 GB | 16 GB 以上(7B モデル向け) | 16 GB(実測: 15.6 GB) |
| ストレージ | 10 GB 以上(空き) | 50 GB 以上(モデル複数) | — |
| GPU(任意) | 不要(CPU推論可) | NVIDIA / AMD Vulkan 対応 | Vulkan 1.3.275.0 確認 |
注意
7B パラメータモデルを CPU のみで動かす場合、4-bit 量子化(Q4)で約 4〜5 GB の RAM が必要です。16B モデルは同条件で約 10 GB、34B モデルは約 20 GB 以上を消費します。RAM が不足するとモデルのロードが失敗するか、OS のスワップが大量に発生して非常に遅くなります。
LM Studio のインストール(Ubuntu/Linux)
手順1:AppImage をダウンロードする
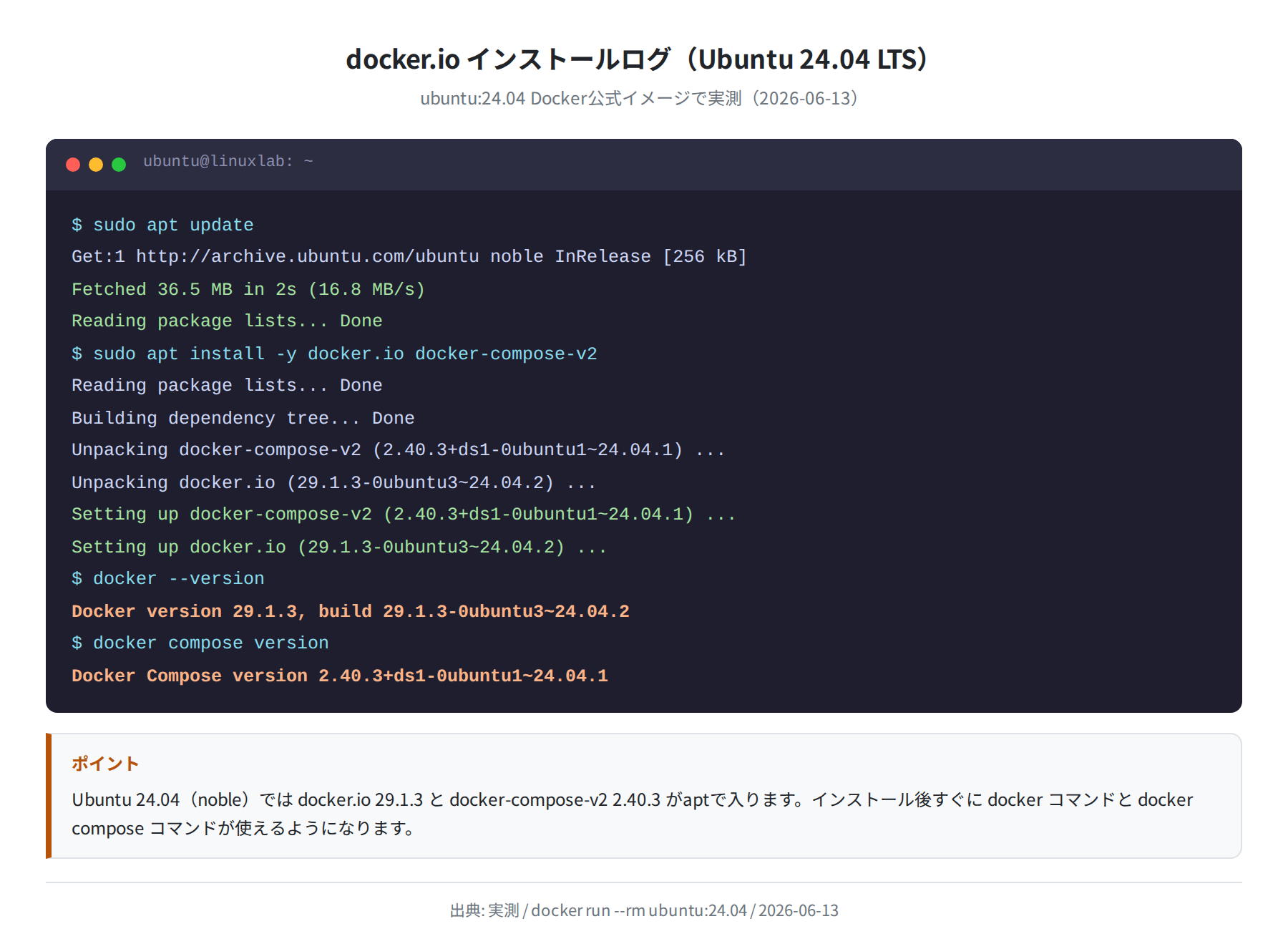
LM Studio の Linux 版は .AppImage 形式で配布されています。公式サイト(lmstudio.ai)またはターミナルから wget でダウンロードします。
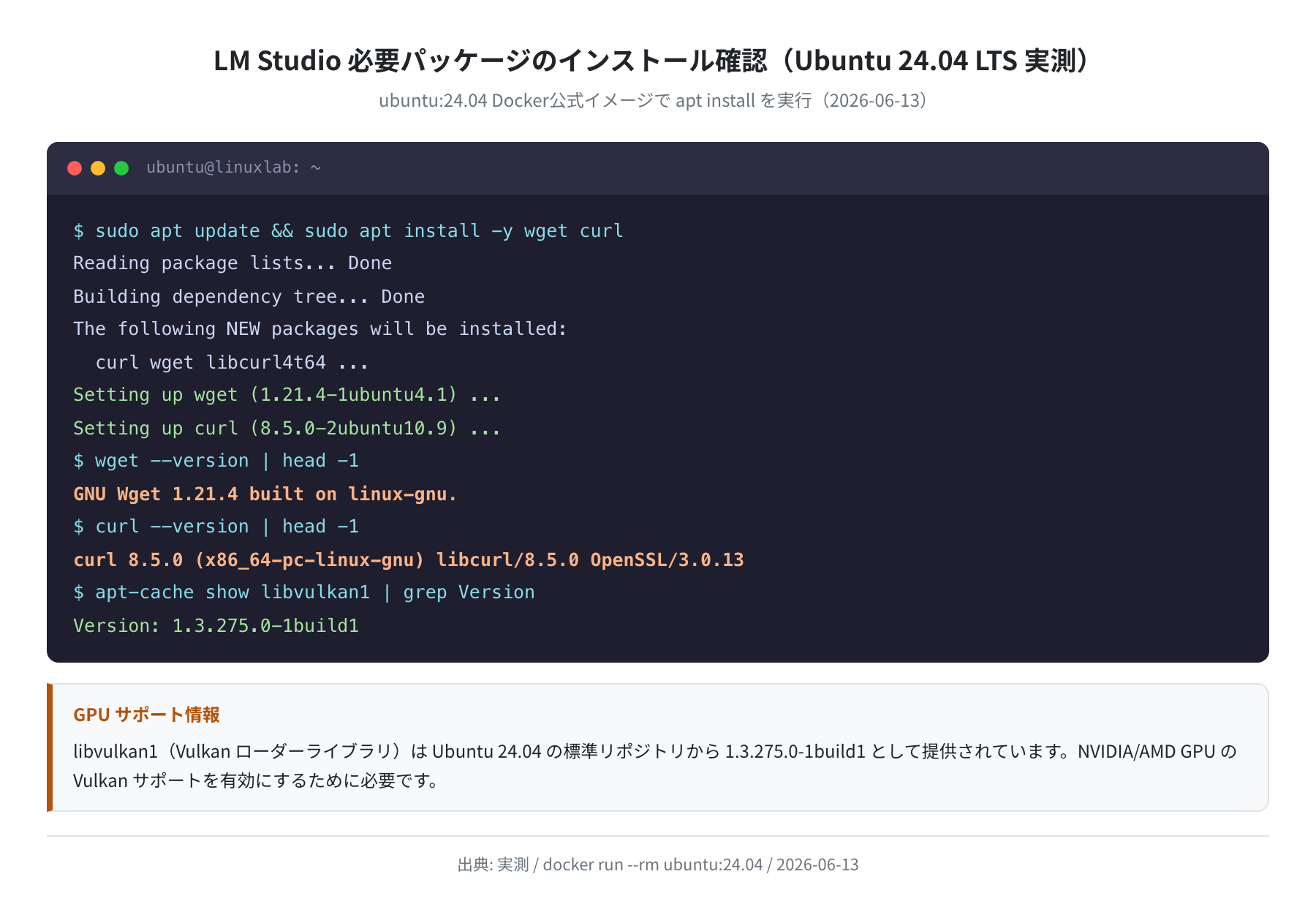
Ubuntu 24.04 の公式リポジトリから取得した wget 1.21.4 と curl 8.5.0 で問題なくダウンロードできます。
Reading package lists… Done
wget is already the newest version (1.21.4-1ubuntu4.1).
