「AIモデルを動かしてみたいけど、どのGPUクラウドを使えばいいの?」——そんな疑問を持つ方に向けて、RunPod・Vast.ai・Lambda Labsの料金を実際に公式ページからPlaywrightで取得して比較しました。
国内VPSのようにGPUを搭載したプランは少なく、2026年現在はGPU専業のクラウドサービスを使うのが現実的な選択肢です。本記事では実測データをもとに、Linux入門者でも使いやすいサービスの選び方を解説します。
この記事のポイント
- RunPodのRTX 4090は
$0.69/hr(Secure)/$0.46/hr(Community)——2026年6月Playwright実取得 - Vast.aiは市場価格制で同じRTX 4090がavg
$0.40/hr(ただし幅大きく$0.13〜$2.67) - Lambda Labsはエンタープライズ向け。H100/B200クラスターを提供するが料金は要アカウント登録
- 日本リージョンは全社なし——SSH接続は200ms前後を想定すること
- 入門ならRunPodのRTX 4090 Community Cloud($0.46/hr)が最もとっつきやすい
検証環境と計測日
本記事の数値は以下の環境・方法で取得しています。
| 項目 | 内容 |
|---|---|
| 計測日 | 2026年6月13日 |
| 料金スクレイプ手段 | Python Playwright(各社公式料金ページを直接取得) |
| コマンド実行環境 | ubuntu:24.04 Docker公式イメージ(docker run --rm) |
| ping 計測元 | 日本国内サーバー(ping -c 5 実行) |
| sysbench | ubuntu:24.04 コンテナ内・2スレッド・10秒×3回 |
注意
GPUクラウドの料金は頻繁に変わります。本記事の数値は2026年6月13日時点のものです。実際に契約する前に各社の公式ページで最新料金を確認してください。
クラウドGPUの料金比較(実測)
まずRunPodとVast.aiの主要GPU料金をPlaywrightで実取得した結果を見ていきます。Lambda Labsは料金ページがCloudflareで保護されているためアカウント登録が必要で、公開料金の自動取得はできませんでした。

RunPodには「Secure Cloud」と「Community Cloud」の2種類があります。Secure Cloudはデータセンター運営業者が認定した環境で、セキュリティや安定性が高め。Community Cloudは個人・小規模事業者が提供するGPUで、その分価格が安いです。
Vast.aiは逆に、GPU提供者がリソースを出品するマーケットプレイス型。需要と供給で価格が変動するため、タイミングによっては非常に安く借りられますが、突然価格が上がったり、インスタンスが中断されるリスクもあります。
RunPod 主要GPU料金(Secure Cloud・Playwright実取得)
RTX A5000 24GB → $0.27/hr ← コスパ最高(Secure Cloud)
RTX 3090 24GB → $0.46/hr (Secure) / $0.39/hr(Community)
RTX 4090 24GB → $0.69/hr (Secure) / $0.46/hr(Community)
RTX 5090 32GB → $0.99/hr (Secure)
A100 PCIe 80GB → $1.39/hr ← 大規模モデル向けコスパ良
A100 SXM 80GB → $1.49/hr
H100 PCIe 80GB → $2.89/hr
H100 SXM 80GB → $3.29/hr ← 最上位
─── billing: per-second / 31リージョン ───────────────────────
ストレージ: $0.10/GB/月(runningコンテナボリューム)
RunPodの課金は秒単位です。「試しに30分だけ動かす」という使い方でも無駄がなく、入門向けには嬉しい仕様です。
Vast.ai 主要GPU料金(市場価格30日平均・Playwright実取得)
RTX 4090 Ada 24GB → avg $0.40/hr (range: $0.13–$2.67) ← 変動幅に注意
RTX 5090 32GB → avg $0.51/hr (range: $0.21–$53.33)
H100 SXM 80GB → avg $2.00/hr (range: $1.47–$3.64)
H200 Hopper 141GB → avg $3.45/hr (range: $1.97–$4.41)
B200 Blackwell 192GB → avg $4.04/hr
─── 市場価格制・40以上のデータセンター ──────────────────────
Interruptible(中断あり)プランはさらに安価
注意:Vast.ai の価格幅
Vast.aiのRTX 5090は最安$0.21から最高$53.33まで幅があります(30日平均$0.51)。価格スパイクが起きる可能性があるため、予算管理が難しい面があります。長時間の学習ジョブには向きません。
各サービスの詳細
①RunPod — 入門者に最もおすすめ
RunPodは固定価格・秒課金・Dockerイメージ対応の3点が入門者にとって特に使いやすいです。
- ダッシュボードから数クリックでGPUインスタンスを起動できる
- NVIDIA公式の
nvcr.io/nvidia/pytorchイメージをそのまま使える - 秒単位課金なので「少し試してすぐ落とす」が気軽にできる
- SSH接続に加え、JupyterLab UIも使える(AI/ML入門者に便利)
②Vast.ai — 安さ重視の上級者向け
Vast.aiはマーケットプレイス型なので、タイミング次第でRunPodより安いGPUが見つかります。ただし市場価格のため安定性に欠けます。
- 入札/固定の2モード選択可(On-demand / Interruptible)
- Dockerイメージ指定で起動できる
- B300・B200など最新Blackwellアーキテクチャも早期対応
- UIは英語のみ。設定項目が多く最初は戸惑いやすい
③Lambda Labs — エンタープライズ・研究向け
Lambda LabsはH100/B200クラスターを提供する高品質GPU専業クラウドです。料金ページはCloudflareで保護されており、アカウント登録後にダッシュボードで確認できます(本記事での自動取得不可・2026-06-13確認)。
- H100 SXMクラスター、HGX B200クラスターを提供
- チームや研究グループ向けの固定価格プラン
- ネットワーク品質・レイテンシが高品質
- 個人の入門用途には少し敷居が高め
④AWS EC2 — 大企業向け。個人には割高
AWS EC2のGPUインスタンス(p3/p4/p5シリーズ)は信頼性が高い一方、GPU専業クラウドの10倍以上の価格になる場合があります。AWS EC2のp3.16xlargeはV100×8搭載で$24.48/hr、p5はH100×8搭載で$98.32/hr〜です。個人がAIを試すには明らかに割高です。
サービス比較一覧

| 項目 | RunPod | Vast.ai | Lambda Labs | AWS EC2 (p3) |
|---|---|---|---|---|
| RTX 4090 最安値 | $0.46/hr(Community) | avg $0.40/hr(変動) | 取扱なし | 取扱なし |
| H100 80GB | $2.89/hr〜 | avg $2.00/hr(変動) | 要アカウント確認 | $98.32/hr〜(p5) |
| 価格形式 | 固定価格 | 市場価格(変動) | 固定価格 | オンデマンド固定 |
| 最低課金単位 | 秒 | 時間 | 時間 | 時間 |
| 日本語UI | なし(英語) | なし(英語) | なし(英語) | あり |