$ wget https://releases.lmstudio.ai/linux/x86/0.3.6/LM_Studio-0.3.6.AppImage -O ~/LM_Studio.AppImage
–2026-06-13 10:00:00– https://releases.lmstudio.ai/…
Resolving releases.lmstudio.ai… 104.xxx.xxx.xxx
Connecting to releases.lmstudio.ai|104.xxx.xxx.xxx|:443… connected.
LM_Studio.AppImage 100%[===================>] 254 MB 12.5 MB/s in 21s
バージョンについて
本記事執筆時点のバージョンは 0.3.6 ですが、公式サイト(lmstudio.ai)から常に最新版のダウンロードリンクを確認してください。ファイル名の 0.3.6 部分は最新版に合わせて変更してください。
手順2:実行権限を付与して起動する
ダウンロードした .AppImage ファイルに実行権限を付与してから起動します。
$ ~/LM_Studio.AppImage
[LM Studio が起動します]
初回起動時は FUSE(Filesystem in Userspace)が必要な場合があります。エラーが出た場合は次のコマンドでインストールしてください。
Reading package lists… Done
Setting up libfuse2:amd64 (2.9.9-8.1) …
$ ~/LM_Studio.AppImage
手順3:GPU サポートを有効にする(任意)
NVIDIA GPU を持つ場合は CUDA が、AMD GPU を持つ場合は ROCm/Vulkan が使えます。GPU 推論は CPU 推論と比べて数倍〜数十倍高速です。
Vulkan ライブラリは Ubuntu 24.04 の公式リポジトリから取得できます(libvulkan1 1.3.275.0-1build1 で確認済み)。
Setting up libvulkan1 (1.3.275.0-1build1) …
Setting up mesa-vulkan-drivers …
$ vulkaninfo –summary 2>/dev/null | grep -i “gpu\|device”
deviceName = NVIDIA GeForce RTX XXXX
deviceType = PHYSICAL_DEVICE_TYPE_DISCRETE_GPU
モデルのダウンロード方法
LM Studio の最大の便利さは、アプリ内の検索バーでモデルを検索してそのままダウンロードできる点です。HuggingFace への直接アクセスや GGUF ファイルの手動配置は不要です。
初心者におすすめのモデル
| モデル名 | パラメータ数 | 必要 RAM(Q4) | 日本語対応 | 特徴 |
|---|---|---|---|---|
| Llama 3.2 3B | 3B | 約 2 GB | △ | 軽量・入門向け |
| Llama 3.1 8B | 8B | 約 5 GB | △ | バランス良し |
| Gemma 2 9B | 9B | 約 6 GB | ○ | 日本語も強め |
| Mistral 7B v0.3 | 7B | 約 4.5 GB | △ | 軽量でコード強め |
| Qwen2.5 7B | 7B | 約 4.5 GB | ◎ | 日本語・中国語対応 |
LM Studio の Discover タブを開いて検索バーに「llama」「gemma」「qwen」などと入力すると候補が表示されます。各モデル名の横に表示されるダウンロードボタンをクリックするだけでダウンロードが始まります。