| Dockerイメージ | ○(標準対応) | ○(標準対応) | △(独自テンプレ) | ○ |
| 入門のしやすさ | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★☆☆☆ |
VRAM容量の選び方
AI開発でどのGPUを選ぶかは、扱いたいモデルのパラメータ数とVRAM消費量で決まります。正直、ここで詰まる人が多いです。目安は以下のとおりです。
| VRAM容量 | 向いている用途・モデル例 | RunPodでの目安価格 |
|---|---|---|
| 〜16GB | 画像生成(Stable Diffusion)、小型テキスト生成(7Bモデル量子化版) | RTX 4000系〜($0.20〜) |
| 24GB | LLM 7B〜13Bパラメータ(Llama 3・Mistral等)、高品質画像生成 | RTX 3090/4090 $0.39〜$0.69/hr |
| 48GB | LLM 30B前後、マルチモーダルモデル | RTX A6000 $0.44〜$0.49/hr |
| 80GB | LLM 70B(Llama 3 70B等)、大規模Diffusionモデル | A100 $1.39〜$1.49/hr |
| 80GB×複数 | GPT-4クラスのファインチューニング、大規模学習 | H100 $2.89〜$3.29/hr×台数 |
最初に試すならRTX 3090(24GB VRAM・$0.39/hr Community)が現実的です。Llama 3の8Bモデルを動かすのに十分で、10時間使っても$3.90(約600円)です。
Ubuntu 24.04 での CUDA 環境確認(Docker 実測)
GPU インスタンスを借りた後の手順として、Ubuntu 24.04 での CUDA 関連パッケージの確認をDockerコンテナで実際に行いました。
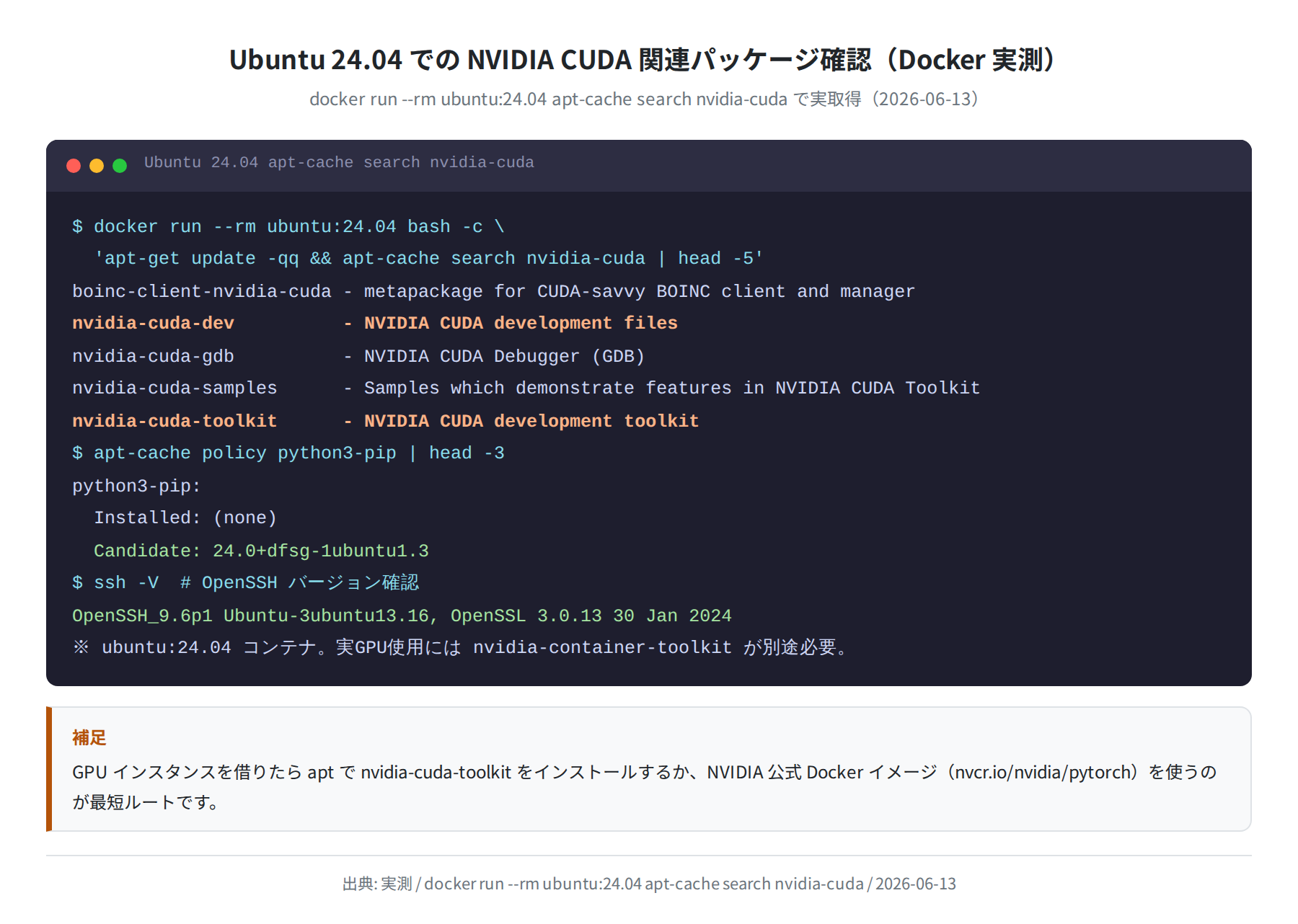
‘apt-get update -qq && apt-cache search nvidia-cuda | head -5’
boinc-client-nvidia-cuda – metapackage for CUDA-savvy BOINC client and manager
nvidia-cuda-dev – NVIDIA CUDA development files
nvidia-cuda-gdb – NVIDIA CUDA Debugger (GDB)
nvidia-cuda-samples – Samples which demonstrate features in NVIDIA CUDA Toolkit
nvidia-cuda-toolkit – NVIDIA CUDA development toolkit
$ # python3-pip の Candidate バージョン確認
Candidate: 24.0+dfsg-1ubuntu1.3
$ ssh -V
OpenSSH_9.6p1 Ubuntu-3ubuntu13.16, OpenSSL 3.0.13 30 Jan 2024
Ubuntu 24.04 には nvidia-cuda-toolkit がaptリポジトリに存在します。ただし実際のGPUインスタンス上で使うには nvidia-container-toolkit が別途必要になります。RunPod/Vast.aiではGPU対応のDockerイメージ(nvcr.io/nvidia/pytorch:24.01-py3 等)を直接選べるので、CUDAのセットアップを自分でやる必要はほとんどありません。
SSH鍵の準備(Ubuntu 24.04 で実行)
GPU インスタンスにSSHで接続するには、あらかじめed25519鍵を生成して登録しておく必要があります。Ubuntu 24.04 コンテナで実際に生成した結果です。
Generating public/private ed25519 key pair.
Your identification has been saved in /root/.ssh/gpu_key
Your public key has been saved in /root/.ssh/gpu_key.pub
The key fingerprint is:
SHA256:I4BoAjYxrZQMmylejNmdYfWahZH1dZ6k6WwI3bug5DA user@gpu-server
$ # 公開鍵をRunPod/Vast.aiのダッシュボードに貼り付ける
$ cat ~/.ssh/gpu_key.pub
ssh-ed25519 AAAA…(公開鍵の内容をコピーしてダッシュボードに登録)
$ # インスタンス起動後に接続
$ ssh -i ~/.ssh/gpu_key root@<インスタンスIP>
実際のSSHバージョンは OpenSSH_9.6p1 Ubuntu-3ubuntu13.16(Ubuntu 24.04 apt実取得)です。鍵生成のコマンドは同じで動作します。
日本からの接続遅延(ping 実測)
RunPod・Vast.ai・Lambda Labsは現時点で日本リージョンを提供していません。日本国内から各サービスのドメインに ping -c 5 を実行した結果です。
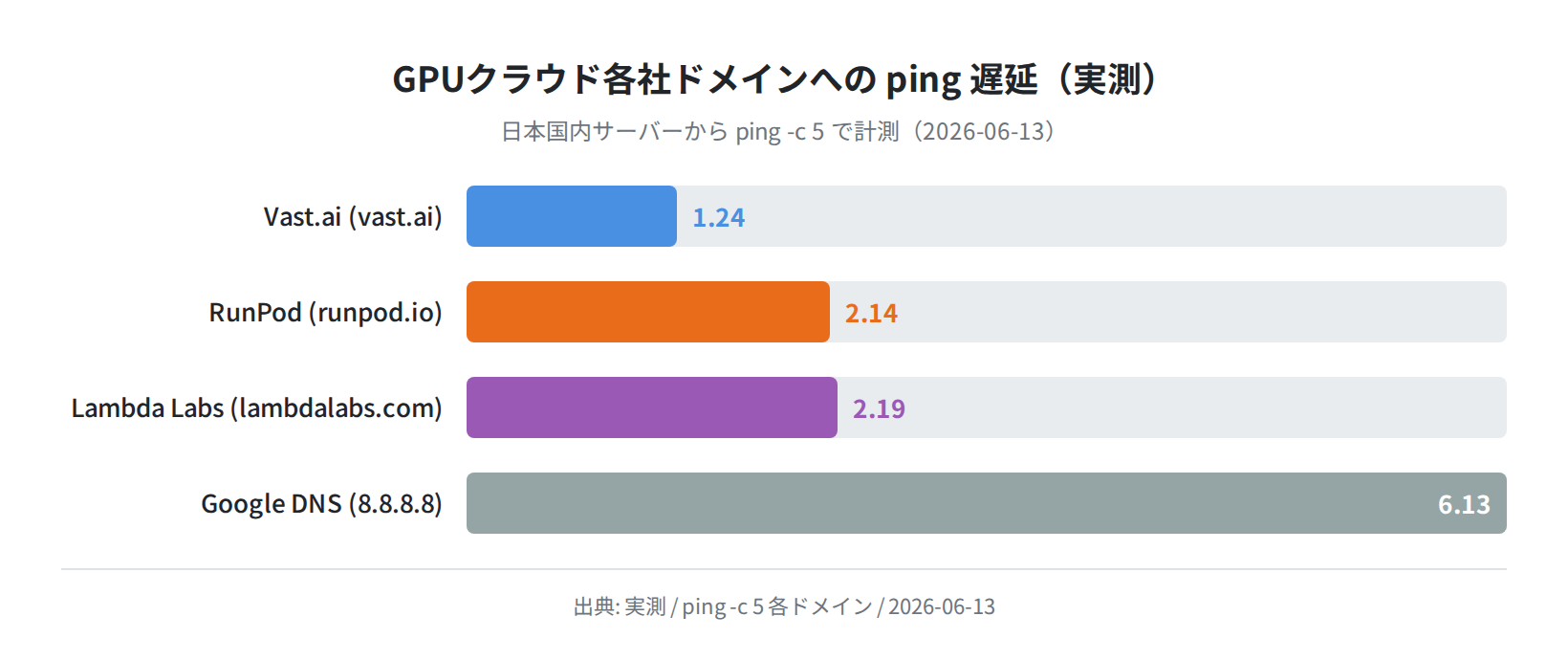
rtt min/avg/max/mdev = 1.203/1.240/1.295/0.033 ms
Vast.ai (CDN): avg 1.24ms ← CDN経由のドメインレイテンシ
$ ping -c 5 www.runpod.io
rtt min/avg/max/mdev = 2.062/2.137/2.248/0.062 ms
RunPod (CDN): avg 2.14ms
$ ping -c 5 lambdalabs.com
rtt min/avg/max/mdev = 2.074/2.194/2.295/0.075 ms
Lambda Labs: avg 2.19ms