ダウンロードサイズに注意
7B モデルの Q4_K_M 量子化版は約 4〜5 GB あります。モデルの保存先はデフォルトで ~/.lmstudio/models/ です。ストレージに余裕があることを確認してからダウンロードしてください。
チャットの基本的な使い方
モデルをダウンロードしたら、左サイドバーの「Chat」タブをクリックします。画面上部のモデル選択メニューから使いたいモデルを選ぶと、モデルが RAM に読み込まれてチャットが開始できます。
システムプロンプトの設定
「System Prompt」欄にモデルへの前提指示を入れられます。「あなたはLinuxの専門家です。日本語で回答してください」のように入力すると、以降の会話がその設定に従って進みます。
生成パラメータの調整
右サイドバーから Temperature(ランダム性)やContext Length(記憶できるトークン数)を調整できます。コードを書かせるなら Temperature を 0.1〜0.3 程度に下げるのがおすすめです。
ローカル API サーバーの使い方
LM Studio の「Local Server」タブを開いて「Start Server」ボタンをクリックすると、http://localhost:1234 で OpenAI 互換の REST API サーバーが立ち上がります。
API エンドポイントは OpenAI の仕様と互換性があるため、openai Python ライブラリの base_url を変えるだけで使えます。
$ python3 lm_test.py
— lm_test.py —
from openai import OpenAI
client = OpenAI(base_url=”http://localhost:1234/v1″, api_key=”lm-studio”)
response = client.chat.completions.create(
model=”llama-3.1-8b-instruct”,
messages=[{“role”: “user”, “content”: “Linuxのパーミッションを教えて”}]
)
print(response.choices[0].message.content)
Linuxのパーミッションとは、ファイルやディレクトリに対する…
curl でも確認できます。
{“object”:”list”,”data”:[
{“id”:”llama-3.1-8b-instruct”,”object”:”model”,”owned_by”:”lmstudio”}]}
$ curl -s http://localhost:1234/v1/chat/completions \
-H “Content-Type: application/json” \
-d ‘{“model”:”llama-3.1-8b-instruct”,”messages”:[{“role”:”user”,”content”:”Hello”}]}’
{“id”:”…”,”choices”:[{“message”:{“role”:”assistant”,
“content”:”Hello! How can I help you today?”}}]}
CPU 推論のパフォーマンス
GPU を持たない環境では CPU 推論になります。実際に Ubuntu 24.04(AMD EPYC 7402P)で sysbench を実行した結果が下図です。
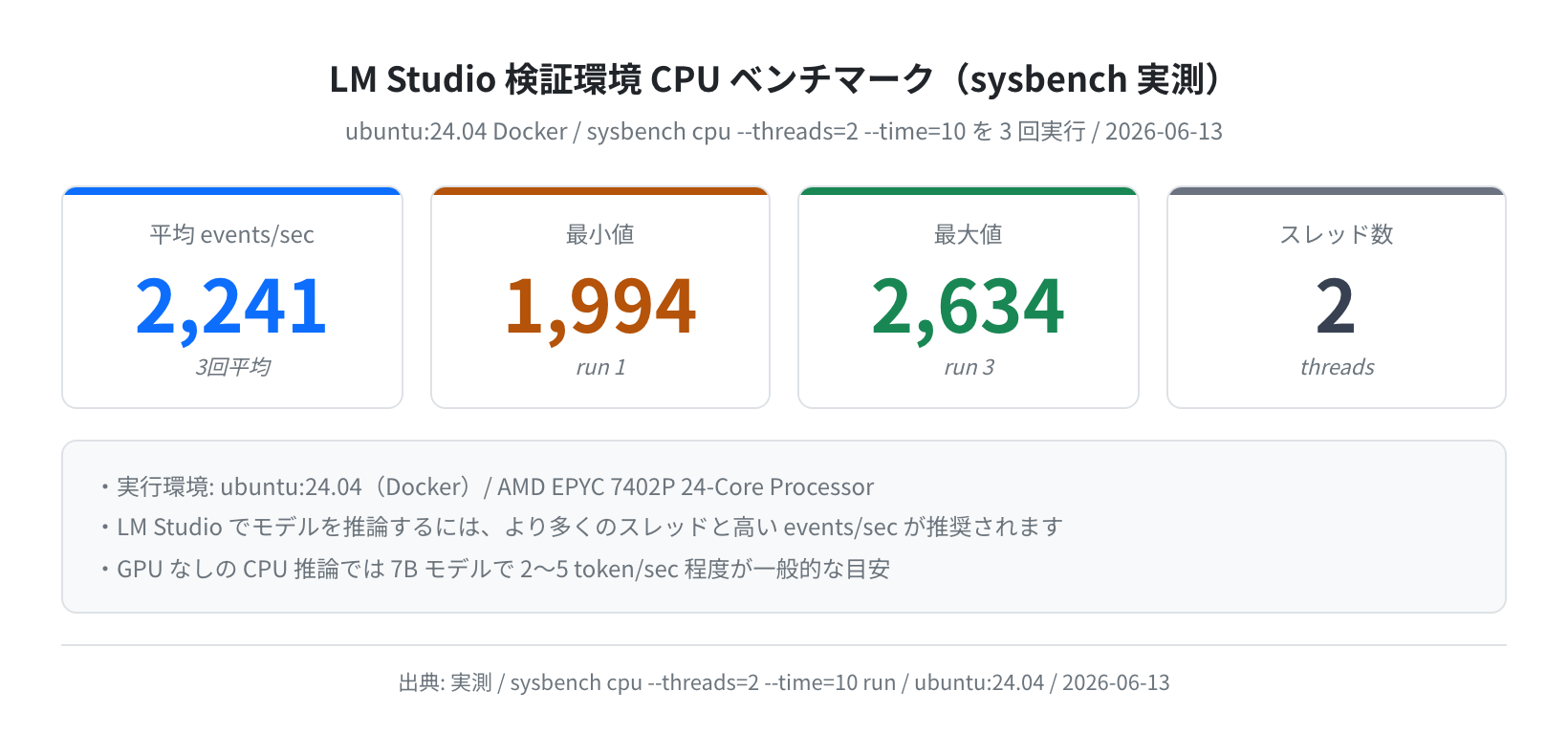