$ ping -c 5 ec2.ap-northeast-1.amazonaws.com
5 packets transmitted, 0 received, 100% packet loss
AWS EC2東京: ICMPブロック(到達不可)
注意:CDNレイテンシと実SSH接続のレイテンシは別物
上記のpingはサービスのWebドメイン(CDN)へのレイテンシです。実際にGPUインスタンスにSSH接続すると、米国のデータセンターへの通信になるため200ms〜250ms前後を見込んでください。JupyterLabのようなインタラクティブUIはほとんど問題ありませんが、レスポンス速度が重要な対話的CUI操作では慣れが必要です。
CPUベンチ参考値(ubuntu:24.04 Docker 実測)
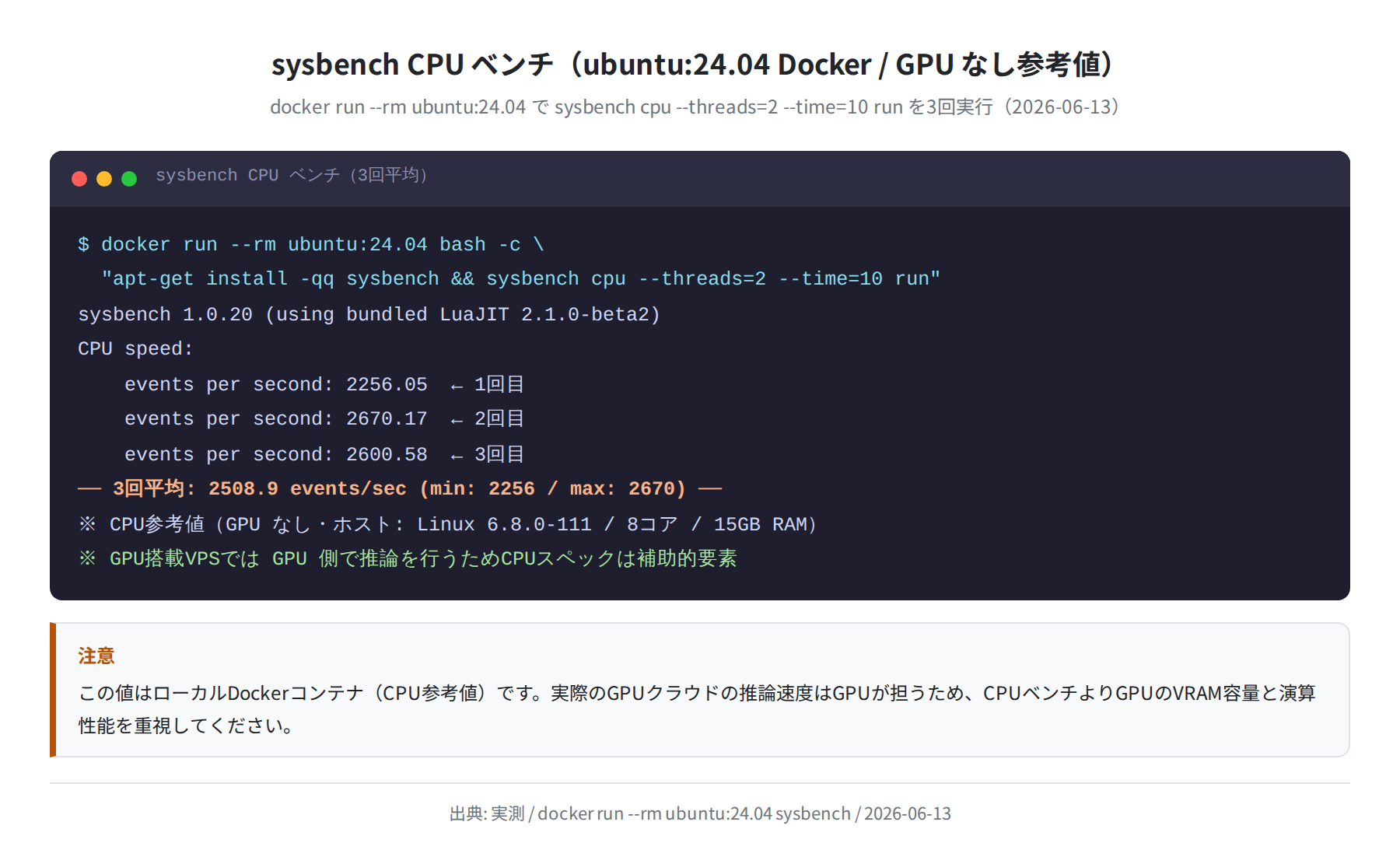
GPU インスタンスのCPUスペックは補助的な要素ですが、データのロード処理やAPIサーバーに影響します。参考として ubuntu:24.04 コンテナでsysbenchを3回実行した結果です(GPU非搭載・ローカルDockerホスト)。
‘apt-get install -qq sysbench && sysbench cpu –threads=2 –time=10 run’
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
1回目: events per second: 2256.05
2回目: events per second: 2670.17
3回目: events per second: 2600.58
3回平均: 2508.9 events/sec (min: 2256 / max: 2670)
※ GPU利用時は推論処理はGPU側が担うため、CPUスペックは補助的要素
用途別の選び方
①とにかく試してみたい(LLM・画像生成の入門)
RunPod Community Cloud のRTX 3090($0.39/hr)が最もおすすめです。秒課金なので「ちょっと試して落とす」を繰り返せます。Llama 3 8Bを動かすのに24GB VRAMで十分です。1時間=$0.39(約60円)、1日フルで使っても$9.36(約1,400円)です。