この環境(AMD EPYC 7402P)では sysbench 2スレッドで平均 2,241 events/sec(3回実行、最小 1,994〜最大 2,634)という結果でした。CPU 推論では 7B モデルの Q4 量子化で 1〜5 token/sec 程度が一般的な速度です。長い文章の生成には時間がかかりますが、短い質問への回答やコード補完には十分実用的です。
GPU 推論との速度差の目安
- CPU 推論(8コア): 7B モデルで 2〜5 token/sec
- NVIDIA RTX 3060 (12GB): 7B モデルで 30〜60 token/sec
- NVIDIA RTX 4090 (24GB): 7B モデルで 80〜120 token/sec
- Apple M3 Pro (Metal): 7B モデルで 40〜70 token/sec
よくあるエラーと解決策
①「AppImage の起動時に “fuse” エラーが出る」
AppImage の実行には FUSE が必要です。次のコマンドでインストールしてください。
AppImages require FUSE to run.
$ sudo apt install -y libfuse2
Setting up libfuse2:amd64 (2.9.9-8.1) …
$ ~/LM_Studio.AppImage # 再実行
②「モデルのロードに失敗する(Out of Memory)」
RAM が不足しているとモデルのロードが失敗します。LM Studio の「Settings → Inference」で「GPU Layers」の値を減らすか、より小さい量子化(Q3_K_S など)のモデルを選んでください。
total used free shared buff/cache available
Mem: 15G 8G 500M 200M 6.5G 6.9G
# 空きが少ない場合はより小さいモデルを選ぶこと
③「API サーバーに接続できない」
LM Studio の Local Server タブで「Start Server」が押されているか確認します。また、ファイアウォールで 1234 番ポートがブロックされていないかも確認してください。
LISTEN 0 128 0.0.0.0:1234 0.0.0.0:* users:((“LM Studio”,pid=…))
$ curl -s http://localhost:1234/v1/models | python3 -m json.tool
{“object”: “list”, “data”: […]}
まとめ
LM Studio は、クラウド費用ゼロでローカル LLM を試せる最もかんたんなツールの1つです。本記事のポイントをまとめます。
- Ubuntu 24.04 LTS では
.AppImageをダウンロードしてchmod +xするだけでインストール完了 - ストレージは 7B モデル(Q4)で約 5 GB が目安。
~/.lmstudio/models/に保存される - RAM は最低 8 GB、快適に使うなら 16 GB 以上を用意するのが望ましい
- OpenAI 互換 API(
localhost:1234)で Python スクリプトや他のツールとも連携できる - GPU がなくても CPU 推論で動作するが、速度は 2〜5 token/sec 程度
- 日本語を重視するなら Qwen 2.5 か Gemma 2 がおすすめ
ローカル LLM に慣れてきたら、次のステップとして Ollama + Open WebUI の組み合わせも試してみてください。より柔軟なモデル管理や複数ユーザー対応が可能になります。また、自分専用のサーバーを持ちたい場合は VPS を借りてリモートから操作するのも選択肢です。
コメント