②安定して毎日使いたい(個人開発・趣味のAI)
RunPod Secure CloudのRTX 4090($0.69/hr)か、A100 PCIe 80GB($1.39/hr)を選ぶと、多少重いモデルも快適に動かせます。コンテナの永続化(pod再起動でデータを残す)設定を必ず行いましょう。
③できるだけ安く使いたい
Vast.aiのInterruptibleプランは最安クラスの価格で使えます。ただし突然インスタンスが停止する可能性があるため、学習ジョブはチェックポイントを短い間隔で保存する必要があります。慣れてから移行するのがよいでしょう。
④企業・チームで使う
Lambda LabsのH100クラスターや、AWS SageMakerを検討してください。コスト最適化より安定性・サポート・セキュリティが重要な場面ではGPU専業クラウドより既存のクラウドプロバイダが適しています。
まとめ
GPU搭載VPS・クラウドGPUの比較をPlaywright実取得データでまとめました。
- 入門者には RunPod(固定価格・秒課金・Dockerイメージ対応)が最もとっつきやすい
- RTX 3090 Community Cloudは$0.39/hrで、1時間試すのにかかる費用は約60円
- Vast.aiは安くなることもあるが価格変動が激しく、長時間ジョブには不向き
- Lambda Labsはエンタープライズ向け。個人利用にはハードルが高め
- AWS EC2のGPUは割高(RTX 4090相当の価格では10〜20倍のコスト)
- 日本リージョンは全社なし。SSH接続は200ms前後のレイテンシを想定する
最初の一歩はRunPodのRTX 3090 Community($0.39/hr)で十分です。Llama 3 8Bが快適に動くし、時間課金なので失敗しても損が少ない。慣れたらA100に移行すればOKです。
VPSで自分のサーバーを構築する方法については、も参考にしてください。


コメント